はじめに
みなさんのチームは、開発生産性を計測していますか?
私達のチームではベロシティを指標とし開発生産性を相対的に計測しています。
ベロシティとは?
スクラム チームが特定の期間 (通常は 1 スプリント) 内に完了できる作業量を見積もるために使用されるアジャイル指標
引用:https://www.atlassian.com/ja/agile/project-management/velocity-scrum
前クオーターのとあるスプリントレビューでベロシティを振り返っていると
なんと、前のクオーターの2倍以上になっているスプリントがあるではありませんか!!??
この記事では約半年ほどを振り返り、アウトプットを最大化するために開発サイクルの中でどの様な工夫をしたか、具体的な流れやプロンプトを紹介しようと思います。
前提
私たちのチームはスクラム開発を採用しており、2週間スプリントを基本単位として開発を進めています。
スプリントごとに計画 → 実装 → レビュー → 振り返りを回し、定期的に改善を行うことで、プロダクト価値を継続的に高めることを目指しています。
冒頭に出てきた「ベロシティ」は、こうしたスクラムの文脈を前提にしたものです。
具体的な改善アプローチ
1. 情報の集約と自動化によるプロジェクト管理工数の削減
もともとドキュメントの管理場所は、統一されていませんでした。
- ADR、ユーザーストーリー、PBI →
Notion - 開発者のタスク、スプリント番号・期間の管理 →
Backlog - 課題/負債の管理 →
Googleスプレッドシート
...などなど、情報が複数サービスに散らばっていましたが、それらをNotionに統一し、プロジェクト管理の効率化を図りました。
1-1. 情報を整理して表示し、MTG中の認知負荷を低減
Notionを使っている人にとっては当たり前かと思いますがタスク、Notionはカスタマイズが非常に柔軟にできるツールです。開発タスクのNotionデータベース(以下DB)をMTGの目的ごとにビューや表示するプロパティを変更し、見やすく・使いやすいように整備しました。
例えば
デイリースクラム → ボードビューを用いてスプリントの進捗を確認

スプリントプランニング → タイムラインビューで確認

当時のBacklogでの運用では柔軟なビュー切り替えが難しく、複数画面を行ったり来たりする必要があり、プロジェクト管理で必要以上の工数がかかっていました。
1-2. ベロシティ算出の自動化
今までスプリントごとのベロシティやPBIごとの総ポイント数は、Backlog上のポイントを手動で計算してNotionに記載していました。
ですがタスクDB、ベロシティ管理DB、PBI DBをすべてNotionに統一し、それぞれのDBに双方向リレーションを貼って管理し、NotionのFormulaを用いて自動算出できるようにしました。
ベロシティ管理DB

PBI DB

プロジェクト管理担当者からすると、手計算から解放され、集計ミスや報告のタイムラグが減少したことはとても喜ばしいことです。
2. 開発フローでのAI活用
さて、ここからは開発フローにおけるAI活用についてです。
開発フローの中でも、今回は開発時は割愛し、タスク分解・コードレビュー・QAテスト時におけるAI活用について紹介します。

2-1. カスタムスラッシュコマンド
Claude Codeには、カスタムスラッシュコマンドが設定できます。
頻繁に使用するプロンプトをMarkdownファイルとして定義しておき、そのコマンドをターミナル上で呼び出すことでプロンプトが呼び出せるようになります。
