こんにちは、CareNetのKaiです。
CareNetでは、医療従事者向けの医療教育コンテンツも作成しておりまして、様々な医師の先生方に講師をお願いしております。
そんな中、ライブ講義でホワイトボードに手書きで解説頂いたり、工夫を凝らした手書きの図表を参考資料として頂戴したりすることもあります。
こういった資料はなかなか電子化して構造化データとして取り扱うことが難しかったのですが、手書き文字認識のCloud Vision APIとOpenAI APIの組み合わせで、手書き資料から自動的に要約を作成する仕組みを試してみました。
記事の作成中にGPT4-Vが発表されて、無価値になってしまったかなと思いましたが、GPT4-Vは手書き文字のOCR機能は非常に弱いようで、まだ十分価値がありそうです。
(GPT4-Vでの実行結果は後述します)
Cloud Vision APIについて
正式名称は「Google Cloud Vision API」です。
実はMicrosoftのAzureにも同様のAPIがあるのですが、個人でGASを使っていたのでやりやすい方を試してみました。
両者を比較した記事も拝見しましたが、それほど性能に差もなさそうです。
OpenAI APIについて
改めて説明する必要もないかと思いますが、OpenAIが公開しているAPIですね。
使い方は、公式ドキュメントも充実していますしたくさんの記事がありますので割愛します。

Cloud Vision APIのセットアップ
こちらも素晴らしい記事がありますので割愛します。
Colabの準備
別にGoogle Colabである必然性はありませんが、仮想環境セットアップするのも面倒なので、手癖でいつも使っているColabを使ってみることにします。
以下のセルを実行後に、ランタイムの再起動が必要になるので先に入れておきます。セル実行が完了したらランタイムを再起動してください。
# 実行後にランタイム再起動
!pip install --upgrade google-cloud-vision
Colabで画像を取り扱う準備
とりあえず前準備として、入力画像をColab上で確認します。
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
input_file = '入力する画像ファイルのパス'
img = cv2.imread(input_file)
plt.figure(figsize=[10,10])
plt.axis('off')
plt.imshow(img[:,:,::-1])
Cloud Vision APIの組み込みと実行
では続いて、Cloud Visionを使うための準備と実行です。
こちらはほとんどこちらの記事の写経です。ありがとうございます。
import os
import os.path
import errno
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
cred_path = 'Cloud Vision APIのサービスアカウントキーのパス'
if os.path.exists(cred_path) == False:
raise FileNotFoundError(errno.ENOENT, os.strerror(errno.ENOENT), cred_path)
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = cred_path
これで準備ができたので、実際に叩いてレスポンスを確認します。
import io
from google.cloud import vision
client = vision.ImageAnnotatorClient()
with io.open(input_file, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)
print(response.text_annotations[0].description)
実行結果
実際に社内では講義資料などを読み込んでいますが、本記事ではサンプルとして香川県のゲーム条例に対するパブリックコメントのうち、手書きのものが公開されていましたので、これを使ってテストしてみましょう。
(データソースはこちら)

認識させた結果はこちらになります。

手書きでかすれている文字があったり、スキャンのノイズがあったりしますが、予想以上に正確な認識結果が返ってきました。手書き文字の認識結果としては十分だと思います。
ちなみに、GPT4-Vで文字起こしをさせた結果は、以下の通りです。

