はじめに
株式会社CastingONEでバックエンドエンジニアをしている村上です。
先日Webhookのリトライ機能を実装していたところ、GCP Cloud Tasksで想定外の遅延が発生したため、解決方法など備忘録としてまとめます。同じように遅延に苦しんでいる方がいれば、参考になると嬉しいです。
読んでほしい方
- Cloud Tasks で遅延が発生していて、解決方法を知りたい方
- Cloud Tasks のリトライ制御について情報収集している方
解決方法
ケースバイケースになりますが、今回の場合は下記の方針にすることで遅延を解消できました。順を追って振り返っていきます。
- Cloud Tasks 標準のリトライ機能を安易に使わない
- 高頻度のリトライが発生しうる場合は、タスクを作り直す
設定通りにリトライしてくれない
早速、リトライの挙動を調べてみます。下記のシンプルな構成で検証します。
- gcloudコマンドでHTTP Targetのタスクを作成する。送信先はRequestBin(※1)
- Cloud TasksがRequestBinにタスクをディスパッチする
- RequestBinがCloudTasksにエラー(※2)を返す
- リトライが行われる
※1 HTTPリクエストを受け付けるモックサーバー的なものです。
https://requestbin.com/
※2 厳密にいうと、200番台以外のレスポンスを返すことでリトライが行われます。
https://cloud.google.com/tasks/docs/dual-overview?hl=ja#http
リトライの設定は2秒ごとにしました(minBackoff、maxBackoff参照)
$ gcloud tasks queues describe test-queue
name: projects/hoge/locations/asia-northeast1/queues/test-queue
rateLimits:
maxBurstSize: 100
maxConcurrentDispatches: 1000
maxDispatchesPerSecond: 500.0
retryConfig:
maxAttempts: -1
maxBackoff: 2s
maxDoublings: 16
maxRetryDuration: 3600s
minBackoff: 2s
stackdriverLoggingConfig:
samplingRatio: 1.0
state: RUNNING
gcloudコマンドでタスクを作成します。
$ gcloud tasks create-http-task --queue=test-queue --url=https://eoekebxzhwwa1l6.m.pipedream.net
RequestBinは500エラーを返すように別途設定したので、これで2秒ごとにHTTPリクエストが届くはずです。RequestBinのUIを見てみます。
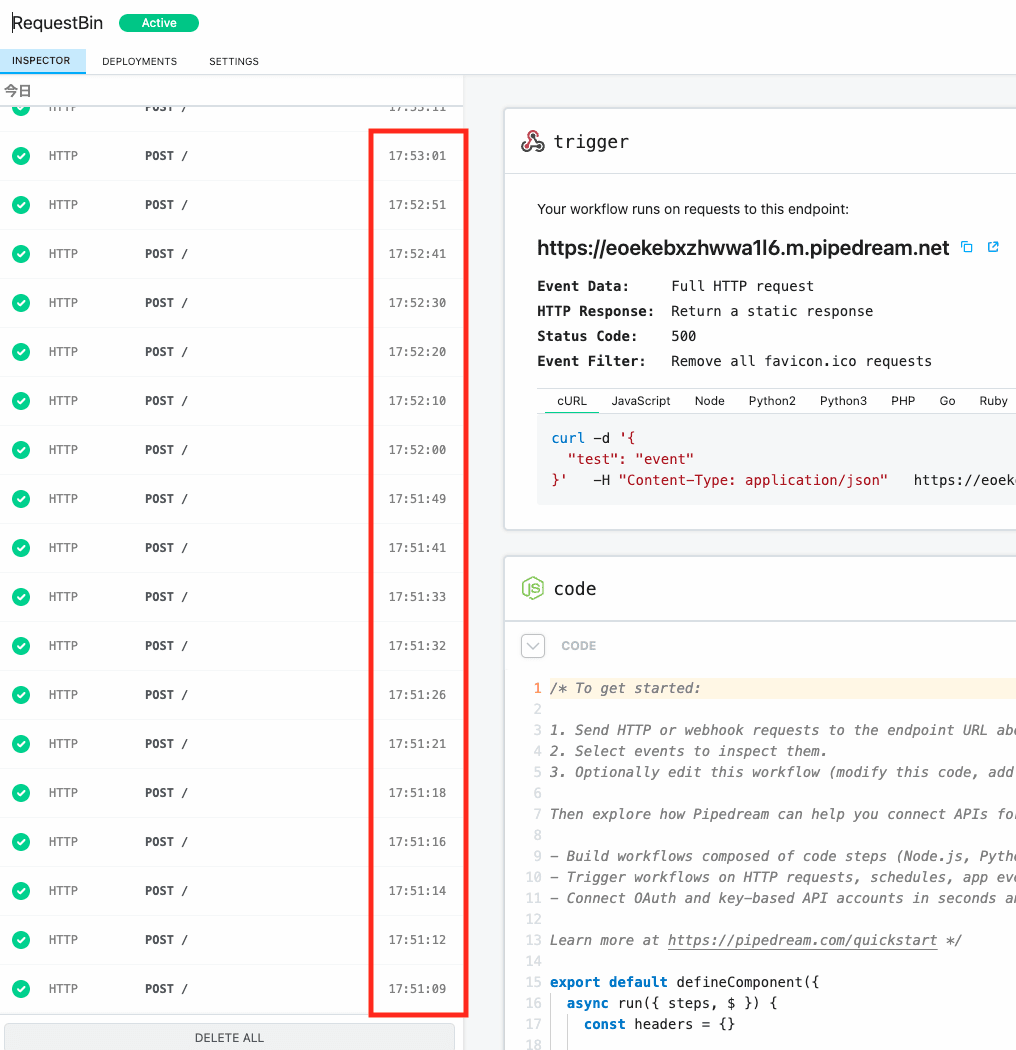
時系列としては、下から上に向かって並んでいます。最初はおおむね2秒ごとにリトライされていますが、3秒…5秒…とペースが落ちて、最終的に10秒に1回になってしまいました。
なんでや…(´・ω・`)
しかもこれ、タスク1つにつき10秒間隔ではなく、すべてのタスクに対して10秒間隔です。タスクが100個あっても1分で6回しかリトライできません。
スロットリングが発生しているっぽい
というわけで原因を調べてみたのですが、どうも System throttling というものが発生していたようです。
// * System throttling: To prevent the worker from overloading, Cloud Tasks may
// temporarily reduce the queue's effective rate. User-specified settings
// will not be changed.
