はじめに
この記事は『カンリー Advent Calendar 2025』、12月19日分の記事として執筆しています。
📝 既存の Log Index を分析の軸に、Log Patterns でログコストを削減した話
こんにちは、カンリーでSREをしている吉村です。
今回は、既存の Log Index を分析の軸に、Log Patterns で開発チームとログコストを約50%削減した話を書きます。
この取り組みでは、すでに存在していたインデックス構成を「分析の軸」として使い、
- どのログが全体の大きな割合を占めているのかを可視化し
- 削減できそうなログパターンを洗い出し
- 開発チームと一緒に「削ってよいか」を判断する
という流れを回しました。
🧩 前提:新しいインデックスを導入せずにコスト削減に繋げた
もともと、カンリーでは以下のような 環境単位のインデックス構成 が存在していました。
-
production:30 days -
staging:7 days -
development:3 days -
catch-all:3 days
ここで、今回の話の前提になる用語を簡単に補足します。
Log Index(以下、インデックス) は、Datadog に送られてきたログを「どの条件のログを」「どれくらいの期間」「どの用途向けに」保持するかを決める仕組みです。
インデックスを分けることで、
- 環境ごとに保持期間を変える
- 重要度の高いログにコストを集中させる
といった設計が可能になります。
今回は、この すでに存在していたインデックスを“分析の軸”として使った、というのがポイントです。
🤔 背景:ログコスト削減が進まなかった理由
ログコスト削減の話をすると、次のような状態になりがちでした。
- 「ログが増えているのは分かるが、どこから手を付ければいいか分からない」
- 「このログ、削っていいものなのか判断できない」
- 「開発時の意図を崩してしまうのが怖い」
多くの場合、ログ自体は 「開発当時は必要な意図があって出されている」 ものです。
ただし時間が経つにつれて、
- 当初の設計意図と現在の運用のズレ
- 実際には参照されていないログの増加
- 「必要そうだから残している」状態の継続
が起こりやすくなります。
つまり、問題はログの意図を誰も分かっていないことではなく、「今の運用に照らして削減してよいかどうかを判断する材料が不足している」 ことでした。
そこで、削減の是非を感覚ではなく事実ベースで判断できるようにするため、
既存インデックスを起点に Log Patterns を使った分析を行うことにしました。
📐 80-20の法則(パレートの法則)をログに当てはめる
ログ分析で意識したのは、80-20の法則です。
全体の成果(コスト)の80%は、20%の要因(ログ)から生まれている
ログでもこれは顕著で、
- 大半のログ量・コストは、ごく一部のログパターンが占めている
- 細かいログを1つずつ頑張っても、削減効果は限定的
という傾向があります。
そこで今回は、
- まず「全体の上位を占めるログ」だけを見る
- 全体量に対して1%未満のログ(いわゆる tail)は追わない
という方針で進めました。
🔍 インデックス × Log Patterns で「上位を占めるログ」を特定する
Log Patterns は、Datadog がログを自動的にリアルタイム分析し、メッセージの共通点をもとにパターン(クラスター)として可視化してくれる機能です。
この画面を見ることで、
- 大量のログを1件ずつ読まなくても
- どのログパターンが大きな割合を占めているかを一目で把握でき
- 異常や違和感のあるログに素早く当たりを付けられる
ようになります。
最初に行ったのは、production インデックスを中心に Log Patterns を実行することです。

Logs > Log Explorer > Group into[Patterns]
ここで見たかったのは、次のようなログです。
- 件数が非常に多いログパターン
- メッセージがほぼ固定で、情報密度が低いログ
- 個別イベントを本当に追う必要があるのか怪しいログ
インデックスが環境単位で分かれていたことで、
- 「production の中で、どのログが上位を占めているか」
- 「このログは production 30days で持つ必要があるのか」
を、環境の文脈込みで把握できました。
📊 Log Patterns で見えてきたログの傾向
Log Patterns による分析の結果、特定の batch ログがログ全体の中で量的に大きな割合を占めていることが分かりました。
- 特定の batch が インデックス全体の中でも上位を占める
- その中でも、単一メッセージパターンがかなりの割合を構成
