はじめに
DynamoDBは非常に便利なNoSQLデータベースサービスですが、使いこなすには考えるポイントもそれなりに多いサービスだと思います。テーブル・キー・インデックスの設計であったり、安定性とコスト効率性のバランスを取ってキャパシティ設計したりなど。
私達が開発している車×IoTのサービスである「Cariot(キャリオット)」では、デバイスから送信されたデータを保存するための時系列データベースとして、DynamoDBを初期から活用しています。
今回(といっても少し前ですが)、積み上がっていくデータストレージコストの最適化を図るために、アクセス頻度の少ない古いデータ=コールドデータをS3に移し、DynamoDBへのクエリとS3 Selectを併用した階層型のアーキテクチャに移行したので、事例を紹介します。
今では時系列データベースと言えばAmazon Timestreamですが、東京リージョンにやってきてからは日が浅く、まだまだDynamoDBやその他のデータベースで運用されているケースが多いのではないかと思っています。
同じような悩みをもっている方の参考になれば幸いです。
背景
対象のDynamoDBのテーブル
今回の対象テーブルは、車のIoTプロダクトにおいて、車載デバイスを特定するID、時刻、速度や位置情報などを保存するためのものです。便宜上「センサデータ」と呼びます。
イメージとしては、以下のような構造のテーブルになります。
| device_id | timestamp | speed | latitude | longitude | … |
|---|---|---|---|---|---|
| 123456789 | 2024-03-10 12:10:00.000 | 40.1 | 35.68123 | 139.76712 | |
| 123456789 | 2024-03-10 12:10:03.000 | 40.2 | 35.68123 | 139.76713 | |
| 123456789 | 2024-03-10 12:10:06.000 | 40.0 | 35.68124 | 139.76713 |
高いリアルタイム性を保つため、デバイスにつき、 3秒に1回 の頻度でデータを貯めています。
1つ1つのデータは小さいのですが、何年間分のデータを残すとなると、積もり積もって相当なデータ量になっていきます。
センサデータを保存するためのテーブルは1つ( 単一テーブル )で、いわゆる分割はしていません。
ちなみに最初期は、「DynamoDBで時系列データベースを構築するベストプラクティス」の中で紹介されているように、データの期間によってテーブルを分けていました。ただし、紆余曲折があって単一テーブルに戻しました。詳細は本筋から外れるので、もし興味があれば下記の(補足)をご覧ください。
(補足)ベストプラクティスをやめて単一テーブルにした理由
以下の3つの理由によるものです。
1. テーブルが分かれることで、データアクセスが複雑になる
テーブルをどう分けるか次第でもありますが、DynamoDBで書き込み/読み取りを行うには必ずテーブル名を指定する必要があるので、書き込みたい/読み取りたいデータに応じて、対象のテーブルを見極める必要が出てきます。
2. テーブル間のデータの移動の作り込みが必要になる
例として、ドキュメントで紹介されている、Current Table, Previous Table, Older Tableの3つに分けようとした場合ですが、毎日、データの移動が必要になるはずです。DynamoDBではテーブル名のリネームはできませんので、 "Current Table" を翌日になったら "Previous Table" にリネームするといったことができません。また仮にできたとしても、切り替えの期間にデータアクセスの不整合がないようにすることは極めて難しいと思っています。
さらに、データの移動の際にはキャパシティを消費することになるので、古いテーブルに対してWCUを低く抑えている目的と反してしまいます。一応、バーストキャパシティという仕様があり、プロビジョンしたキャパシティを超えても、過去300秒で未使用分であればそこから消費することができますが、限度があります。
