お疲れ様です!株式会社 CastingONEで働いてる岡本です!
最近業務でバックエンド開発をやらせもらっているのですが、PostgreSQLでWITH RECURSIVE句を使って再帰的なクエリを書く機会があったので、何個か例を用いながら、自分の理解を深めるためにまとめてみたいと思います!
WITH RECURSIVE句とは
実世界のデータは組織図、フォルダ構造、商品カテゴリのような「親子関係」や「連鎖的な関係」を持つことがよくあります。こういった複雑な構造を単純なSQLで取り出そうとすると、クエリが何重にもネストしてしまって複雑になりがちです。そこで役立つのが WITH RECURSIVE句 です。
WITH RECURSIVE句は再帰的クエリを実行するための機能で、自分自身の結果を参照しながら繰り返し処理を行うことができます。イメージとしては「自分の結果を使って、さらに次の結果を求める」という感じです。
基本構文
基本的な構文は以下のようになります。
WITH RECURSIVE 再帰クエリ名 AS (
-- 初期クエリ(スタート地点)
SELECT カラム FROM テーブル WHERE 条件
UNION [ALL] -- ここで初期クエリと再帰クエリの結果を結合
-- 再帰クエリ(繰り返し部分)
SELECT カラム FROM テーブル
JOIN 再帰クエリ名 ON 結合条件
WHERE 終了条件
)
SEARCH {DEPTH | BREADTH} FIRST BY カラム名[, ...] SET 順序カラム -- 探索順序の指定と記録
CYCLE カラム名 SET 循環フラグ USING パス -- 循環検出
SELECT * FROM 再帰クエリ名;
UNIONとUNION ALLの違い
再帰クエリではUNION ALLとUNIONのどちらかを選ぶ必要があります。
-
UNION ALL: 全ての行を保持し、重複チェックをしません。パフォーマンスが良く、多くの再帰クエリで使われます。 -
UNION: 重複行を除外します。重複除去のための追加処理が必要なため、パフォーマンスコストが高くなります。
多くの場合はUNION ALLを使いますが、循環参照の可能性がある場合は終了条件を明確に設定するか、PostgreSQL14以降で追加されたCYCLE句を使って循環検出を行うことができます。
SEARCH句について
SEARCH句は再帰クエリの探索順序を指定するための機能です。DEPTH FIRSTまたはBREADTH FIRSTで探索方法を指定し、BY句で探索順序を指定することができます。SET句で探索順序を記録するカラムを指定します。このカラムが暗黙的にCTEの出力行に暗黙的に追加されます。
CYCLE句について
CYCLE句は再帰クエリ内の循環参照を簡単に検出するための機能です。
例えば、組織図で部門A -> 部門B -> 部門C -> 部門Aという循環参照があった場合、これを自動的に検出してくれます。
最初にサイクル検出のために追跡する列のリストを指定(カラム名)し、次にサイクルが検出されたかどうかを示す列名(循環フラグ)、最後にパスを追跡する別の列の名前(パス)を指定します。 サイクル列とパス列は、CTEの出力行に暗黙的に追加されます。
簡単な例
組織階層図を例にして、再帰的クエリを使って取得してみましょう。
テーブル定義
departmentsテーブル
| id | name | parent_id |
|---|---|---|
| 1 | 人事部 | NULL |
| 2 | 開発本部 | NULL |
| 3 | バックエンド開発部 | 2 |
| 4 | フロントエンド開発部 | 2 |
| 5 | APIチーム | 3 |
| 6 | UIチーム | 4 |
クエリ
この組織図を階層的に取得するには次のようなクエリを書きます。
WITH RECURSIVE
department_hierarchy AS (
-- 初期クエリ:親を持たないトップレベルの部門
SELECT
id,
name,
1 AS level,
name AS path
FROM
departments
WHERE
parent_id IS NULL
UNION ALL
-- 再帰クエリ:子部門を取得
SELECT
d.id,
d.name,
dh.level + 1,
dh.path || ' > ' || d.name
FROM
departments d
JOIN department_hierarchy dh ON d.parent_id = dh.id
)
-- 探索順序を記録
SEARCH DEPTH FIRST BY id SET ordercol
-- 循環参照を検出
CYCLE id SET is_cycle USING id_path
-- 結果出力
SELECT * FROM department_hierarchy ORDER BY ordercol;