私達のチームではPRの変更内容を分析してレビューするコマンドと、そのレビューをGitHub上に投稿するコマンドを定義しました。
レビューのコマンドには
- DDD
- パフォーマンス
- セキュリティ
- 保守性・拡張性
- API設計
- テスト
などの観点からレビューしてもらえるようにしました。
以下がその定義ファイルの一部です。
---
description: "PRの変更内容を分析してレビューします"
args:
- name: "pr-number"
description: "レビュー対象のPR番号"
required: true
- name: "focus-area"
description: "使用方法: /auto-review [PR番号] [フォーカスエリア] フォーカスエリア一覧 (all, ddd, performance, security, maintainability, api, testing, database, logging, specification, design, type)"
required: false
bash: |
#!/bin/bash
# 自動PRレビュー用スクリプト
# 使用方法: /auto-review [PR番号] [フォーカスエリア]
PR_NUMBER=$1
FOCUS_AREA=${2:-"all"} # デフォルトは全体レビュー
REVIEW_FILE=".claude/reviews/pr-$PR_NUMBER-review.md"
mkdir -p .claude/reviews
# PR情報を取得
PR_INFO=$(gh pr view $PR_NUMBER --json title,body,author,createdAt)
PR_TITLE=$(echo $PR_INFO | jq -r '.title')
PR_AUTHOR=$(echo $PR_INFO | jq -r '.author.login')
# レビューファイルの初期化
cat > $REVIEW_FILE << EOF
# PR #$PR_NUMBER レビュー結果
**タイトル**: $PR_TITLE
**作成者**: @$PR_AUTHOR
**レビュー日時**: $(date '+%Y-%m-%d %H:%M:%S')
**フォーカスエリア**: $FOCUS_AREA
---
EOF
# 変更ファイルを取得してレビュー対象を記録
echo "## 変更ファイル一覧" >> $REVIEW_FILE
echo "" >> $REVIEW_FILE
gh pr diff $PR_NUMBER --name-only | while read -r file; do
echo "- \`$file\`" >> $REVIEW_FILE
done
echo "" >> $REVIEW_FILE
# フォーカスエリアに応じたレビューポイントを追加
case $FOCUS_AREA in
"ddd")
echo "## ドメイン駆動設計の観点" >> $REVIEW_FILE
echo "" >> $REVIEW_FILE
echo "### ドメイン知識の配置と整合性" >> $REVIEW_FILE
echo "- [ ] ドメイン知識(ルール/制約)が適切なドメイン層のオブジェクトに記述されているか" >> $REVIEW_FILE
echo "- [ ] ビジネスロジックがエンティティや値オブジェクトの振る舞いとして表現されているか" >> $REVIEW_FILE
:
(略)
:
;;
