はじめに
こんにちは!私がつとめている CastingONE という会社の SaaS には、テーブル形式のデータ一覧ページがあります。この一覧ページですが、最近データ数が増えれば増えるほど、じわじわとパフォーマンスが悪くなっていってました…。そこで今回は、そのリストデータ取得におけるパフォーマンス改善を行なった時の、パフォーマンス計測方法や検討内容、最終的な結果をまとめてみました。
対象読者
- バックエンドのパフォーマンス改善の方法や改善の流れに興味がある方
ちなみに私がこの改善を行なった時のスペックですが、パフォーマンス改善については初心者寄りでした。「パフォーマンス改善って何それ美味しいの?」というレベル感だった当初、「達人が教える Web パフォーマンスチューニング 〜ISUCON から学ぶ高速化の実践」という本には基礎を知るところから大変お世話になったので、ご興味のある方はぜひ読んでみてください。
仕様と当初の設計
最初に、現状の機能についてまとめます。今回のパフォーマンス改善では(というより、どんなパフォーマンス改善でも基本こうだと思いますが…)、既存でできることはパフォーマンス改善後も機能落ちさせないようにする必要がありました。
以下、簡単にどんなことができるのかをまとめます。
- データ一覧ページはテーブル形式の UI
- データの項目数(ヘッダー数)としては50 項目前後(非常に多い)
- データ項目のほぼすべてでソートができる(非常に多い)
- データ項目のすべてでキーワード検索ができる(非常に多い)
- ページネーション方式
- 10〜20 のフィルタ項目が存在(非常に多い)
- テーブルのカラムをチェックしてあらゆる操作(一括編集や削除)ができる
見ての通り、機能としては非常にもりもりです。データ数が多くなってくると(5 万件〜)、フロントエンドにすべての件数を返すことが困難になるため、フロントエンドはページネーション・フィルタ・キーワード検索・ソート要素などをリクエスト API に含めて送り(例: 〇〇でフィルターをかけたデータのうち、xxx のソート順に並べた 150〜200 件目までをリクエスト)、バックエンドが DB とやり取りをして必要なデータだけを返す、という形をとっていました。
改善までの流れ
では機能をご紹介できたところで、どのように改善まで持っていったか、実際の流れや自分が考えたことを以下に記載していきます。
事前のパフォーマンス計測
パフォーマンス改善においては、まずは現状を把握することが重要です。現状を計測しておかないと、今回の改善によってどれくらいの結果が出たかを明確に計測することができなくなるためです。
