AWSスポットインスタンスとは。その設定方法と使い方のアイデア
スポットインスタンスとは何か
AWSの余剰リソースを割安で貸してくれるもの、余剰じゃなくなると通知と供に問答無用で使えなくなる事もある。これは大体EC2かECSで利用するものであるが、まずは解説するのに手っとり早いのでEC2で解説してみる事にする。
EC2でスポットインスタンスを使うには
ここでは普通に起動する画面でポイポイ設定していく。ここでARMのt4g.microを使うとしよう、別にx86でもいいが。なお、現在のchatgptはこの辺の情報が甘くARMではスポットインスタンス使えない事もあるとか言ってきたりもしてて結構あやうい。これは知らない事は知らない中でベストを尽くすのがAIの設計なので仕方ないね。
諸々セットしたら、ここから「高度な詳細」を押して設定を引きずりだすのを忘れないように。なお

ここでスポットリクエストを設定できる。ここで選択するとdefaultでなく
「スポットインスタンスオプションのカスタマイズ」
というのが現れるので、これを開くと

最高料金リクエストタイプ有効期間終了中断動作
という4つのオプションがセットできる。これを適当にすると結構泣きを見るかもしれないので注意してセットしていこう
最高料金
これは「この値段以下のみ起動する」というオプションでそれ以上の値段のリソースがみつからないとうまいこといかないんだろうと思うし、値段が上がってくるとまったきにリクエストが終わっちゃうんだろうと思う。したがってここをセットするのはかなり上級者的な使い方となるだろう(よほどハイスペックのインスタンスを安く使ってチギっては投げしたいとか...)。オンデマンドの起動料金より上がる事はほぼほぼありえないので、ここの設定に関しては基本的に無視してよいはずだ。
この記事では特に用途を絞って戦略的にやるという趣旨ではないので、ここでは値を設定しない(最高料金なし)
リクエストタイプ
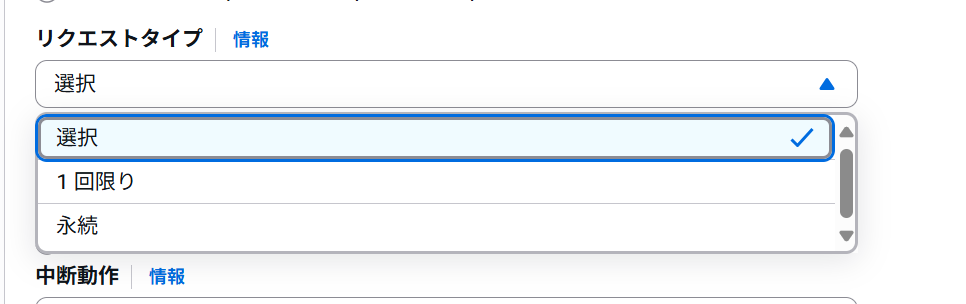
リクエストが終わった(打ち切られた)時の「クライアントのリクエストの」動作をセットする。先述した通りAWSの余剰リソースが無くなるとリクエストは打ち切られるのだが、この後にこのリクエストがどうなるかをここで設定する。(そもそも空きがなくて起動すらできないときもあるのだから、前提が打ちきられた時かどうかは限らない)
とにかくリクエストが潰えた時に、さっさと諦めるのか、あるいは、再度リクエストを出しつづけて空きが出るまで粘るのかをここでセットするというわけだ。
有効期間終了
これはリクエストタイプを粘るようにした場合、いつまで粘りつづけるのかということだろう、まあ基本的に高度な設定となるはずで、使いこなせるなら使うという形になるだろうか。ここではセットしない
中断動作
これが一番ヤバい
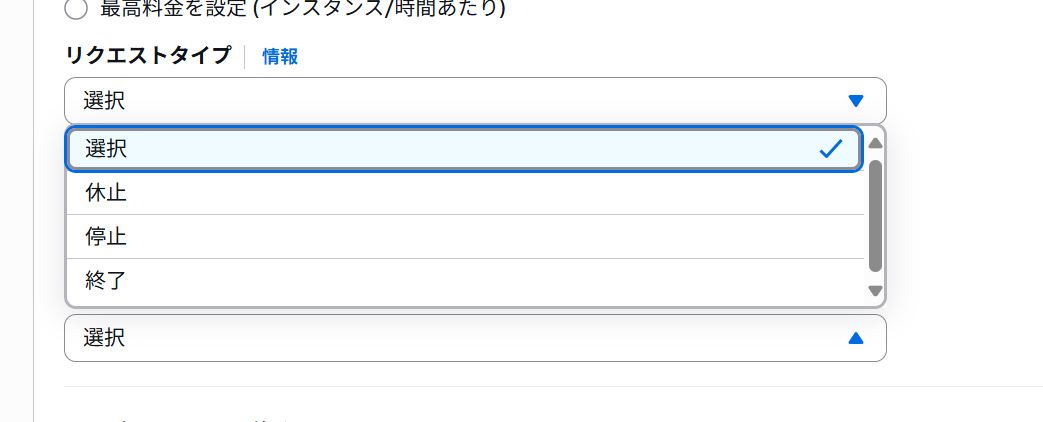
まず、「休止」は分ってる人だけ使う事。ここでは「終了」と「停止」だけ見る事にするとして、そもそもデフォルトは終了なのである。つまりEC2は基本的にAWSリソースが尽きて「停止しろ」信号が出てしまうとインスタンスが消滅する。これはたとえばEC2のルートファイルシステムのEBSで適当に作業するとそのデーターがまるごと昇天する事すらあるので(デフォルトの動作はそうなっているだろう)気をつけて運用しないといけない
それを踏まえて、まるごと終了していいのか、それともそれはマズいのかを選択する。適当な開発環境が欲しいとかの場合、「停止」にしておくと安心できるかもしれない。
ただし、繰り返すが、本当は終了してもuserdataとかで新規立ち上げのとき環境を復活できるようにしておくのがよいのだけど...
ユースケース
スポットインスタンスで開発する
このような場合もデーター領域のボリュームをmountして開発するのがよいだろう。ルートボリュームで開発しててツリーごとすっとんだとかなると泣くしかない。
で、AWSリソースが尽きて停止指令が出た場合は待ちになるので、永続にして再開するのを期待するのがこのケースにおいて、おそらく正しい使い方になる。「停止」か「終了」かは「終了」にすると再度環境を構築するのが面倒な事もあるだろうから、このケースにおいては「停止」にしといた方がいいんじゃないですかね?
スポットインスタンスでバッチ処理する
EC2を起動し、何かしらのバッチ処理をして死ぬパターン。死ぬ作業は自分で書かないといけないが、ある程度生きてても死んでてもいい的なEC2を普通に起動しているのは勿体ないという時など。しかしこのケースは本来はECS Fargateタスクの方が向いているだろうけど、面倒な場合には使えそうですかね。
バッチ処理する場合はインスタンスサイズがデカめの奴で行なうと相当効いてくるので思いきった設定をしておいてもいいのかもしれない。これはFargateになってもそうだろう。
壊れてもいいテスト/ステージング環境
何となく客に見せるとか、停止してても「あ、うごいてねっすね、起動してみます」みたいなノリで許されるようなやつ。まあ時々こういう要件もあるでしょう?でも、この場合も「停止」してるならまだしも「終了」して1から環境作らなきゃいけなくなって真っ青とかならないような配慮は必要だとは思いますよ。
高度に設計された準プロダクション環境
そもそも壊れていいものをプロダクションとは呼べないので、壊れないようにするにはどうするかということだけど、基本的にリソースはAZ単位で制限されるので
ap-northeast-1aap-northeast-1c
とかにそれぞれEC2を配置したりしてどっちか死んでも生きてるみたいな環境が作れるなら、まあまあ使える環境となるはずだ。でもこれをEC2でやるのはなかなか面倒くせえのでECSを考えた方がマシかも...ECSにもspotはあります。
実行してみた例

