




FireLens(Fluent Bit)ログドライバを使う際、表題の件でハマったのでその記録です。
設定の勘所
先に結論だけ書いておきます。
cloudwatch_logsプラグインとrewrite_tagプラグインを組み合わせる場合に、ログストリームにタスクIDをつけてログストリームを分けたければ、以下の設定をチェックしましょう。
- parserフィルターでは
Reserve_Data Onを明示的に付けて、ログレコードからcontainer_idフィールドが捨てられないようにしておく( 重要 ) - rewrite_tagフィルターでは、書き換え後のタグに
$container_idを含めるようにする。 - cloudwatch_logsプラグインでは、
log_stream_nameではなくlog_stream_prefixを利用して、タグ名がストリーム名の一部になるように指定する。
やりたいこと
以下のような定番のECS + Fargateの構成でのログ基盤です。
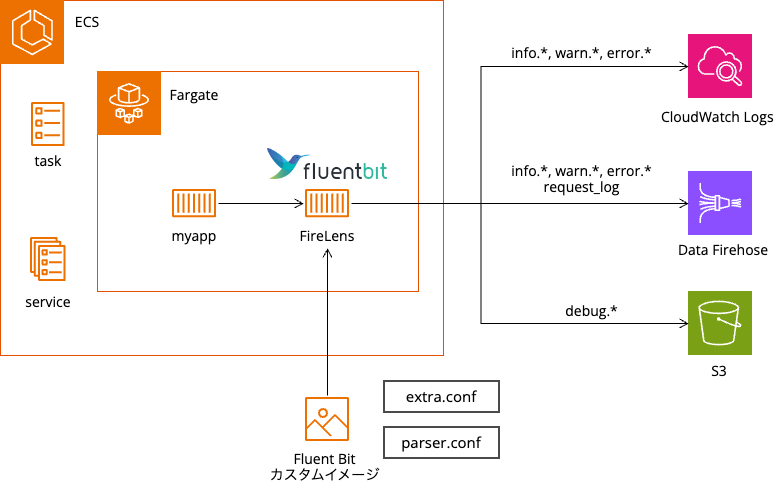
- アプリケーションはJavaで、ログ出力はSLF4J + Logback
- アプリケーションログは以下の通りのルーティング(実際はもうちょっと複雑ですが…)
- アプリケーションログ(INFOレベル以上) => CloudWatch Logs + Firehose
- アプリケーションログ(DEBUGレベル) => S3(直接)
- リクエストログ => Firehose
- CloudWatch LogsはタスクIDごとにストリームを分ける
- Fluent Bitはカスタムイメージを利用
設定ファイル (extra.conf)
最終的に作成した設定ファイルは以下のようになりました(ポイントとなる箇所だけ抜粋しています)
[SERVICE]
Flush 1
Grace 30
Parsers_File /fluent-bit/etc/parsers.conf
[FILTER]
Name parser
Match *-firelens-*
Key_Name log
Parser application_log
Reserve_Data On
[FILTER]
Name rewrite_tag
Match *-firelens-*
Rule $level ERROR error.$container_id false
[FILTER]
Name rewrite_tag
Match *-firelens-*
Rule $level WARN warn.$container_id false
[FILTER]
Name rewrite_tag
Match *-firelens-*
Rule $level INFO info.$container_id false
[FILTER]
Name rewrite_tag
Match *-firelens-*
Rule $level DEBUG debug.$container_id false
[FILTER]
Name rewrite_tag
Match *-firelens-*
Rule $method ^.+$ request_log false
[OUTPUT]
Name cloudwatch_logs
region ap-northeast-1
log_group_name {CloudWatchロググループ名}
log_stream_prefix application_log/
Match_Regex error.*|warn.*|info.*
Retry_Limit 5
[OUTPUT]
Name kinesis_firehose
region ap-northeast-1
Match_Regex error.*|warn.*|info.*|request_log
delivery_stream {Firehose配信ストリーム名}
Retry_Limit 5
[OUTPUT]
Name s3
region ap-northeast-1
Match debug.*
bucket {ログを保存するS3バケット名}
total_file_size 10M
upload_timeout 10m
use_put_object On
compression gzip
s3_key_format /myapp/application_log.debug/%Y/%m/%d/%H/${APP}-$TAG-%Y-%m-%d-%H-%M-%S-$UUID.gz
retry_limit 5
ハマった点を説明していきます。
CloudWatch Logsへ送信するプラグインには2種類ある
CloudWatch Logsにログを送信するためのOUTPUTプラグインには2種類あります。
2種類のプラグインの解説はクラスメソッド様の記事が詳しいのでそちらを参照ください。
便宜上、記事に倣って、Name = cloudwatchのものを旧プラグイン、Name = cloudwatch_logsのものを新プラグインと呼びます。
紹介されている通り、新プラグインの方では、ECSメタデータの変数がサポートされていないため、 log_stream_nameに$(ecs_task_id)のような変数を使ってストリーム名を展開することができません。
ただし、新プラグインの場合でも、log_stream_nameではなく log_stream_prefixを使うことで、タスクIDをログストリーム名に含めることができます 。
FireLensから出力されるログレコードは <コンテナ名>-firelens-<コンテナID> というタグが付けられており、 log_stream_prefix はマッチしたタグ名にプレフィックスを付与してログストリーム名とするオプションです。タグにはコンテナIDが含まれているので、ストリーム名にそのままタグが使えれば、そのままログストリーム名も分けることができる、というわけですね。
例えば下記のように定義した場合、ロググループ( /aws/ecs/myservice )にログストリーム( app-<コンテナ名>-firelens-<コンテナID> )が作成されます。
[OUTPUT]
Name cloudwatch_logs
Match *-firelens-*
region ap-northeast-1
log_group_name /aws/ecs/myservice
log_stream_prefix app-
auto_create_group true
rewrite_tagを使うと、タグの情報が失われる
タグの書き換えをしていなければ、上記の内容だけで何も問題がないのですが、rewrite_tagフィルターと組み合わせて使う場合、少し工夫が必要です。
まずrewrite_tagフィルターについてですが、Ruleとして定める条件に合わせて、タグを書き換えることができるプラグインです。ログ出力のルーティングにおいては、定番プラグインなんじゃないかなと思います。
その名の通り、タグ名を書き換えることになるので、元々のタグに含まれていたコンテナ名やコンテナIDが消えてしまうわけですね。
書き換え後のタグにcontainer_idを付与する
そこで、書き換え後のタグにコンテナIDを含める方法が必要になります。
といっても、そんなに特別なことは必要なくて、FireLensログドライバを使用すると、いくつかのフィールドを自動で付与してくれるようになっています。
具体的には以下のフィールドです。container_idがあるので、これがそのまま使えそうです。
- ecs_cluster
- ecs_task_arn
- ecs_task_definition
- container_id
- container_name
- ec2_instance_id (起動タイプがEC2の時のみ)
というわけで、書き換え後のタグには以下のように $container_id として参照させればOKです。
[FILTER]
Name rewrite_tag
Match *-firelens-*
Rule $level ERROR error.$container_id false
container_id, container_nameを参照するためにReserve_Data Onをつけよう
上記の設定まではすんなりたどり着くことができましたが、ここが一番ハマったところです。
実際に出力されるログをみて、 container_id, container_name の2つのフィールド だけ がなぜか出力されていませんでした。
container_id が出力されていないと、 $container_id として展開したい箇所が空白のままとなり、以下のような尻切れのストリーム名になります。