esac
echo "" >> $REVIEW_FILE
echo "## レビュー内容" >> $REVIEW_FILE
echo "" >> $REVIEW_FILE
echo "### 改善提案" >> $REVIEW_FILE
echo "" >> $REVIEW_FILE
echo "### 良い点" >> $REVIEW_FILE
echo "" >> $REVIEW_FILE
echo "---" >> $REVIEW_FILE
echo "by Claude Code" >> $REVIEW_FILE
echo "レビューテンプレートを作成しました: $REVIEW_FILE"
echo ""
echo "テンプレート生成完了。Claude Codeが変更内容の分析を開始します..."
---
指定されたPRの変更内容を取得し、選択されたフォーカスエリアの観点から実際にレビューを行います。
## 処理の流れ
1. 上記のBashスクリプトでレビューテンプレートを生成
2. PR番号から変更ファイルの一覧を取得
3. 各変更ファイルの内容を読み込んで分析
4. フォーカスエリアに応じた観点でコードレビューを実施
5. 具体的な改善提案と良い点を含むレビューを作成
6. レビュー結果を `.claude/reviews/pr-{PR番号}-review.md` に保存
**重要**: このコマンドは単にテンプレートを生成するだけでなく、Claude Codeが実際にコードを分析して具体的なレビューを行います。
## 使い方
```
/project:auto-review [PR番号] [フォーカスエリア]
```
例:
```
/project:auto-review 1351 ddd
```
このコマンドを実行すると、Claude CodeがPR #1351の変更内容をDDD観点で分析し、具体的なレビューを作成します。
## フォーカスエリア
- `all` - 総合レビュー(デフォルト)
- `ddd` - ドメイン駆動設計の観点
- `performance` - パフォーマンスの観点
- `security` - セキュリティの観点
- `maintainability` - 保守性・拡張性の観点
- `api` - API設計の観点
- `testing` - テストの観点
- `database` - データベース設計の観点
- `logging` - ログ・監視の観点
- `specification` - 仕様との整合性
- `design` - コード設計原則の観点
- `type` - 型安全性の観点
レビューテンプレートは `.claude/reviews/pr-{PR番号}-review.md` に保存されます。
以下のコマンドを実行するとDDDの観点からレビューしてくれます。
/auto-review 1337 ddd
そして出力された結果例がこちらになります。
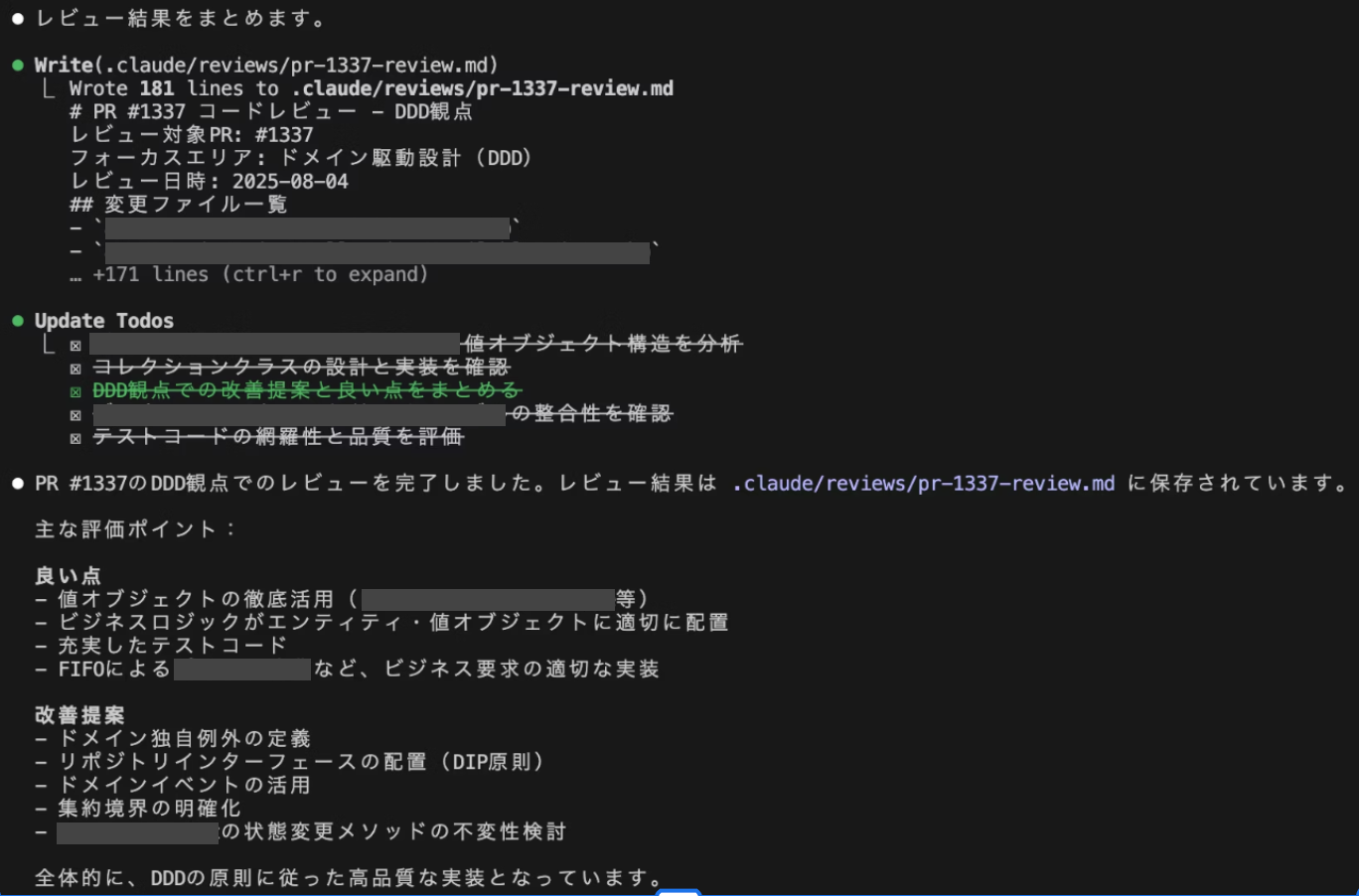
このレビューコマンドがあってもチームメンバー間でレビューし合いますが、その前に実装者自身がAIからの指摘点を振り返り、必要であれば修正してからチームメンバーにレビューをお願いすることにより、レビュアーの負担を軽減することができます。
2-2. ドメインモデル図のPlantUML化
もともとdraw.ioでドメインモデル図を作成しており、開発前・開発途中にドメインモデル図を用いてPdMや開発メンバー間で認識合わせをしていました。
実物なので文字が読める解像度では載せられませんが、このようなものです。