部分的には何かを読み取れているようですが、とても正確とは言えません。やはり、GPT4-Vは「文字を正確に読み取って認識する」というOCR機能ではなく、全体を絵として解釈することに注力しているようです。
さて、CloudVisionの強さが分かったところで、ここまで正確であれば要約をするまでもないのでは?と思われるかもしれません。
ではここで、2枚目としてこの画像を食わせてみます。
これは私が先ほどの内容をピックアップして、適当に図的に表したものです。私やケアネットの意見を表明するものではありませんのでご注意ください。図がしょぼかったり、字が下手くそだったりするのはご勘弁ください。
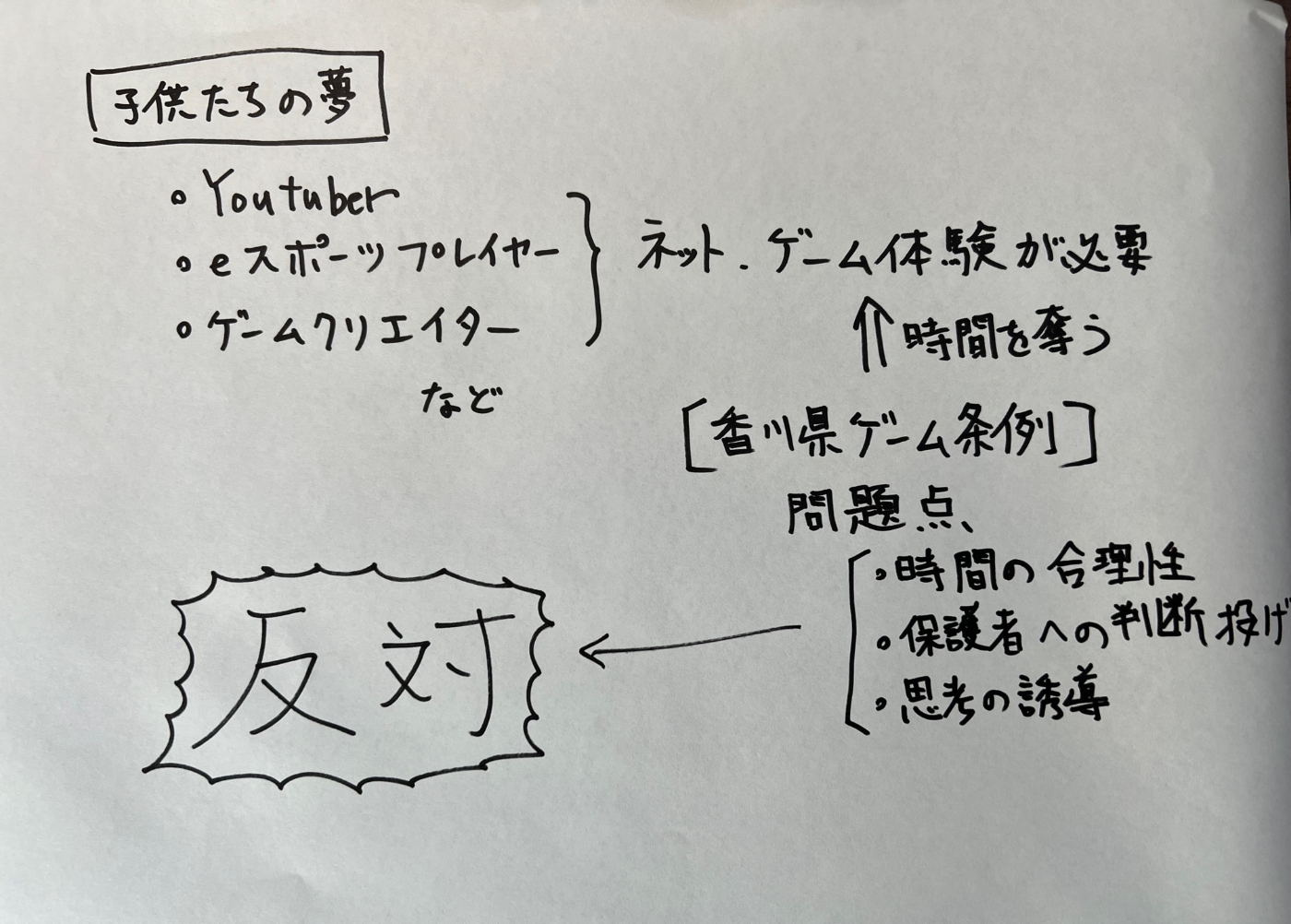
CloudVisionでの実行結果はこちら。
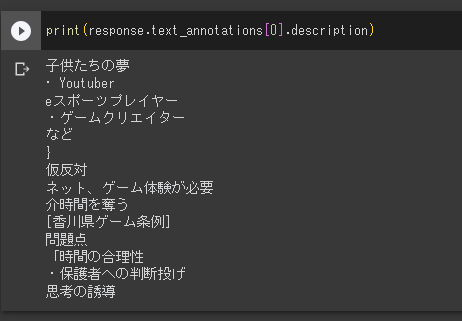
ご覧の通り、「文字の認識」は非常に正確です。
一方、OCRでは、段組みを始めとする構成や、矢印などについては解釈してくれません。そのため、「文字列がバラバラの順番で抽出されるだけ」になってしまいます。
ちなみに、GPT4-Vに直接画像を投げた結果は以下の通りです。もう全然だめですね。

