✅
Mask R-CNN
はじめに
概要
- シラバス:E資格2024#2
- Mask R-CNNモデルを勉強する
キーワード
RoI Align, インスタンスセグメンテーション, Mask R-CNN
学習内容
RoI Align(Region of Interest Align)
- 画像中の候補領域(RoI)を、より正確に固定サイズの特徴マップに変換する方法
- 「量子化によるズレ(誤差)」をなくして、より正確に特徴を切り出す方法
RoI Poolingの問題点
RoI Pooling は、以下の処理を行います:
- 入力の候補領域(RoI)を固定サイズ(例:7×7)に分割
- 各領域内で最大値(Max Pooling)を取る
- 問題点
- 座標を整数に丸める(量子化)→空間的なずれや情報の欠落が発生
- マスク予測など、ピクセル単位での精度が重要なタスクには不向き
仕組み
| 操作 | RoI Align のやり方 |
|---|---|
| 量子化 | 行わない → 浮動小数点座標のまま処理 |
| 特徴量の取得 | バイリニア補間を使う |
| サイズ変換 | RoIを正確に分割し、補間で値を取得して固定サイズへ変換 |
RoI Poolingとの比較
| 項目 | RoI Pooling | RoI Align |
|---|---|---|
| 座標処理 | 四捨五入(量子化) | 小数点のまま処理(補間) |
| 特徴量の取得 | 最大値 Pooling | バイリニア補間 |
| 精度 | ズレあり・粗い | 正確・滑らか |
| 適したタスク | 一般的な物体検出 | セグメンテーション・精密検出 |
インスタンスセグメンテーション(Instance Segmentation)
- 画像中の「各物体(インスタンス)」ごとに、ピクセル単位で領域を識別するタスク
- 「何が写っているか」だけでなく、「どのピクセルが、どの個別の物体に属するか」まで予測する
他のタスクとの違い
| タスク名 | 目的・出力の形式 |
|---|---|
| 画像分類 | 画像全体に1つのラベル(例:「犬」) |
| 物体検出 | 各物体にバウンディングボックス+クラスラベル |
| セマンティックセグメンテーション | 各ピクセルに「クラスラベル」のみ(個体の区別なし) |
| インスタンスセグメンテーション | 各ピクセルに「クラス+個体ID」あり(同じクラスの複数を区別) |
例えば、犬が2匹写っている画像
- セマンティックセグメンテーション→ どちらも「犬」としてマスク(個体の区別なし)
- インスタンスセグメンテーション→ 1匹目の犬と2匹目の犬を「別々」にマスク
Mask R-CNN
- 物体検出(位置+ラベル)に加えて、「各物体の形(マスク)」もピクセル単位で予測するモデル
- インスタンスセグメンテーションを実現する代表的なモデル
出力
画像中の物体ごとに次の3つを出力する
- クラスラベル(例:人、犬、車)
- バウンディングボックス(矩形の座標)
- マスク(ピクセル単位の領域:例 28×28 の2次元マップ)
Faster R-CNNとの比較
Faster R-CNN
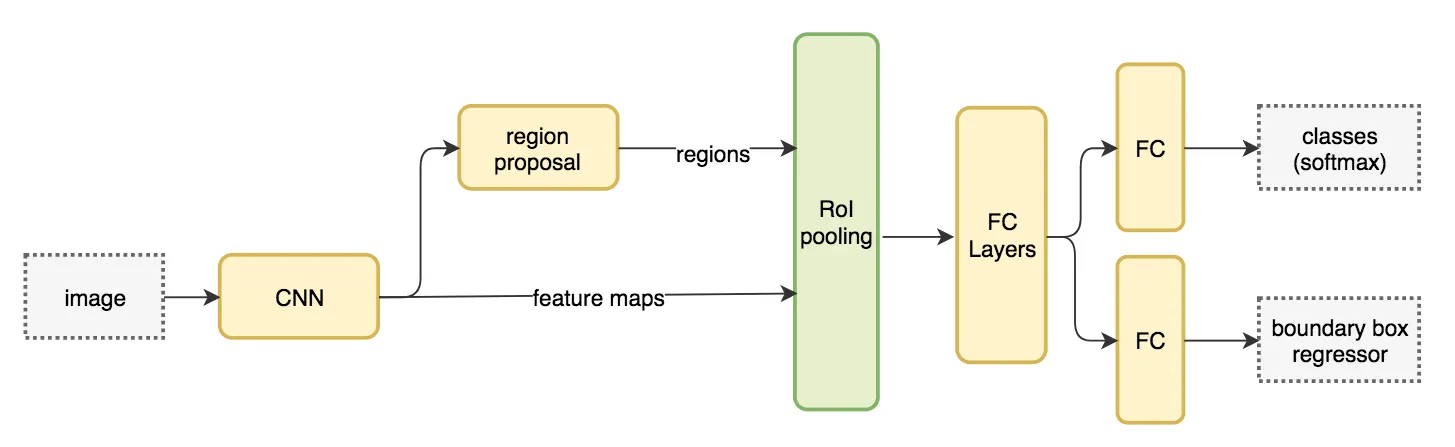
出典:
Jonathan Hui, What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?(2018), https://jonathan-hui.medium.com/what-do-we-learn-from-region-based-object-detectors-faster-r-cnn-r-fcn-fpn-7e354377a7c9
Mask R-CNN

出典:
Jonathan Hui, Image segmentation with Mask R-CNN(2018), https://jonathan-hui.medium.com/image-segmentation-with-mask-r-cnn-ebe6d793272
Discussion