まず、初期クエリで親部門を持たないトップレベルの部門、すなわちparent_idがNULLの部門を取得します。次に再帰クエリの部分で、departmentsテーブルとCTEのdepartment_hierarchyを結合して、子部門を取得します。それをUNION ALLで結合して、再帰的に部門を取得していきます。
実行結果
上のクエリを実行すると、以下のような結果が取得できます。
| id | name | level | path | ordercol | is_cycle | id_path |
|---|---|---|---|---|---|---|
| 1 | 人事部 | 1 | 人事部 | [('1',)] | False | [('1',)] |
| 2 | 開発本部 | 1 | 開発本部 | [('2',)] | False | [('2',)] |
| 3 | バックエンド開発部 | 2 | 開発本部 > バックエンド開発部 | [('2',), ('3',)] | False | [('2',), ('3',)] |
| 5 | APIチーム | 3 | 開発本部 > バックエンド開発部 > APIチーム | [('2',), ('3',), ('5',)] | False | [('2',), ('3',), ('5',)] |
| 4 | フロントエンド開発部 | 2 | 開発本部 > フロントエンド開発部 | [('2',), ('4',)] | False | [('2',), ('4',)] |
| 6 | UIチーム | 3 | 開発本部 > フロントエンド開発部 > UIチーム | [('2',), ('4',), ('6',)] | False | [('2',), ('4',), ('6',)] |
ordercolはSEARCH句で指定した探索順序を記録したカラム、is_cycleとid_pathはCYCLE句で指定した循環参照を検出するためのカラムです。is_cycleは循環参照がある場合にTrue、ない場合にFalseが入ります。id_pathは循環検出のために追跡する列のリストを示しています。
ordercolとid_pathは同じような情報を持っているように見えますが、「同じ情報を異なる目的で2回記録している」というのが正しい理解です。ソートにはordercolを使い、循環検出にはid_pathを使います。
WITH RECURSIVE句の基本的な使い方はこのようになります!
具体的な活用例: 材料から料理への連鎖を追跡する
では次に実際に私が業務で実装したような再帰クエリの例を紹介します!実務の内容をそのまま載せることはできないので、ここではわかりやすく似たようなシナリオの「材料と料理の連鎖」という題材に置き換え説明します!
皆さんも料理をしていて、例えば「余ったカレーでカレーうどんを作ろう!」というような経験があるかと思います。このように、材料 -> 料理 -> 料理の余りものを材料に -> さらに料理... というような連鎖を追跡することができる再帰クエリを書いてみましょう!
テーブル定義
必要なテーブル群を以下のように定義します。
ingredients(材料)テーブル
| id | name |
|---|---|
| 1 | 味噌 |
| 101 | カレールー |
| 102 | カレー |
| 103 | うどん |
recipes(料理)テーブル
| id | name |
|---|---|
| 1 | 味噌汁 |
| 101 | カレーライス |
| 102 | カレーうどん |
| 103 | お好み焼き |
ingredient_purchases(材料購入)テーブル
| id | ingredient_id | purchase_date |
|---|---|---|
| 1 | 1(味噌) | 2020-01-01 |
| 2 | 101(カレールー) | 2020-02-01 |
ingredient_to_recipe_logs(材料から料理にした履歴)テーブル
この材料を使って、この料理を作ったというログを保存するテーブルです。
| id | ingredient_id | recipe_id |
|---|---|---|
| 1 | 1(味噌) | 1(味噌汁) |
| 2 | 101(カレールー) | 101(カレーライス) |
| 3 | 102(カレー) | 102(カレーうどん) |
| 4 | 103(うどん) | 103(お好み焼き) |
recipe_to_ingredient_logs(料理から材料にした履歴)テーブル
余った料理を、材料に戻すというログを保存するテーブルです。
| id | recipe_id | ingredient_id |
|---|---|---|
| 1 | 101(カレーライス) | 102(カレー) |
| 2 | 102(カレーうどん) | 103(うどん) |
以上のテーブルを用意し、購入した材料が最終的にどの料理に成ったかを再帰的クエリで取得してみましょう!