やったことは、以下の 2 つです。
- 計測用データの作成
- 計測できる状態の整備
まず計測用データの作成ですが、こちらはスクリプトを組んで可能な限り重くなるようなデータざっと 50 万件ほどを、本番と同じスペックにした環境へ投入しました。
次に計測できる状態の整備ですが、私の会社では既に Trace の仕組みが整備されていたため、こちらを使って気になるところに trace を貼って実際に trace の ID を利用してパフォーマンスを計測しました。
弊社サービスは Cloud Run で動いているため、Cloud Traceを利用しています。
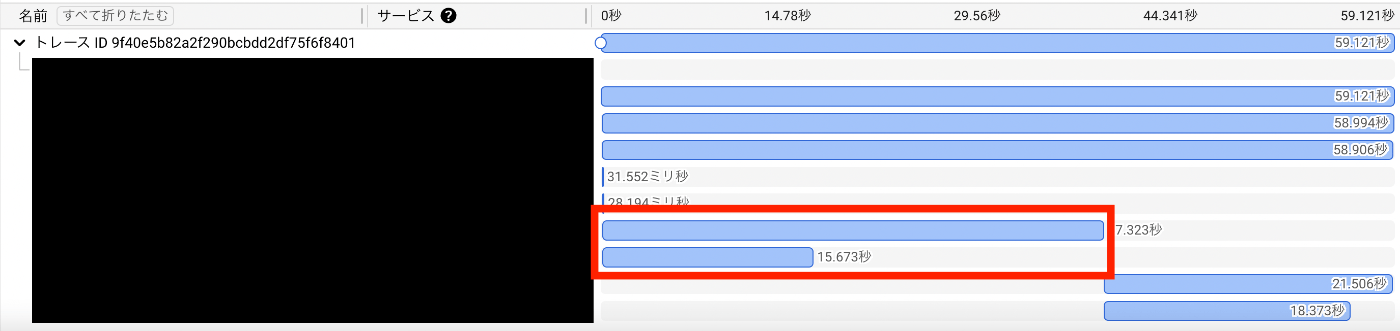
ということで、あっという間にとんでもなく重いデータが完成しました。なんとリクエストに 1 分かかってます。。
-
フロントエンド側のリクエスト
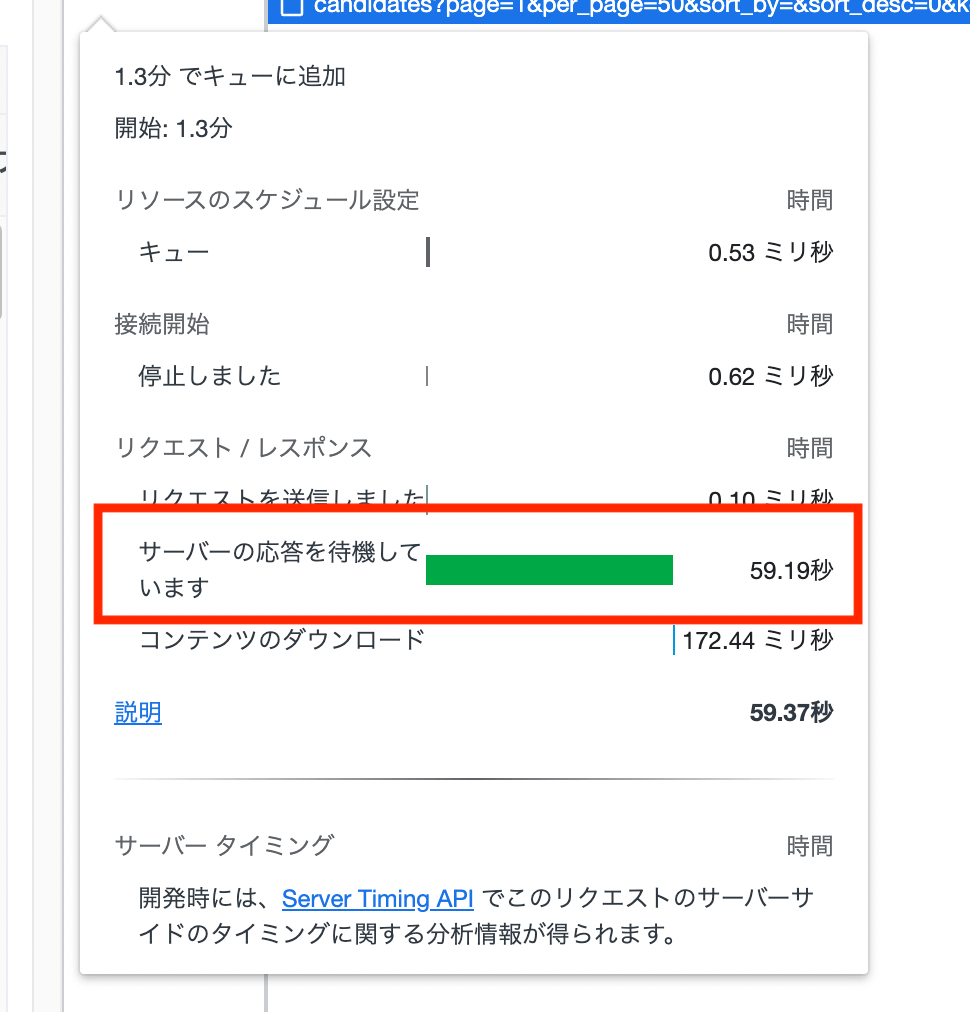
-
ログのリクエスト
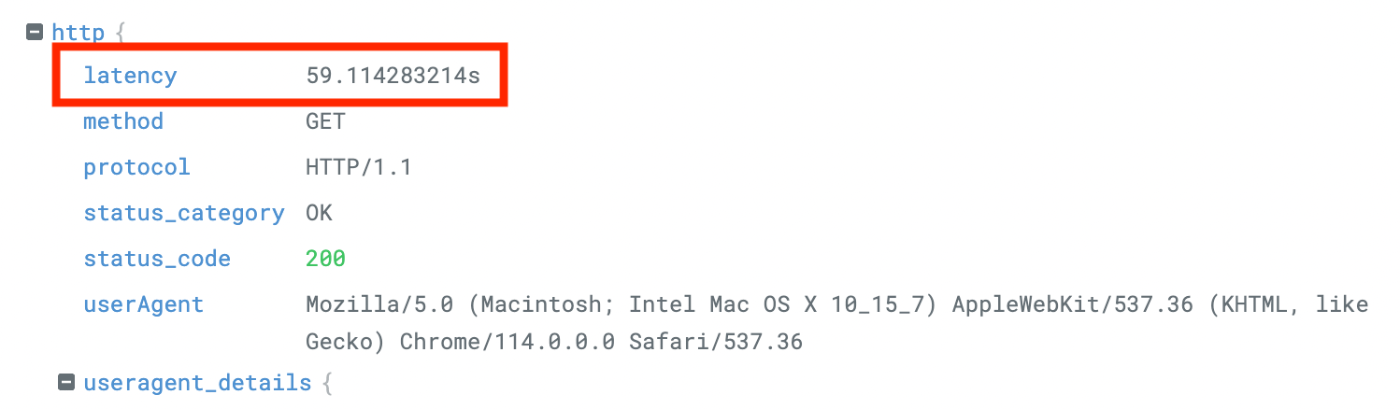
-
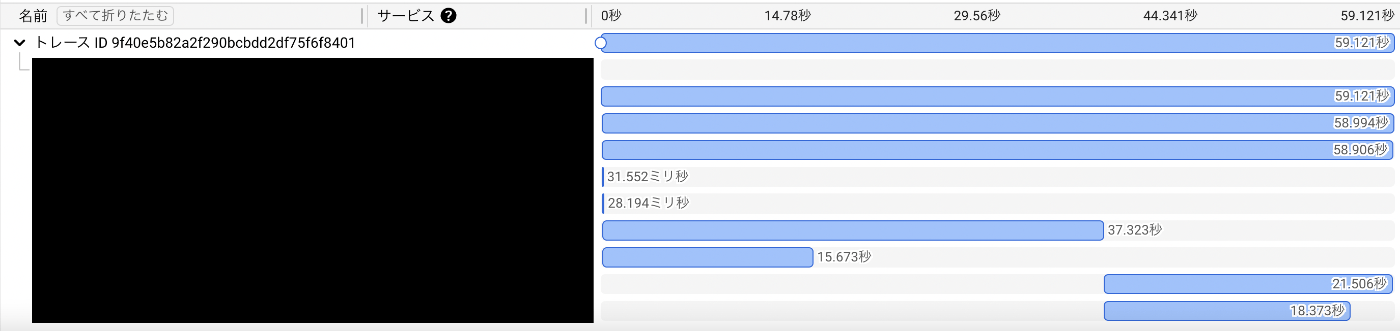
Trace
改善と調査
今回私に与えられたミッションは、改善後のレイテンシが 3 秒以下でした。
- 60 秒 →3 秒というと、小さな修正では到底到達できそうにない。大きく設計を変える必要があるかもしれない。
- そもそもリクエストに 60 秒かかるという現状を考えると、現状の設計がイケてない可能性はありそう。
上記のように考えながら、次にリクエストのどの部分にボトルネックがあるかを考えました。
ここからは、Trace の各 span の中身を見ながら、遅いリクエストを特定するフェーズに入っていきます。今回リクエストの中身を見た際に、「ここの問題を突破しないと絶対解消しないな」とわかったことは 2 つありました。
とある DB リクエストが遅い
このデータ一覧ページでは、ここのデータをとってくる処理の他に、別のデータ群を参照して一部のデータを構築する項目が 1 つありました。この項目を構築する処理がとても重いらしく、ここで 60 秒中 20 秒近く時間がかかってることがわかりました(秒数はデータに依存して前後しますが、今回は検証用に比較的重くなるデータを入れたため、最大で全体の 1/3 を占めてしまうといったイメージで考えておいてもらえると良いです)。
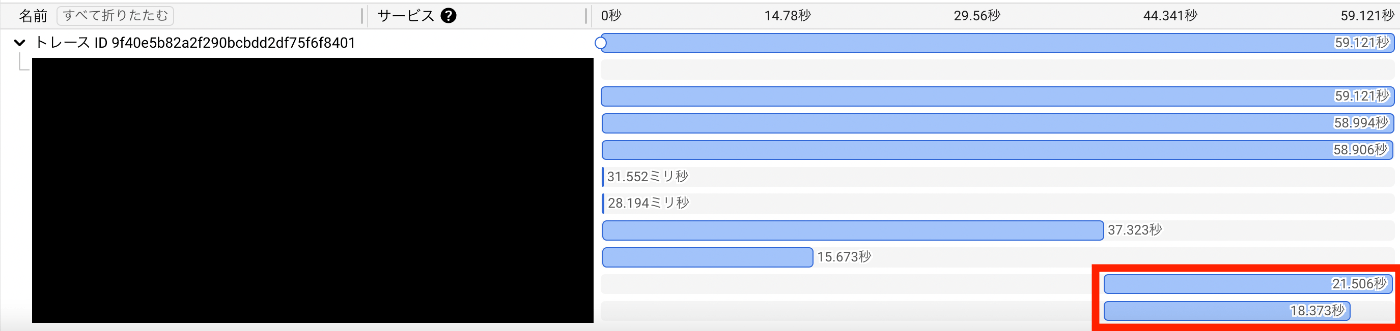
全件をリクエストせざるを得ない状況が辛い