試行錯誤した結果、どうやら、ParserフィルターにReserve_Data Onをつける必要があることがわかりました。
[FILTER]
Name parser
Match *-firelens-*
Key_Name log
Parser application_log
# コレ
Reserve_Data On
このパラメータは何かというと、Parserフィルタープラグインのマニュアルに、以下の通り説明されています。
Keep all other original fields in the parsed result. If false, all other original fields will be removed.
ここでの "original fields" というのが何を指しているのかですが、少なくとも container_id, container_name の2つをログの設定内で参照する時には、明示的に Reserve_Data On オプションを指定しておく必要があるようです。
指定をしなくても ecs_cluster, ecs_task_arn, ecs_task_definition の3つは出力されていたので、なかなか気づきませんでした。
補足) コンテナID = タスクID?
余談ですが、コンテナID[1]とタスクIDというのは、厳密には別物です。
1つのタスクには、複数のコンテナが含まれます。
例えば今回の構成では、アプリケーションコンテナとFluent Bit(サイドカー)コンテナの2つですね。
コンテナIDは、タスクIDに加えて、各コンテナを識別する番号を連結した文字列になっています。
ただ「ログストリーム名をタスクIDごとに別物にしたい」という今回の要件上は、コンテナIDが使えれば要件を実現できるので、コンテナIDをそのままタグ、ログストリーム名として利用しました。
-
マネージメントコンソール上ではコンテナランタイムIDで呼ばれています ↩︎

Discussion