✅
基本的なGAN
はじめに
概要
- シラバス:E資格2024#2
- 基本的なGANモデル(GAN, WGAN, DCGAN)を勉強する
キーワード
GAN, 生成器, 識別器, モード崩壊, Wasserstein GAN,
Wasserstein距離, DCGAN
学習内容
GAN(Generative Adversarial Nets)
- リアルな画像生成において非常に大きな成功を収めている強力な生成モデル
仕組み
- Generator(生成器):ノイズ(例:正規分布)からそれっぽいデータを生成する
- Discriminator(識別器):入力されたデータが「本物(訓練データ)か偽物(生成器の出力)か」を判別する
- GeneratorはDiscriminatorを「だます」ために偽物を作る
- Discriminatorは本物と偽物を見分けようと頑張る
- それぞれが交互に学習し、最終的にGeneratorが非常にリアルなデータを生成できるようになる
z(ノイズ) x(本物のデータ)
│ │
▼ ▼
[ Generator G ] [ Discriminator D ]
│ ▲
▼ │
生成データ G(z) ──────────────▶ 判定:本物か偽物か
GANの目的関数
- 目標
- 第一項(識別器)を最大化
- 第二項(生成器)を最小化
x:本物のデータ(例:本物の画像)
z:ノイズベクトル(潜在変数)
課題
| 問題 | 説明 |
|---|---|
| 学習が不安定 | GeneratorとDiscriminatorのバランスが難しい |
| モード崩壊 | Generatorが同じような出力ばかり出すようになる |
| 微妙な調整が必要 | ロス関数、構造、学習率などに工夫が必要 |
モード崩壊(mode collapse)
- Generatorが出力の多様性を失い、訓練データ分布のすべてのモードを表現できなくなる
例
- 訓練データに含まれる画像(3つのモード):
- 犬の画像(33%)
- 猫の画像(33%)
- 鳥の画像(33%)
- モード崩壊の結果(Generatorの出力):
- 犬:100%
- 猫と鳥:0%
- 結論:犬以外のモードを無視している
Wasserstein GAN(WGAN)
- 損失関数にWasserstein距離(地球移動距離、EM距離)を用いて学習の安定性を向上させたGAN
- GANの「学習が不安定」「損失が学習の進行を反映しない」などの問題を改善
- モード崩壊が起こりにくい
- 実装がDCGANよりやや複雑
- 通常のGANでJS距離を使う。JS距離は、2つの分布が重なっていないと勾配が消失しやすい(→ 学習が止まる)。Wasserstein距離は、常に勾配が存在し、連続的な学習が可能
Wasserstein距離
- 確率分布同士の「距離(違い)」を測る手法
- 「ある分布から別の分布に“質量”をどれだけのコストをかけて運べば一致するか」という考え方
例
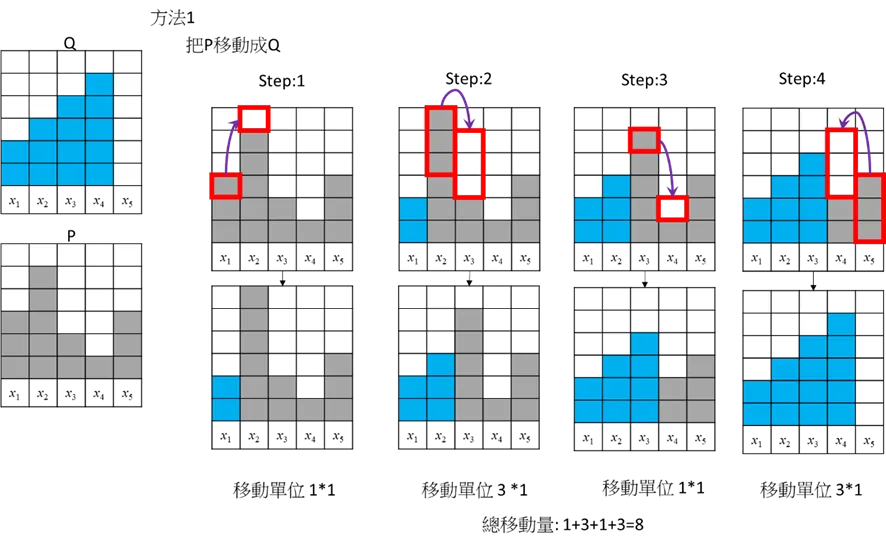