t4g.nanoは起動したものの自分で停止したものだ、必要のなくなったリクエストはキャンセルしておくに限る

停止ログ
これは基本的にはCloudTrailを見るしかないっすね。たとえば上の画像で14日動作させてるのがあるのだけど、上のリストからは全く起動/停止状態は取れない。
CloudTrailからは

こんな感じで見ることができる。ここでは停止、復帰、停止、復帰したような形跡になってますね。停止でフィルターしてるので停止しか見えてないけど、おそらくそうなんでしょう。
停止通知
これはOSレベルで見て、処理したいなら処理する必要がある。
ここでは
TOKEN=`curl -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"` \
&& curl -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/spot/instance-action
というスクリプトが示されているが、すなわちこのurlを自分で見ておかないとまったく通知されないということである。ただ、外部にslackで送ったりしても自動復帰した場合ログで埋まっちゃうこともあるから、これを取ってなんか良いことがあるのかは運用次第だろう。たとえばテスト環境で落ちるまで粘ってやるとかいう感じの奴で、いつ落ちたかを通知したりして使うとか。
まとめ
使いこなせるならかなり安くなるという、ある意味AWS使いの腕の見せ所が凝縮したような仕組みではある。プロダクションで使う場合経験に左右されすぎるので壊れてもいいものというのが思い浮かぶなら使って経験値を稼いでおくのも手である。
開発環境(devコンテナーとか)も結構おすすめなんだけど、前にも書いたようにgit push前のリポジトリーごと昇天とかすると本当に目もあてられないのでそういう経験して(しなくてもいいけど)さらに強くなるとかを目指すならやってもよい。
「事故っても構わん」か「事故って学ぶぞ」という覚悟があるならぜひ。
クリティカルミッションに関してはやっぱりオンデマンドにしといた方がいいと思いますよ。私は開発用とバージョンアップとか、クリーンな環境で動くかとかの検証用で使ってます。
最後に
オンデマンド違って、インスタンスタイプを簡単に変更できないので気をつけてくださいね。基本的には作り直しになります。
あと、安くなるのは当然インスタンス部分だけでボリュームとかは普通に課金されるので、容量を多めに取ると思った程安くならないなあという事もあるかもしれないです。開発で使う場合はsmall以上は欲しいので、こういう場合には効いてくるかな。インスタンスが割引されるので当然サイズがでかい方が恩恵を得られるということになるでしょう。
Discussion