あからさまに大きくなっている DB リクエストがあったので一目瞭然でしたが、なぜここがボトルネックになるのかをもう少し深く観察してみました。
データの項目数が多いことや従属テーブルが多いため join のオンパレードになっていたのはありましたが(これだけでもクエリはざっと 300 行ほど)、最も厄介だな〜と思ったのは別の場所です。
それは、このリクエストにソート、フィルタ、ページネーションの機能があることでした。
ソートはデータの並べ替えが必要ですし、フィルタはすべてのデータから一致するものだけを取る必要があります。これだけ聞くと MySQL 上の where や orderBy を利用すれば良いかと思われるかもしれませんが、ここにページネーションという機能が加わります。ソートやフィルタをしてデータを綺麗に整備した上で"全部で 10 万件のうち、1 番目から 50 番目が欲しい"というリクエストに応じてデータを返す必要があるので、色々考えるとまずフィルタやソートをかけて全データにアクセスする必要があるということです(その上でページネーションする)。。
一般的には limit offset を使えば mysql でもページネーションは実装出来ると思いますが、そうしなかった理由は、多くの機能を持つリストデータ取得部分はアプリケーション側での実装が低コストだったようです。特にキーワード検索は、冒頭でも述べたようにすべての項目がキーワードに引っかかる必要があるため、index をほぼすべてのカラムに貼る…?みたいな話になるので。
一部フィルタでうまいこと負荷にならないようにしている、といった工夫はもちろんありましたが、データ数に比例してパフォーマンスが悪くなる状態が起きている主な原因はこちらでした。
以下が全データをとっているリクエスト部分です。
改善方針の策定
現状をおおよそ把握したところで、実際に手元で改善コードを書きながら、既存機能を損なわない形でパフォーマンスを上げる方法を模索しました。ここはひたすら思いついたことを発散する形で検証コードを書いた記憶があります。
パフォーマンスを悪化させる DB 構成の修正
例によってまず最初にデータベースから無駄がないかを確認しました。こちらは、2 つのボトルネックに対して解消できないかを確認しました。
DB のテーブル定義に余計だったり不足したりしている index の設定はないか、データベースの検索が遅くなるようなリクエストを送っていないか、N+1 の問題は起きていないかなどです。
しかし、一部項目にて実際のリクエストの実態よりも複雑な DB 構成になっていたこと以外は、あまりデータベースにテコ入れしてパフォーマンスが良くなるような成果は出ませんでした。