クエリ
WITH RECURSIVE
recipe_finder AS (
-- 初期クエリ
SELECT
ip.id purchase_id,
ip.ingredient_id ingredient_id,
itr.recipe_id recipe_id,
r.name
FROM
ingredient_purchases ip
JOIN ingredient_to_recipe_logs itr ON ip.ingredient_id = itr.ingredient_id
JOIN recipes r ON itr.recipe_id = r.id
-- 初期クエリの結果と再帰クエリの結果を結合
UNION ALL
-- 再帰部分
SELECT
rf.purchase_id,
itr.ingredient_id,
itr.recipe_id,
r.name
FROM
recipe_to_ingredient_logs rti
JOIN ingredient_to_recipe_logs itr ON rti.ingredient_id = itr.ingredient_id
JOIN recipes r ON r.id = itr.recipe_id
JOIN recipe_finder rf ON rf.recipe_id = rti.recipe_id
)
-- 探索順序を記録
SEARCH DEPTH FIRST BY recipe_id SET ordercol
-- 循環参照を検出
CYCLE recipe_id SET is_cycle USING path,
-- 各purchase_idごとに最も深い階層のレコードを取得するサブクエリ
latest_recipes AS (
SELECT DISTINCT
ON (purchase_id) purchase_id,
ingredient_id,
recipe_id,
name,
ordercol,
is_cycle,
path
FROM
recipe_finder
ORDER BY
purchase_id,
ordercol DESC
)
SELECT * FROM latest_recipes ORDER BY purchase_id;
流れとしては以下のようになります。
- 購入した材料を起点として、その材料から作った料理を初期クエリで取得
-
ingredient_purchasesテーブルから購入した材料の情報を取得 -
ingredient_to_recipe_logsテーブルを結合して、その材料から実際に作られた料理を特定 -
recipesテーブルを結合して、料理名を取得
- 再帰部分では、前のステップの料理から派生した新たな材料への変換を追跡
-
recipe_to_ingredient_logsテーブルで、料理を作った後に残った材料を特定 -
ingredient_to_recipe_logsテーブルで、その派生材料から新たに作られた料理を特定 -
recipesテーブルを結合して、次の料理の名前を取得 - 前の結果(
recipe_finder)と結合して料理と材料の変換の連鎖を形成
-
SEARCH DEPTH FIRST BY recipe_id SET ordercolで深さ優先探索の順序を記録
- 料理IDに基づいて深さ優先で探索し、その順序を
ordercolカラムに記録
-
CYCLE recipe_id SET is_cycle USING pathで循環参照を検出
- 同じ料理IDが探索経路に2回現れた場合、循環と判断
- 循環が検出された場合は
is_cycleフラグがtrueになる
- 各購入材料ごとに最も長い変換連鎖の最終料理を取得
-
DISTINCT ON (purchase_id)で各購入材料IDについて1行だけを選択 -
ORDER BY purchase_id, ordercol DESCで、同じ購入材料IDなら最も深く変換された最終料理を優先
実行結果
上のクエリを実行すると、以下のような結果が取得できます。
| purchase_id | ingredient_id | recipe_id | name | ordercol | is_cycle | path |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 味噌汁 | [('1',)] | False | [('1',)] |
| 2 | 103 | 103 | お好み焼き | [('101',), ('102',), ('103',)] | False | [('101',), ('102',), ('103',)] |
以上が再帰的クエリを使って、連鎖するデータを取得する例です!
無限ループに陥る例
上記の例で使っていた、CYCLE句の循環検出がある場合ない場合の違いをみてみましょう!