3. キャパシティの使用効率に関して分けるメリットが薄い
元々アクセスが少ないのであれば、そもそものキャパシティの消費も少ないので、テーブルをあえて分けてキャパシティを別管理にするメリットが薄いかなと思っています。
テーブルを分ける場合と比較して、1つのテーブルで運用する際に意識しないとならないのは、パーティション分割と、それによるキャパシティ容量の配分かなと思います。この点に関しては、パーティション間でキャパシティの融通を行う仕組みである「アダプティブキャパシティー」が即時利用可能になったことで、現時点ではほとんど解消されているのかなと思っています。
DynamoDBのストレージコスト
DynamoDBのストレージは事前にプロビジョンする必要がなく、自動的で無制限にスケーリングしてくれて便利なのですが、ストレージの容量単価はS3などと比べても高めになっています。
今回のセンサデータテーブルは、Standard-IA[1]が発表される前から運用していたテーブルで、容量単価で見るとS3と比較して約10倍高いです。なお、今でこそStandard-IAクラスがありますが、それでもS3標準クラスと比較して4〜5倍ほどの料金です。
| ストレージ | 料金(GB-月あたり) |
|---|---|
| DynamoDB Standard テーブルクラス | 0.285USD |
| DynamoDB Standard-IA テーブルクラス | 0.114USD |
| S3 標準 | 0.023USD〜0.025USD |
定期的に見直しを行っているコスト最適化の取り組みの中で、色々なコスト要因のうち、DynamoDBのストレージコストが目立つようになってきました。
なぜかというと、プロダクトの要件上、古いデータも残しておく必要があったためです。そのため、前月分のストレージコストは当月そのまま課金され、その上に新たに登録された分のストレージコストが上乗せされるという、座布団式にコストが積み上がっていく状態になっていました。
要件
こうして、機能面(ユーザーが利用する画面)に影響を与えずに、DynamoDBのストレージコストを現状よりも安く抑える方法を検討することになりました。
検討にあたって注目すべき特性は、データに対する参照の局所性です。
時系列データとしての例に漏れず、 新しいデータの方がアクセスが多く、古いデータはアクセスが少ない という傾向があります。特に、 車のリアルタイムな位置や車速など、最新1件+αのデータへのアクセス頻度が極めて高い という特性があります。
これらの事情から、データを以下の3種類に分類しました。
- ホットデータ(最新1件+αのデータ)
- ウォームデータ(当日〜1週間くらいに発生したデータ)
- コールドデータ(上記よりも古いデータ)
必然的にこの中でデータ容量を多く占めることになるのはコールドデータです。
コールドデータの場合は、読み取りの応答速度(レイテンシ)については少し妥協ができます。DynamoDBは1桁ミリ秒の応答速度を謳っているサービスですので、同じレベルは難しそうです。とは言え、1秒以上かかるようだと100倍以上の性能低下となってしまうのでさすがに遅すぎると言えます。今回はその中間あたりを目指しました。
また他の要件として、サービス影響を与えずに移行できることも目指しました。センサデータテーブルは、既存のテーブルであり、我々のプロダクトにおける中心的なテーブルでもあるためです。
移行に伴う対応工数が少ないことと、データ側ではなくアプリケーション側、つまり、アクセスを行うクライアント側のコードの変更が局所化できるようにする点も留意することにしました。
アーキテクチャ
最終的に、以下のようなアーキテクチャで設計し、運用しています。
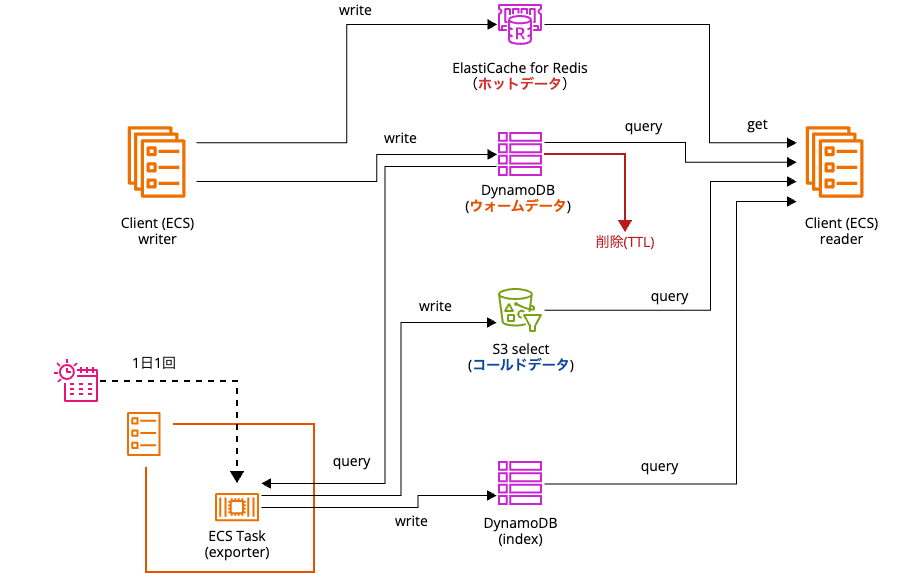
ホットデータ用のデータストアとしてElastiCache for Redis、ウォームデータ用のデータストアとして現行と同じキー設計のDynamoDB、コールドデータ用のデータストアとしてS3を採用しました。