重い処理を定期バッチ化
1 つ目のとある DB リクエストが遅い、という件をなんとかするためにまず着手しようとした問題です。
DB リクエストを都度行うのではなく、いくらかの時間に一度定期バッチをかける方法でした。そうすることにより、リアルタイム性は失われますが、都度リクエスト時にはこの処理部分がまるっと省略できる形となります。
しかしこの対策には、いくつかの問題がありました。
- バッチ時に一気に多くのデータに対して DB リクエストをかけた場合、メモリを消費しすぎてしまう(適度に chunk しながらリクエストをする必要がある)
- あまり頻繁に変わるようなデータではないため、1 時間に一度大量データにリクエストをかけて取得し直すると無駄な update が増えコスパが悪い
- 大幅な時間間隔のある定期バッチ化はユーザー体験を損なってしまう(この処理で取得する項目は、リアルタイムで知りたいというニーズが強かった)
このことから、定期バッチ化はある程度筋がよくなさそうということになりました。
データをリアルタイムで MySQL から取得することをやめる
このあたりから、"そもそも MySQL にその都度リクエストするっていうのを軸に考えたら、3 秒は一生無理だ。抜本的に何か変えなければ"という脳みそになってました。
そこで考えたのは、"データが変わるごとに MySQL ではない、速度の早いアプリケーションにコピーしておいて、そちらへリクエストしにいく"という、キャッシュに似た機能を備えることです。ということで、キャッシュ機構として使えそうなアプリケーションを実際に速度を計測しながら色々と探してみました。
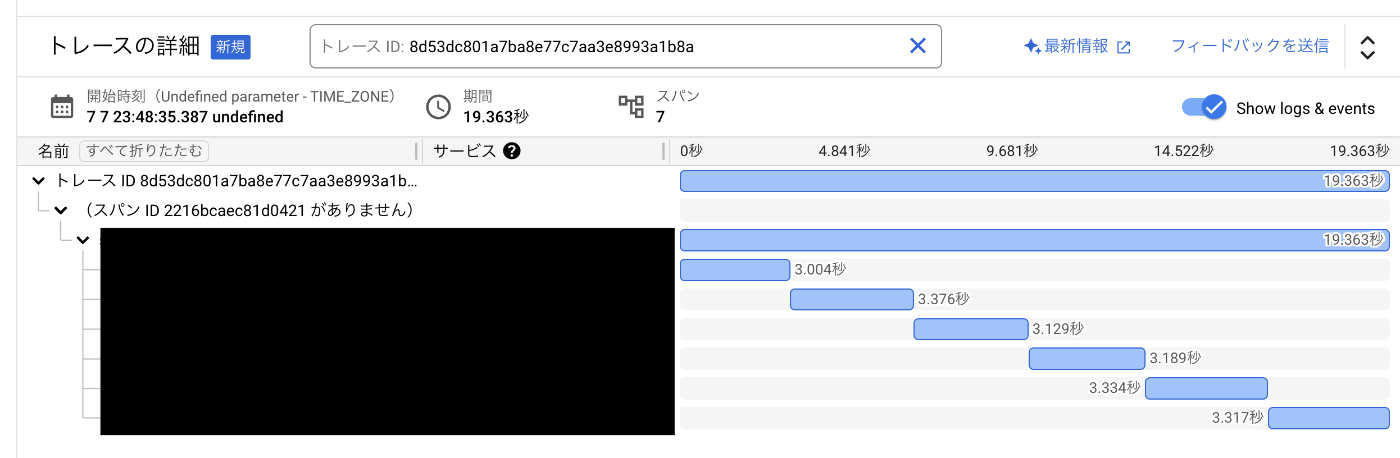
-
格納先: Google Cloud Storage
ダメです。全然遅かったです。json で格納しようとしてたのですが、json の変換に意外に時間がかかるということがわかりました。また、GCS への書き込みも遅かったです。以下が 50 万件に対する実際のデータですが、json の変換と書き込みに 10 万件 3 秒ずつがかかってしまう状態でした。
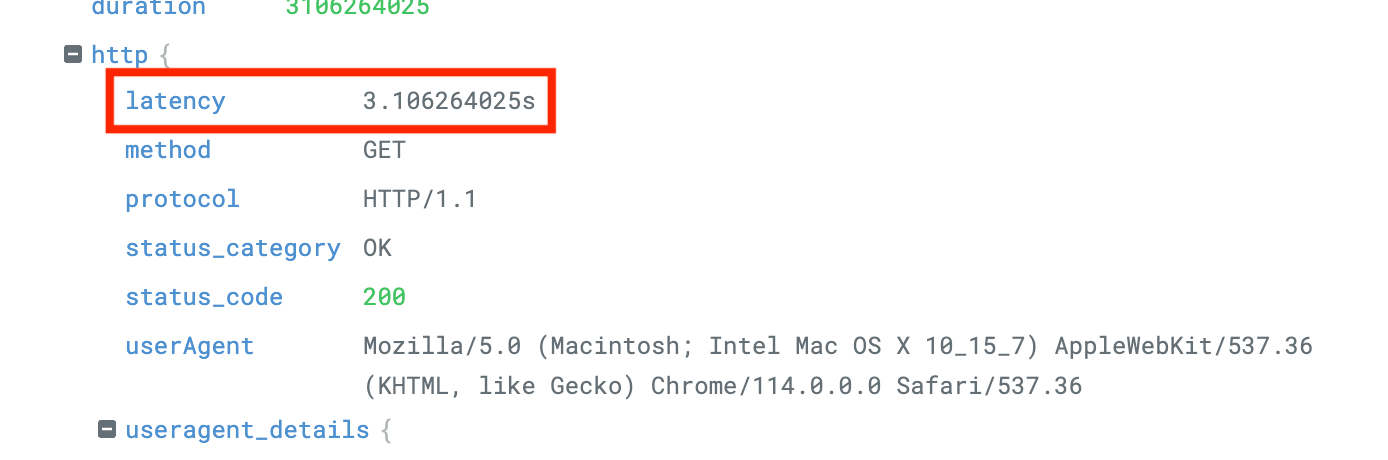
-
格納先: Redis
上の json の失敗を活かしてバイナリで格納してみました。3 秒にはなりました。Redis はキャッシュとして利用するのに適しているので、筋が良いのかなとそわそわしてました。ただ、フィルタやソートが面倒そうでした。
-
格納先: Elasticsearch