セルの移動で、PをQにする。
の距離は1とする x_1,x_2,...,x_n
出典:
Tommy Huang, 還看不懂Wasserstein Distance嗎?看看這篇。(2022),https://chih-sheng-huang821.medium.com/還看不懂wasserstein-distance嗎-看看這篇-b3c33d4b942
方法1
総移動量=
出典:
Tommy Huang, 還看不懂Wasserstein Distance嗎?看看這篇。(2022),https://chih-sheng-huang821.medium.com/還看不懂wasserstein-distance嗎-看看這篇-b3c33d4b942
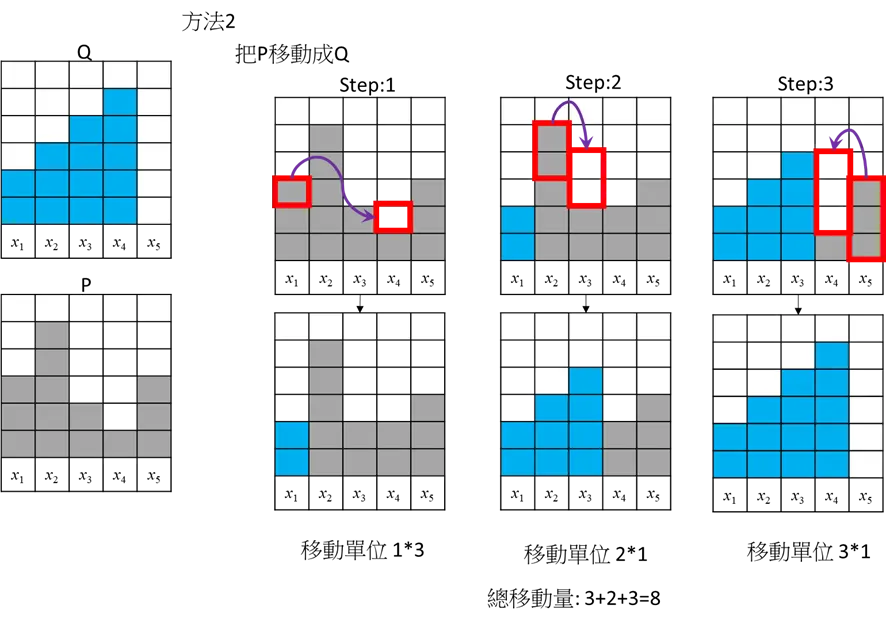
方法2
総移動量=
出典:
Tommy Huang, 還看不懂Wasserstein Distance嗎?看看這篇。(2022),https://chih-sheng-huang821.medium.com/還看不懂wasserstein-distance嗎-看看這篇-b3c33d4b942
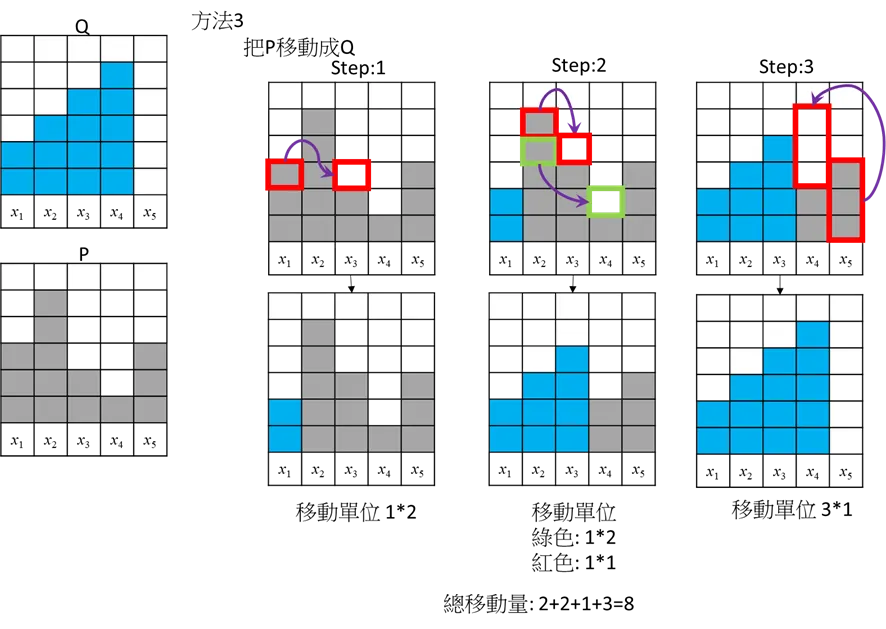
方法3
総移動量=
結果:Wasserstein距離=8
正規化:総質量で割ると、8/14=0.5714
Wasserstein距離の正規化
- 比較対象となる分布同士の「規模の違い(スケールの差)」や「範囲の広さ」を補正して、距離の絶対値が意味のある比較指標になるように調整する
- 例:
- 分布AとBが
[0,1]上にある → 距離 = 0.2 - 分布CとDが
[0,1000]上にある → 距離 = 200 - 実は形状がほぼ同じでも、スケールのせいで距離が大きくなってしまう
- 分布AとBが
- 方法:最大距離で割る/総質量で割る/平均移動距離にする
DCGAN(Deep Convolutional GAN)
- GANに畳み込み層(CNN)を取り入れた構造
- Generatorは転置畳み込み、Discriminatorは普通の畳み込みを使用
- GANの代表的な改良版として、高品質な画像生成が可能
- 学習が不安定になることがある(モード崩壊など)
CNNの構成
- Discriminatorで使用するCNN
- プーリングを使用せず、ストライド2の畳み込みに置き換える
- 全結合層を使用せず、Global average poolingに置き換える
- 入力層以外の層にBatch normalizationを適用する
- 全ての層で活性化関数にLeaky ReLUを使用する
- Generatorで使用するCNN
- 転置畳み込みを使ってアップサンプリングを行う。
- 出力層以外の層にBatch normalizationを適用する。
- 出力層だけ活性化関数にtanh関数を使用し、それ以外の層では全てReLU関数を使用する。
Discussion