ホットデータ用のRedis
ホットデータについては、ElastiCache for Redis(以下、Redis)を使用しています。
writerが新しいデータを追加する際には、RedisとDynamoDBテーブルの両方に同じデータを書き込みます。
reader側では、Redis内にデータがあればそのまま参照し、なければDynamoDBをクエリします。
応答時間だけであればDynamoDBでも許容範囲なのですが、一段Redisをかませているのにも理由があります。前述の通り、最新1件のデータに対するアクセス頻度は極めて高いので、DynamoDBの場合の読み取りキャパシティがその都度消費されてしまうと、必要な読み取りキャパシティのコスト観点で厳しいためです。
Redisのデータ型は、「ソート済みセット型」を使っており、タイムスタンプをスコアとすることで最新N件のデータが保持できるようにしています。単純な文字列型でないのは、最新のデータとそれより前のデータを使って、車の進行方向の推定、移動距離の算出、異常値のフィルタや補正等を行うためです。また、データ遅延が発生した時に、過去のデータで新しいデータを上書きすることがない役割も兼ねています。
コールドデータ用のS3 Select
今回のアーキテクチャの設計にあたって、まず最初に決めたのは、コールドデータの保存方法・クエリ方法でした。データを間引かずに保存することにしていたため、圧縮やデータ構造の見直しをしないのであればデータの総量は変わりませんから、元のDynamoDBよりもストレージ容量単価の安いサービスを採用する必要があります。
S3については、今更紹介するまでもないかもしれませんが、安定性もあり、コストパフォーマンスにも優れたオブジェクトストレージサービスです。さらに、ライフサイクルを利用してより安価なストレージクラスへの変更も検討できるなどの今後の改善の余地も残しておくことができます。
S3には、効率よくクエリを行うための手段としてAmazon S3 Select(以下、S3 Select)が提供されています。
同じようにS3に保存されたデータを抽出する手段としてはAthenaがありますが、今回はセンサデータセットに対しての大規模・横断的な分析ではなく、特定のデバイスのデータのみをシンプルなクエリで抽出できればよいため、S3 Selectの方が適切と判断しました。事前の検証で、応答速度についても優れていることが確認できたことも決め手です。
S3 Selectを使う上で重要なのは、 一つのファイル(オブジェクト)に対して クエリを発行することになることです。そのため、ファイルが細かく分かれていると、複数のファイルをクエリしないと結果が得られず非効率ですし、取得したいデータ群は1つのファイルに収まっていたほうが好ましいです。
私達のワークロードでは、複数の日付にまたがるようなレンジでクエリする必要が少ないことから、「1デバイス・1日」のデータを1つのファイルに収めることにしました。
ファイルが指定できれば、後は以下のようなSQLを使って、データをクエリすることが可能になります。
select * from s3object s where s.timestamp between '%s' and '%s' limit 1000
S3上のファイルのインデックスとしてのDynamoDBの使用
S3キーは以下のような設計にしました。デバイスIDと日付がわかれば、クエリのためのS3キーが自動的に解決できるようになっています。
/date=2024-03-10/device_id=123456789/data-123456789-2024-03-10.jsonl.gz
ただしここで問題になることがあります。
毎日データが存在するとは限らないので、データが見つからないクエリ条件の時に、ファイルが存在しないためエラーになってしまいます。エラーを握りつぶすなり、事前にファイルの存在チェックを行うといった対策をしなくてはなりません。
また、「2024/03/10 10:00:00以前のデータを降順に1000件クエリしたい」といったクエリ条件の時に、ピンポイントで必要なファイル群を探し当てることができません。