結論、こちらが非常に良かったです。調整には時間がかかりましたが、3 秒どころか 1 秒以下になりました。
以上の検証を経て、"MySQL への書き込みがあった際に、Elasticsearch へリストデータをコピーしておいておき、リクエストはそちらを見に行く"という、いわゆるニアリアルタイムでデータ同期をしておくようなスタイルにすると、リクエストのパフォーマンスが非常に良くなると感じました。
今回のパフォーマンス改善に Elasticsearch を使おうとなった決め手は、単にスピードだけではありません。検証時にボトルネックに感じていた 2 つの問題を両方解消できることに気づけたためでした。
まず、ボトルネック 1 つ目の DB リクエストが重い件についてです。
こちらはリアルタイムに処理することがなくなるため、少なくともリクエスト時解消できます(お気づきかと思われますが、リクエストするタイミングが、MySQL に update が走って Elasticsearch へのデータ書き込みを行う時に変わっただけなので、重いということには変わりません。こちらは只今も絶賛改善中です)。
次に、ボトルネック 2 つ目である、全件リクエストの問題についてです。
結局キャッシュ形式にしたとしても、GCS や Redis フィルタやソートの兼ね合いで、一旦は全データを引っ張らなくてはいけない状況でした。しかし、Elasticsearch の SearchAPI を利用すると、「このデータのうち、xx でフィルタしたデータを xx のソート順で並べたもののうち、xx 番目から xx 個のデータを返して」というリクエストを送ることができたのです(見つけた時、感動しました)。全件引っ張るという処理は、総データが多ければ多いほど、スピードもそうですがメモリにも高負荷がかかりますので、この解消は色々助かるぞと思ってました!
余談ですが、Elasticsearch については導入にあたり非常に理解に苦労したので、別記事でまとめています。
仕様の策定
この Elasticsearch を利用した形式の一覧ページに変えていくにあたり、最後に検討したのが"パフォーマンス改善によりニアリアルタイムへ変わるという大きな変化があるが、どこかでユーザー体験を損なう可能性があるか。また損なう場合はどうやってリカバリーするか"でした。
幸い Elasticsearch の書き込みリクエストが意外に早かったので、10 万件のデータを一気に更新…とかを行わない限り、すぐに最新に似たデータが取れる状態まで持っていくことができました。しかし、パフォーマンスは良くなったもののユーザー体験が損なわれるのは本末転倒だと思っていたので、慎重に以下のことを考えました。