先ほどの料理の連鎖で使ってたテーブルに以下のような循環参照がある場合を考えてみます。
ingredients(材料)テーブル
| id | name |
|---|---|
| ... | ... |
| 1001 | そば |
| 1002 | わんこそば |
recipes(料理)テーブル
| id | name |
|---|---|
| ... | ... |
| 1001 | わんこそば |
| 1002 | どんどんじゃんじゃん |
ingredient_purchases(材料購入)テーブル
| id | ingredient_id | purchase_date |
|---|---|---|
| ... | ... | ... |
| 3 | 1001(そば) | 2020-03-01 |
ingredient_to_recipe_logs(材料から料理)テーブル
| id | ingredient_id | recipe_id |
|---|---|---|
| ... | ... | ... |
| 5 | 1001(そば) | 1001(わんこそば) |
| 6 | 1002(わんこそば) | 1002(どんどんじゃんじゃん) |
recipe_to_ingredient_logs(料理から材料)テーブル
| id | recipe_id | ingredient_id |
|---|---|---|
| ... | ... | ... |
| 3 | 1001(わんこそば) | 1002(わんこそば) |
| 4 | 1002(どんどんじゃんじゃん) | 1002(わんこそば) 💥循環参照発生💥 |
クエリ
CYCLE句を使わない場合
WITH RECURSIVE
infinity_wanko_soba AS (
-- 初期クエリ
SELECT
ip.id purchase_id,