上記の問題に対する解決策として、インデックステーブルを作ることにしました。
テーブルの構造は以下のようなものであり、デバイス・日ごとに、センサデータが何件あるのか、その日の最小(最早)のタイムスタンプ、最大(最遅)のタイムスタンプを管理するテーブルです。
| device_id | date | count | min_timestamp | max_timestamp |
|---|---|---|---|---|
| 123456789 | 2024-03-10 | 2345 | 09:00:10.000 | 18:00:00.000 |
このインデックステーブルによって、色々なタイムレンジとLIMITでクエリがリクエストされた時でも、どのファイルに対してS3 Selectでクエリすればよいのか、解決できるようにしています。
インデックス作成とDynamoDBからS3へのデータ移動
インデックステーブルを使うからには、インデックスを登録する処理が必要です。
この処理は、ECSスケジュールタスクで1日1回、DynamoDB(ウォームデータ)からデータをクエリし、インデックステーブルへのインデックス情報の登録と、S3上へのファイルアップロードの両方を行うようにしています。
アーキテクチャにおける以下の部分です。
DynamoDBから古くなったデータの削除は、TTLで自動削除するようにしています。
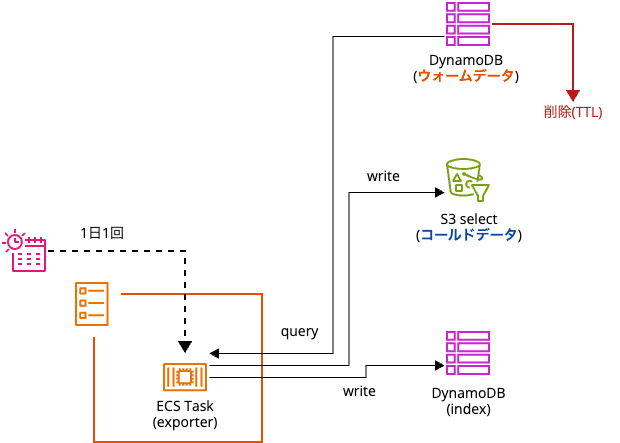
データの移動に関しては、EventBridgeスケジューラー + ECS + Fargateを使っていますが、それ以外の選択肢も考えられるかと思います。例えば、DynamoDB Streams + Lambdaだったり、変更データキャプチャ + Kinesis Data Streams + Data Firehoseあたりでした。
これらのフルマネージドなサービスから、あえて手間を増やしてスケジュール済みタスクを採用したのには、次の理由があります。
DynamoDB Streamsや変更データキャプチャを使った場合、S3 Selectで扱いやすいための「1デバイス・1日」ごとのファイルとして出力することが難しいと考えたためです。TTLによる項目の削除は、設定した時刻ぴったりに削除されるわけではなく、「有効期限になったら数日以内に」行われるとしか説明されていないため[2]、「同じデバイス・同じ日付」のデータが削除されるタイミングをコントロールできません。
読み取り
データストアを複数に分けたので、読み取り側では、クエリ条件に応じて、DynamoDB(ウォームデータ)とS3(コールデータ)のどちらから読むべきかを決める必要があります。
DynamoDBとS3のどちらを見るべきかについては静的に評価し、S3内のどのファイルを参照するかについては前述の通り、インデックステーブルを見て動的に評価する、という方法になっています。
「静的な評価」というのは、クエリ条件のレンジが1週間以内だったらDynamoDB, それより古ければS3といったイメージです。
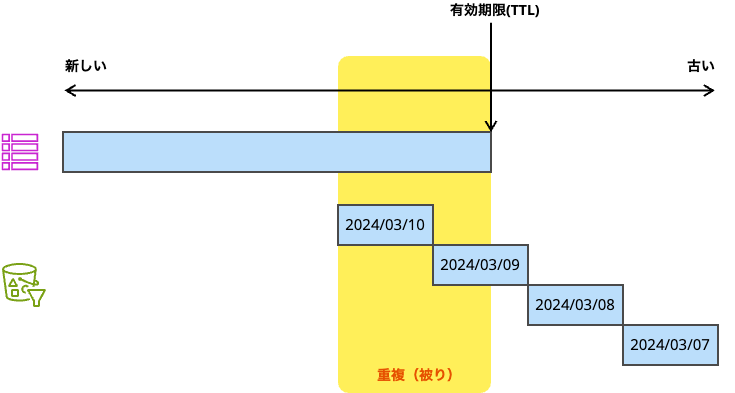
正しい結果を得るためには、場合によっては、DynamoDBとS3の両方からクエリが必要になる時もありますが、上記のルールの組み合わせで対応することが可能になっています。
今回のアーキテクチャでは、TTLで削除したデータを移しているわけではなく、DynamoDBとS3の両方に同じデータが存在し得る仕組みになっています。その場合は、クエリ結果に対して結果をマージしていまえば問題なく、こういった「のりしろ」部分があることは、データの送信遅延が日常的に発生するIoTのシステムでは、結果のとりこぼしをなくす上で都合がよかったりもします。
おわりに
巨大な単一DynamoDBテーブルから、S3/S3 Selectを活用したアーキテクチャへの移行についての紹介でした。
最後に「見合った効果はあったのか」「今ならもっとよい方法があるのではないか」の観点で、ふりかえってみます。
見合った効果はあったのか?