- リクエスト時に最新状態ではないことを、ユーザーが知っているような仕組みがあった方が良い
- 何か一覧で更新をかけたり操作をした時、見えているデータが最新ではないことは伝えた方が良い
特にこのテーブル形式の一覧ページはユーザーがよく使うページなので、体験は少しでもよくしておきたいというのもありました。
そこで考えた UI 側の施策が、以下の通りです。
操作後のトースト通知文言を見直す
最初の方に機能を紹介した際に、テーブルのカラムをチェックしてあらゆる操作(一括編集や削除)ができるというのがあると伝えました。
この一覧ページ上での操作時に、以前は処理後に「xx が成功しました」というトースト通知が流れるようにしていましたが、「xx が成功しました。最新データの準備ができるまで少々お待ちください」といったものに変更しました。
これは細かい変更なのですが、たとえばユーザーが見えている表の項目を更新や削除した際に、処理終了後も Elasticsearch の準備ができていない時にはまだデータが表示されない、というケースがあると判断したためです。"Elasticsearch の方のデータが準備できるまであなたが見ている一覧ページのそれは最新ではないよ"ということを、きちんとその都度ユーザーに伝えるようにすることで、更新後にすぐデータが変わらなくても不具合ではないことを明示しました。
こちらは一例ですが、一覧操作時のトースト通知文章はほぼ見直しをかけ、必要に応じてユーザーが混乱しない程度の補足になるようにしました。
同期状況がわかるように UI を変更する
ユーザーが一覧ページを見ている間"今自分が見ているデータは最新なのか"が判断できるようにしたいなと思いました。そこで、データ同期のステータスを以下主に 3 つに分けて、常に画面上部に表示しておく仕組みにしました。
- データは変更なし(最新)
- データを同期中
- データ同期が完了し新しいデータへ差し替え可能
また、最後のステータスであるデータ同期が完了し新しいデータへ差し替え可能状態の時には、再度 API リクエストをし直せるボタンを設置し、ユーザーが必要に応じてリストデータを取得し直せるようにしました。
今どんな状況か、そのことをユーザーに伝えることで、"きちんとデータは反映されてるのか?"という疑問に答えられる形式にしました。
結果
以上で調査を終了し、設計・実装することができました。最終的な着地点としては、以下の通りです。
最終的な設計
- 取得時の更新状況などは MySQL がデータを持っているため、ユーザーは何秒かに一度データ状況を確認します