ip.ingredient_id ingredient_id,
itr.recipe_id recipe_id,
r.name
FROM
ingredient_purchases ip
JOIN ingredient_to_recipe_logs itr ON ip.ingredient_id = itr.ingredient_id
JOIN recipes r ON itr.recipe_id = r.id
WHERE
ip.id = 3
UNION ALL
-- 再帰部分
SELECT
iws.purchase_id,
itr.ingredient_id,
itr.recipe_id,
r.name
FROM
recipe_to_ingredient_logs rti
JOIN ingredient_to_recipe_logs itr ON rti.ingredient_id = itr.ingredient_id
JOIN recipes r ON r.id = itr.recipe_id
JOIN infinity_wanko_soba iws ON iws.recipe_id = iws.recipe_id
)
SELECT * FROM infinity_wanko_soba;
こちらの実行結果が以下のようにどんどんじゃんじゃん止まらない無限ループに陥ってしまいます!
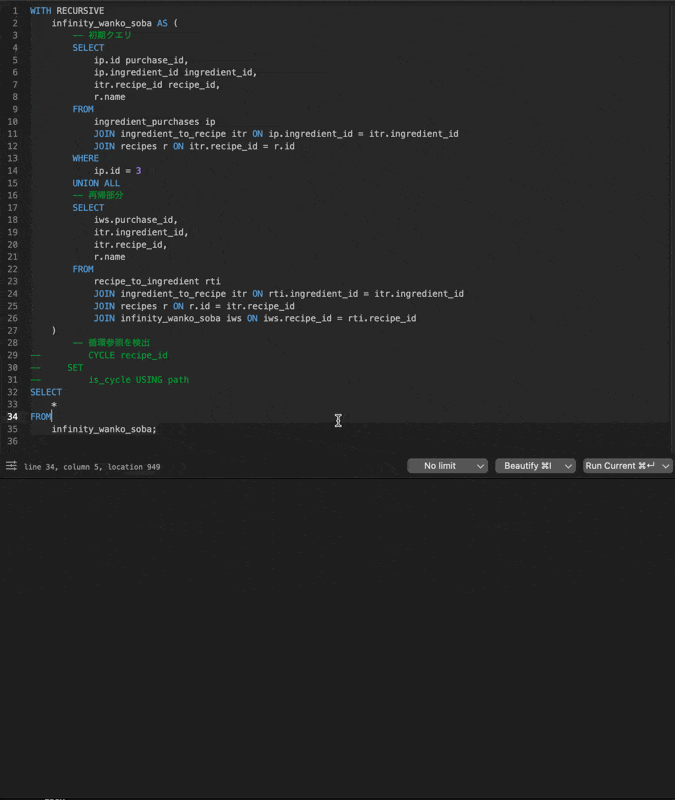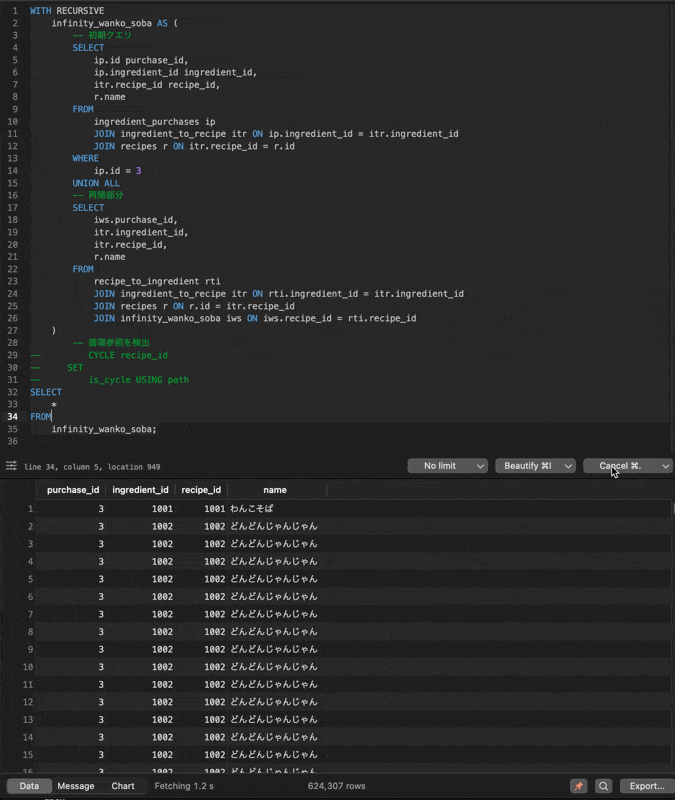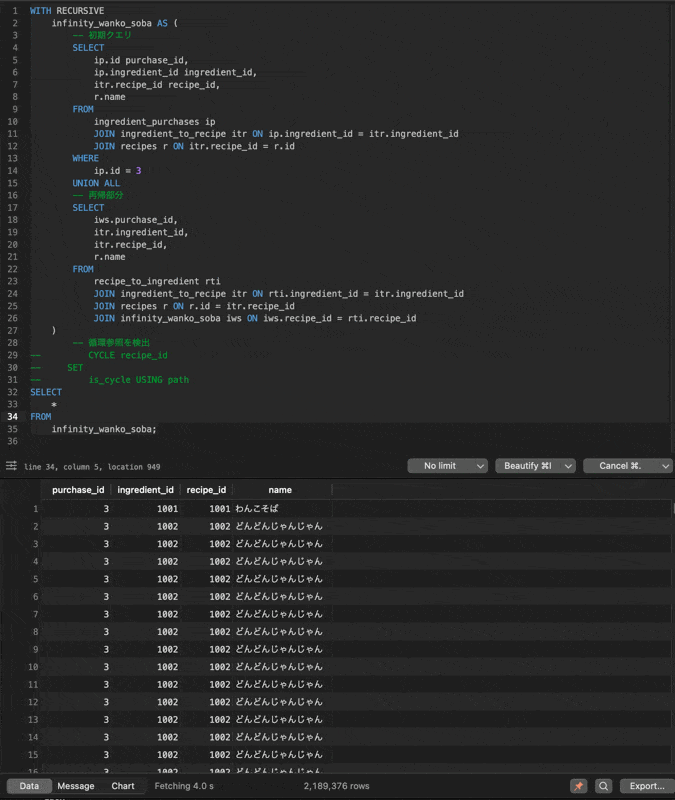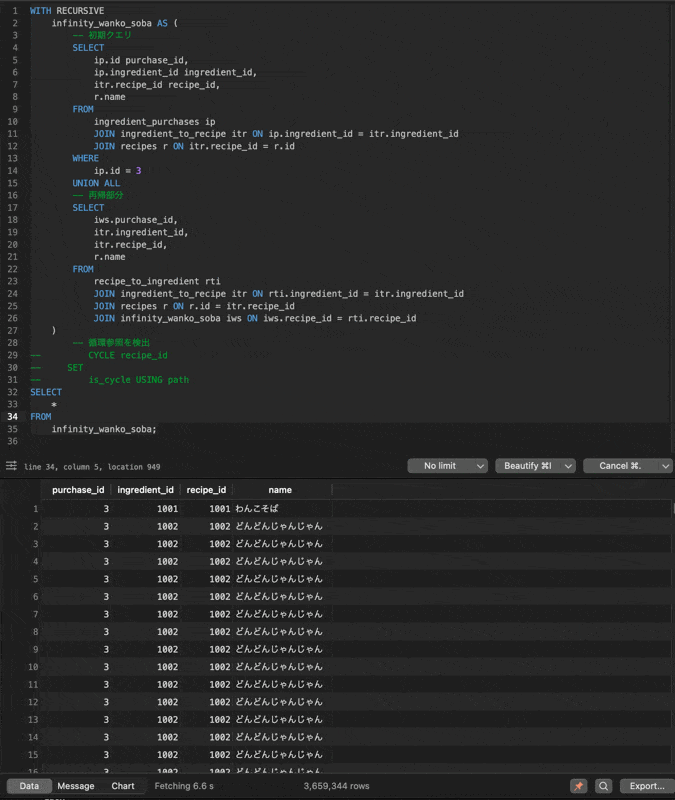
CYCLE句を使う場合
WITH RECURSIVE
infinity_wanko_soba AS (
...