十分に効果のある取り組みになったかなと思います。
検討をはじめてから開発・テスト完了まで3週間くらいだったので、時間が経つほどその恩恵は大きくなってきます。
すごく単純な例ですが、日々追加されるデータ量のペースが一定と仮定した場合、移行前のDynamoDBのみの場合は、DynamoDBのストレージ単価に比例してコストが増えていきます。今回のアーキテクチャの場合は、追加される量と同じペースのデータがTTLによってDynamoDBからは消えていくことになるので、DynamoDB側のデータ量はほぼ一定になります。時間経過で増えていくのはS3に保存されていくコールドデータのストレージ料金ですが、この伸び方はDynamoDBと比べて約1/10であり、ずっと緩やかになります。
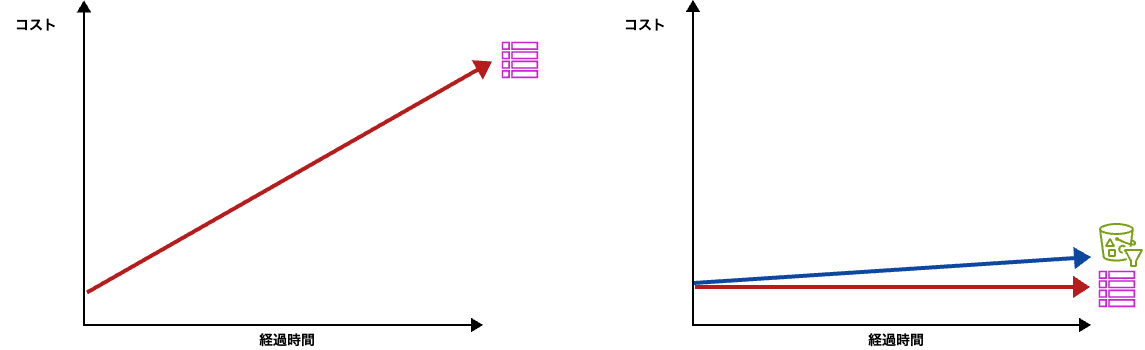
(左)DynamoDBのみの場合、(右)DynamoDB+S3
ただし、今回のアーキテクチャでは、インデックス用のDynamoDBテーブルの容量や読み書きキャパシティ、S3のPUTコストなどが追加で発生しています。これらはストレージコストと比べた時に相対的に無視できるくらいには小さいものでした。
複雑にしすぎて保守コストが増えても本末転倒なのですが、運用をはじめて3年ほど経過しても、トラブルはほとんどなく、保守コストもほとんどかけずに運用ができています。
今後に向けて、当時なかった新たな選択肢を考察してみる
今回紹介したアーキテクチャは、2020年頃から本番稼働させているものです。よく言えば、十分な運用実績があるものですが、zennに書く記事としてはやや古いネタでもあります。
紹介してみようと思ったきっかけは、Zendeskの事例として、DynamoDBからMySQLとS3を使用した構成に移行することで、データストレージのコストを80%以上削減した事例が紹介されていたことでした。
※ 元の記事はこちら
この記事でフォーカスされているのがS3 SELECTで、私達も数年前から、同じようなモチベーションで、共通するアイディアも含まれていたため、ちょうどよいこのタイミングで紹介しました。
AWSは日々アップデートしており、それによって、新しい選択肢も日々増えていきますし、ベストプラクティスも変わることがあります。「2024年の今設計するなら?」という仮定で、新たな可能性を考えてみます。
Amazon Timestream
AWS上での時系列データベースといえば、今ではAmazon Timestreamがあります。今、新しいプロジェクトで時系列データベースを扱う場合では選択肢の筆頭になるでしょう。
気になるストレージコストに関しても、古いデータはマグネティックストアに自動的に移動することができ、その料金もDynamoDBと比較して安く、ストレージ容量の問題も少なめとなります。
東京リージョンにやって来たのが2022年と比較的新しく、当時は選択肢にありませんでした。
発表されたのは2018年のre:Inventだったので、待っていたのですが、なかなかやって来なかったんですよね…。
Zero-ETL
ここ最近のトピックスでは、DynamoDBからOpenSearch, Redshiftへのzero-ETLが発表されました[3][4]
今回のアーキテクチャでは、インデックステーブルの作成、DynamoDBからS3への移動、透過的な読み取り処理の3箇所で、カスタムの開発を行っています。
特に前2つについては、こういったマネージドな仕組みに乗せることで、もうちょっと楽になるかもしれないと考えています。
今のところ、DynamoDBにて対応が発表されているのがOpenSearch Service, Redshiftの2つだけであり、現状はまだマッチしない段階ですが、この領域はAWS的にも力を入れていそうですので、新しいアップデートへの期待も込めて動向に注目していきたいと思います。
参考文献
アーキテクチャを考える上で、以下の記事を参考にさせていただきました。

Discussion