- データ状況によって、ユーザーはデータ状況を知り、必要に応じて更新をかけることができます
ちょっと細かいですが、流れはこんなイメージです。
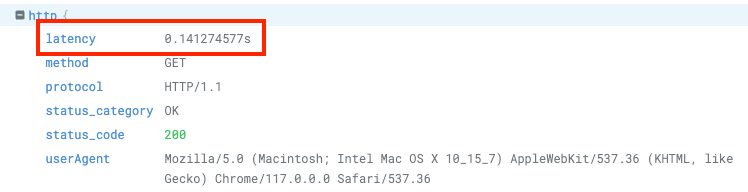
実際のリクエスト
ちょっと話が設計寄りになってしまったため、リクエストのレイテンシの方へ戻します。以下が ES を導入したあとのレスポンスです。早くなってました!
おわりに
パフォーマンスのミッションを持って改善に臨んだのが初めてだったのですが、以下 2 つの点でとても勉強になった&取り組みをして良かったと思っています。
1 つ目は、パフォーマンス改善の大枠の方法や流れを理解することができたことです。
今回は結論としてかなりドラスティックに色々変えることによりパフォーマンスを改善することになりましたが、調査段階では N + 1 問題をはじめとした重いクエリ部分の改善検討など細かいところも非常に見ていっていました。また、パフォーマンスを計測する方法も本当に色々で、そこを知ることができたのが良かったです。
2 つ目に、バックエンド・フロントエンドの双方の知識が活かせたことです。
私は普段の開発からバックエンド・フロントエンド両方に手を出しているのですが、Elasticsearch を利用してニアリアルタイムを実現させることにより生じたリスクを、フロントエンド部分と協力して吸収して可能な限り解消することを思いついた時、「どっちもやってて良かったな〜」と本当に思いました。
また、総合してパフォーマンス改善って本当に色々やりようがあるのだなと思いました!
繰り返しになってしまっていますが、今回の施策は設計をガラッと変えるパターンでしたが、そうした理由は現状のボトルネック(重い処理, 全件リクエスト地獄)をぴたりと解消する手段が見つかったことからでした。ですがもちろん、MySQL のクエリを変えることでガラッと改善できることもあったりすると思っています。このように考えると、原因の追求と解消のための施策立案や検証プロセスは、非常に重要だなと感じています。
今後の展望として、今は MySQL の行っていた処理をそのままリプレイスする形になったのですが、もっと仕様を Elasticsearch を根底に考えてらしい設計にすれば、パフォーマンスはもちろんですがあらゆる意味でユーザーにとって優しい機能が作れると思っています。そのへんは、Elasticsearch とユーザー双方の理解をより深めていきたいです。
ここまで長々読んでいただき、ありがとうございました!以下に、いつものやつです。

Discussion
DBでの検索は遅いままなんでしょうか?