//
// System throttling happens because:
//
// * Cloud Tasks backs off on all errors. Normally the backoff specified in
// [rate limits][google.cloud.tasks.v2.Queue.rate_limits] will be used. But if the worker returns
// `429` (Too Many Requests), `503` (Service Unavailable), or the rate of
// errors is high, Cloud Tasks will use a higher backoff rate. The retry
// specified in the `Retry-After` HTTP response header is considered.
System throttlingが発生する条件は下記のとおりで、今回のケースは3つ目でした。
- 429 のレスポンスを返す
- 503 のレスポンスを返す
- エラーの割合が大きすぎる
Cloud Loggingで見ても、エラーが頻発しています。
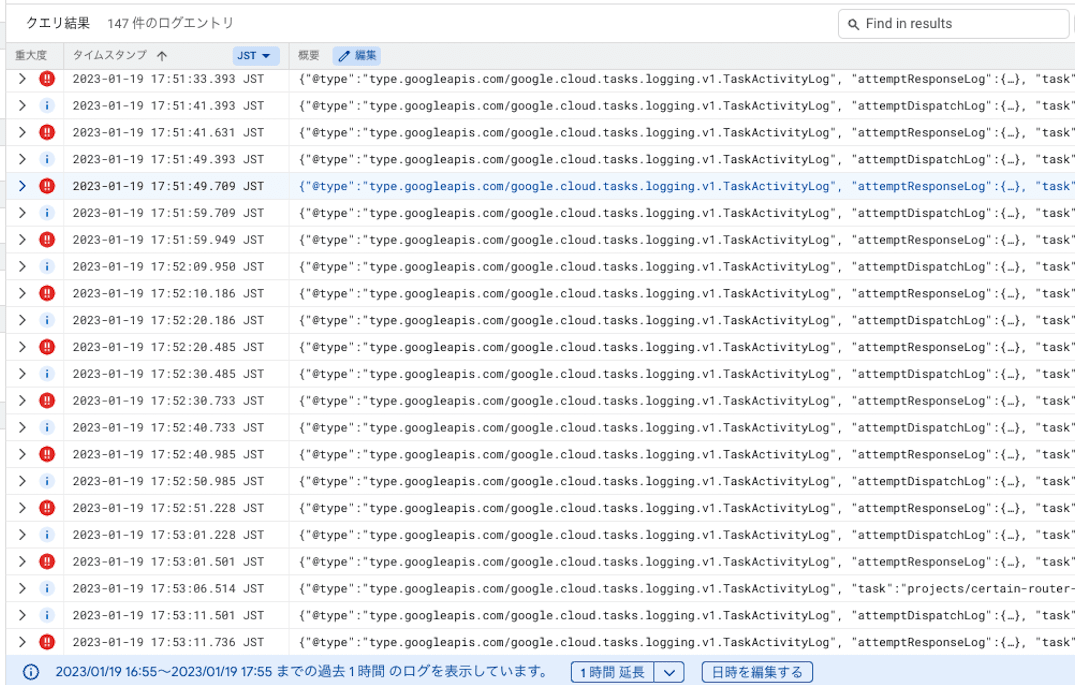
Cloud Tasksで意図しない遅延に遭遇した場合は、これらに当てはまらないか確認すると良いと思います。
リトライをやめてタスクを作り直した
そうは言っても、「じゃあリトライしません」というわけにもいかないので、解決方法を探ってみました。
そしてたどり着いた答えは、”タスクを作り直す”
下記のアイデアをそのまま拝借しただけですが、リトライする場合でもタスクを正常終了扱いにして(タスクを削除して)、リトライ用のタスクを新規作成しました。その結果、Cloud Tasksにエラーを返すことがなくなり、遅延を解消できました(苦肉の策感は拭えないものの)
下記のような流れです。
まとめ
「そもそもリトライが頻発する状況をどうにかしろ」という話もありますが、外部の要因(例えば、Webhookにおける送信先のサーバー)でコントロールできないこともあります。
そのような場合は、ひとつの選択肢として下記の案を検討いただくと良いと思います。「もっと良い方法があるよ!」という方がいれば、ぜひ教えて下さい。
- Cloud Tasks 標準のリトライ機能を安易に使わない
- 高頻度のリトライが発生しうる場合は、タスクを作り直す
ちなみに、標準のリトライ機能はいつ使うのかというと、弊社のWebhookにおいては内部の要因(主にバグ)でエラーが発生した際に使っています。バグっているので、むしろSystem throttlingは歓迎という考え方です。
あと、「てか、Pub/Subの方が良かったんじゃない?」というありがたいツッコミも社内でいただいています。
おわりに
弊社でいっしょに働いてくれるエンジニアを募集中です。社員でもフリーランスでも、フルタイムでも短時間の副業でも大歓迎なので、気軽にご連絡ください!

Discussion