)
+ CYCLE recipe_id SET is_cycle USING path
SELECT * FROM infinity_wanko_soba;
こちらの実行結果は以下のようにis_cycleカラムがTRUEになった段階で処理が止まります!
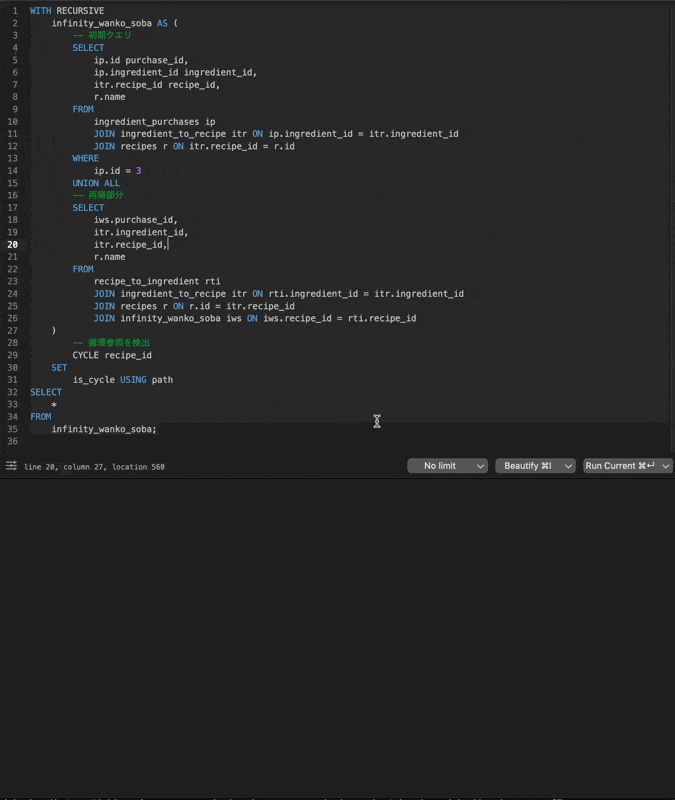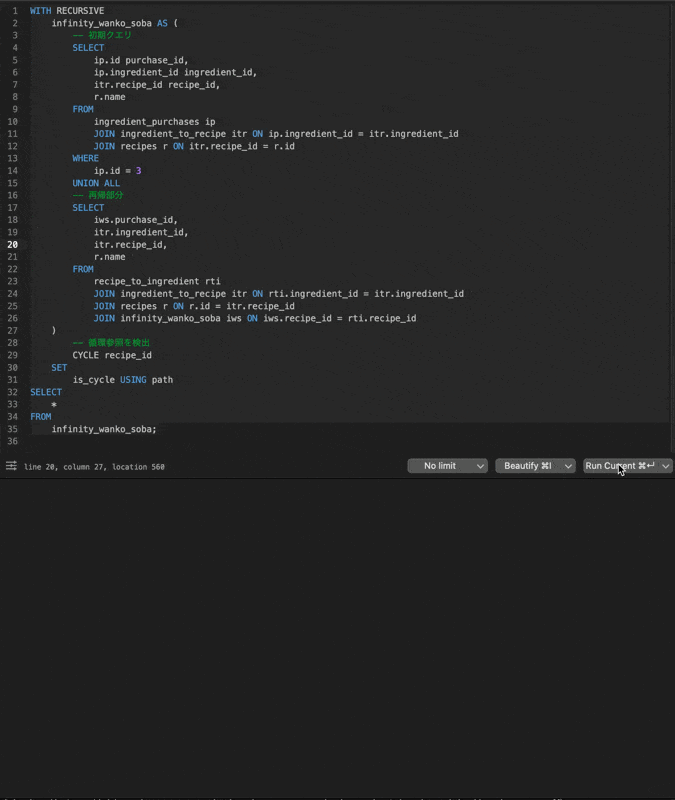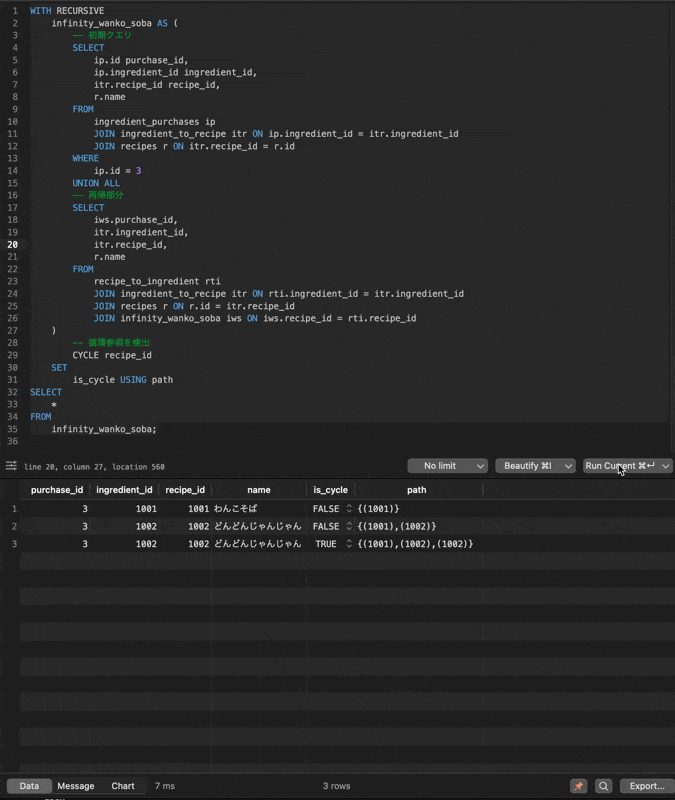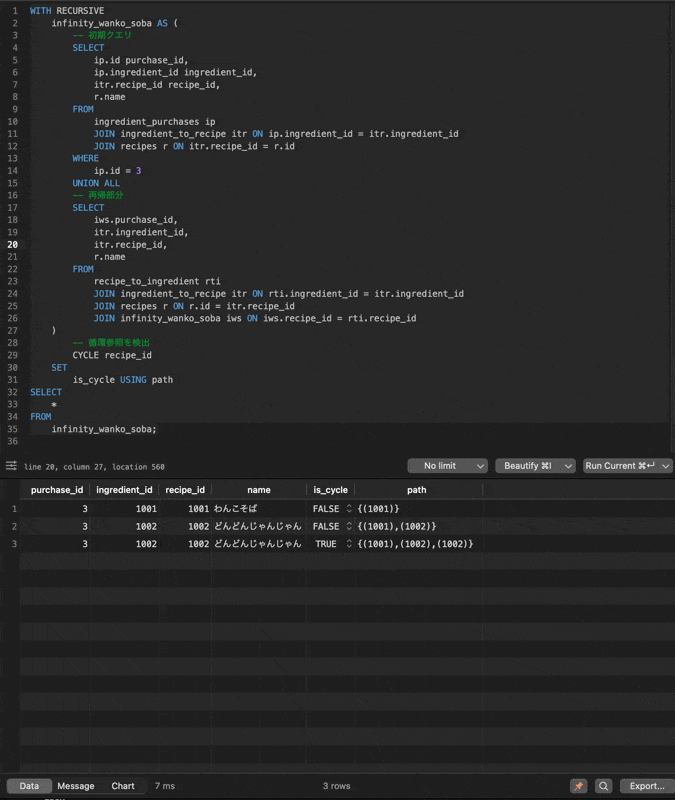
このように循環参照がある場合に無限ループに陥ることを防ぐことができるので、基本的にはCYCLE句を使うことをおすすめします!
おわりに
いかがでしたでしょうか?以上がPostgresSQLのWITH RECURSIVE句を使って再帰的なクエリを書く方法についてのまとめでした。実装に取り組み始めた時はさっぱりピーマンでしたが、理解が深まるととても便利な機能だと感じました!みなさんも連鎖的な処理をする際などに、ぜひ活用してみてください!今回使用した例はレポジトリを公開しているので、興味がある方はぜひご覧ください!それでは!

Discussion