さて、CloudVisionの認識精度が非常に高いことが分かりますが、先述の通りOCRは文字の読み取りに特化しており、画像の領域分割や構成認識は重視しておりません。したがって、「図表」と考えたときに、情報間の関連性を抽出することは困難です。
(画像を領域で分割するタスクは、全く別の画像認識問題として扱われるべきでしょう)
この例ではシンプルな図なので大した問題にはなりませんが、例えば中央省庁が公開しているような細かく情報量の多い資料が、何十ページもあったらどうでしょうか。

こんな資料ですね。バラバラの単語、文章は認識して拾うことができても、読み手が期待する「図表を一貫性のある文章で記述したもの」とはかけ離れたものになってしまうでしょう。
どうしたものかな、と色々考えた結果、汎用LLMにこの文字列を処理させて、意味のある要約として再解釈してもらうのが良いのでは、という結論に至りました。
OpenAI APIの組み込みと実行
仮に、以下のようなプロンプトで処理させてみます。
私の環境ではAPIでGPT-4を使えますが、もしAPIでまだ使えない方は3.5-turboを試してみてください。
# OpenAIパッケージのインストール
!pip install openai
import openai
openai.api_key = 'APIキー'
messages = [
{"role": "system", "content": "次の文章は、ある画像からAIがテキストディテクションしたものです。しかし、元の画像が手書きであったため、誤字脱字や誤認識された文字があったり、本来矢印などで結ばれていた文章同士の情報などが欠落していたりします。その前提で内容を検討し、一貫性のある要約を短い文章で作成してください"},
]
# Cloud Vision APIの実行結果を与えるようメッセージを拡張
messages.extend([
{"role": "user", "content": response.text_annotations[0].description}
])
# GPTに処理依頼
completion = openai.ChatCompletion.create(
model="gpt-4",
messages=messages
)
print(completion.choices[0].message.content)
実行結果は以下の通りです。
子供たちの夢として、Youtuber、eスポーツプレイヤー、ゲームクリエイターなどが挙げられています。これらの職業を目指すならネットやゲームの体験が必要であり、それが多くの時間を必要とすることへの反対意見が存在します。香川県ゲーム条例の問題点として、「時間の合理性」や「保護者への判断委ね」という思考の誘導が指摘されています。
反対の対象を取り違えてしますが、悪くはない、ですね。
情報量が少なすぎるので、一貫性を補完した結果なのだと思います。
今回はシンプルな図表ですのでメリットがあまりありませんでしたが、手書きの込み入ったホワイトボードや図表などを要約させる場合は、役に立ちそうです。
(実際に先生の手書き講義資料を要約したところ、実用レベルのものになっています)
ということで、今回は「CloudVision+LLM」での手書き図表認識→要約の記事でした。LLM、特にGPT系は非常に強力ですが、精度が求められる特定のタスクには不向きなこともあります。そういったケースでは、このように「前処理を別の特化したAIに任せる」「その解釈を高度LLMに行わせる」といった役割分担で精度を向上させる手も有効だと考えられます。
Future Work
こちらやこちらの記事などによると、CloudVisionは認識結果をバウンディングボックスの座標とセットで返せるようです。今回は試しませんでしたが、この情報を駆使すれば、より高度な解析と要約も可能かもしれません。
参考文献

株式会社ケアネットのエンジニアブログです。CareNetサービスの技術情報を中心に記事を投稿しております。 各記事の内容は個人の意見であり、企業を代表するものではございません。
Discussion