さらに Log Patterns を深掘ると、
- メッセージ内容がほぼ固定
- 処理単位が per-item で大量に出力されている
といった特徴が見えてきました。
🗣️ まずは相談ベースで、開発チームに持っていく
ここで意識したのは、「不要なログを削ります」ではなく「一緒に考えさせてください」 というスタンスです。
実際に投げたのは、こんな相談でした。
このバッチログ、多くて…
なんとか一緒に減らせませんか?🙏
できるところからで大丈夫です🙏
提示した情報は、以下の3点だけです。
- 件数・占有率(どれくらいの割合か)
- 実際のログ内容(サンプル)
- どの処理単位で出ているか(per-item など)
これだけで、感覚論ではなく具体ベースの会話ができるようになりました。
🧠 ヒアリングで分かったこと
開発チームとの会話で、次のことが分かりました。
- per-item の詳細ログが大量に出力されている
- 実運用では 個別ログを1件ずつ追うことはほぼない
- 障害時は error / warn ログがあれば十分
つまり、
「ログとしては出ているが、実際には頻度高く見ていない」
状態だった、ということです。
🤝 合意できた削減方針
最終的に、次のような判断で合意できました。
- この batch ログは 必須ではない
- 処理単位をまとめたログに集約できる余地がある
- コード修正がすぐに難しい場合の選択肢として、Datadog の Exclusion Filters を使ってインデックス対象から除外する方法もある
Exclusion Filters は、ログの送信自体は止めず、インデックス・課金対象からのみ外せるため、「まずは相談ベースで整理するための選択肢」 として話題にしやすいものでした。
ここで特に大事だったのは、SREが一方的に削ったわけではなく、Log Patterns による可視化をもとに、開発チーム自身が「これは減らせそうだ」と判断できた状態を作れたことです。
📉 結果:ログコストを約50%削減
この流れを回した結果、
- 全体の上位を占めていた不要ログの削減
- per-item で出ていた batch ログの見直し
- ログ量そのものを減らす方向での合意形成
が進み、ログコストを約50%削減できました。
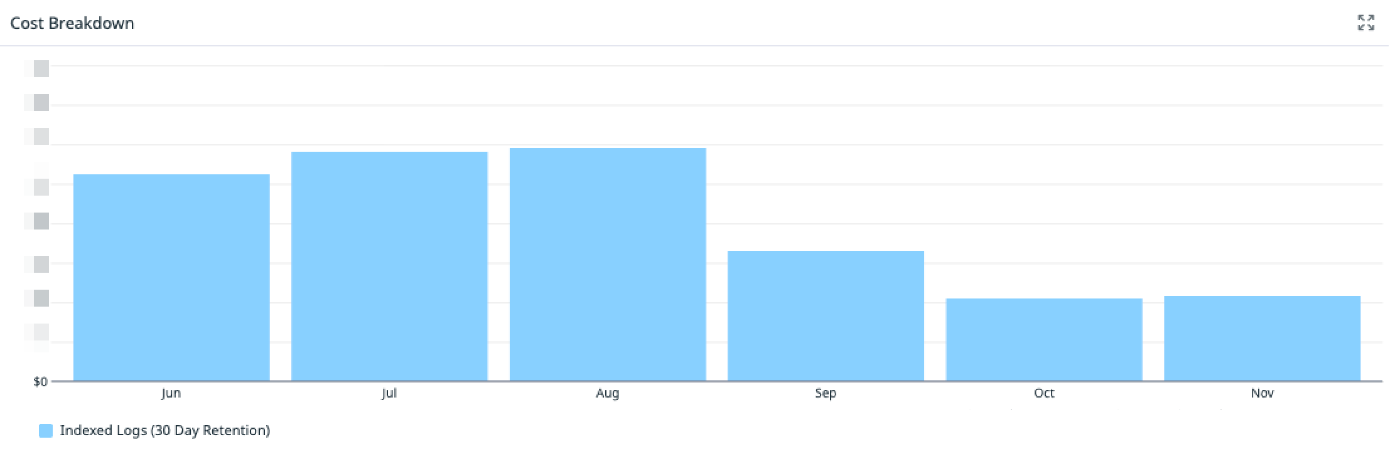
具体的なコストは表示できませんが、2025/08からIndexed Logsのコストが50%削減していることがわかります。
🔁 削減効果を維持するためにやっていること
今回の取り組みは、一時的にログを減らして終わりでは意味がありません。
Log Patterns で見つけたような
**「気づかないうちに増えていくログ」**が再び積み上がらないよう、
“増え始めた瞬間に気づける状態”を作ることを意識しています。
そのために、次のような運用を入れています。
-
Log Index Usage に対する Anomaly Monitor
インデックス単位で使用量を監視し、想定外にログ量が増え始めたタイミングを早期に検知しています。 -
Estimated Usage メトリクスに対する Anomaly Monitor
日次・週次の使用量推移をもとに、「いつもと違う増え方」を Datadog の異常検知で検出しています。 -
Log Patterns による定期的なログ構成の見直し
新しいログパターンが増えていないか、
また「以前は必要だったが現在は不要になっているログ」が含まれていないかを定期的に確認しています。
こうして、
- 「気づいたらまた増えていた」
- 「いつの間にかコストが元に戻っていた」
という状態を防ぎ、
今回削減できた状態を“維持できる運用”として定着させています。
✍️ まとめ
今回の取り組みで一番大きかったのは、
ログコスト削減が「お願い」ではなく「判断」になったことです。
- 既存インデックスを分析の軸にする
- Log Patterns で「上位を占めるログ」を可視化する
- 開発チームと一緒に削減可否を決める
この流れを作るだけで、ログコスト削減は現実的に前へ進みます。
ログを減らすこと自体が目的ではなく、必要なログにきちんとコストを使う状態を作ることがゴールです。
今後も、信頼性とコストのバランスを取りながら、SREとして継続的に改善していきたいと思います。
ご精読いただきありがとうございました。
次の記事でまたお会いしましょう。

株式会社カンリーは「店舗経営を支える、世界的なインフラを創る」をミッションに、店舗アカウントの一括管理・分析SaaS「カンリー店舗集客」の開発・提供、他複数のサービスを提供しております。 技術系以外のnoteはこちらから note.com/canly
Discussion