ドメインモデル図の一部
しかし、ドメインモデルをアプリケーションコード上で表現しようとAIにキャプチャを渡しても読み取り精度が低く、うまく機能していませんでした。
そこで、PlantUMLに変換してGitHub上で管理するようにしました。
draw.ioはxmlでエクスポートできるので、そのxmlファイルをClaude Codeを使ってPlantUMLに変換しました。
PlantUMLにすることでAIに読み込ませる際の精度が向上し、ドメインオブジェクト実装の速度と質が大幅に向上しました。
2-3. タスク分解とQAテストケースの草案作成
私たちのチームでは、もともとこれらの作業に多く工数を割いていたのですが、AIに下書きを作成してもらうことで大幅に工数を削減することができました。
タスク分解時のフローは以下です。
PdMから共有されたユーザーストーリーをNotionからExportし、ローカルにmdファイルを置いて以下のプロンプトを実行しています。
以下のユーザーストーリーをタスクに分解し、指定のCSV形式で出力してください。
【ユーザーストーリー】
----------------------------------------
- [ユーザーストーリー](../../user_stories/サンプルユーザーストーリー.md)
----------------------------------------
【出力CSVフォーマット】
- [テンプレート](../../templates/task-listing/)
【フィールド説明】
- 名前: タスク名(日本語、30文字以内)
- スプリント: [スプリント#XX]
- ストーリーポイント: 1,2,3,5,8,13のフィボナッチ数列
- 担当: フロントエンド、バックエンド、アプリ、QA、インフラ、その他
- 状態: 未対応
- ゴール: 具体的な完了条件(100文字以内)を1行で記載
【注意】
- 名前、ゴールには具体的なエンドポイント名・クラス名・ユースケース名ではなく、ユーザーストーリーやドメインモデル図、コンテキストマップに出てくる言葉で記載する
- 最後にテストケース作成、QAテスト実施、リリースのタスクを追加する
- webフロントへ新規機能の実装は含まず、エンドポイントの修正により破壊的な変更が含まれる場合のみタスクを作成する
【タスク分解の粒度】
- 1タスク = 3日以内に完了。8以上は複数タスクに分解する
- ストーリーポイントの見積もりは ../../tickets/タスクDB.csv を参考にする
- APIの追加・修正タスクは設計、ユースケース作成、API実装の3種類で1セットとする
- テストは各タスクのやることに含める
【手順】
1. ../../.outputs/task-listing/ ディレクトリを作成
2. ../../.outputs/task-listing/ユーザーストーリー名.csv を作成する
3. ユーザーストーリー、ADR、docsを参考にタスク分解を行い、名前・スプリント・担当・状態・ゴールを先に記載する
4. 各リポジトリの現在の実装を確認し、ゴールを記載する
- アプリ: ../../../../[Path]
- webフロント: ../../../../[Path]
- モバイルアプリ、webフロント用バックエンドAPI: ../../../../[Path]
- 管理画面: ../../../../[Path]
- 管理画面用バックエンドAPI: ../../../../[Path]
5. すでに実装済の箇所は項目から削除する
6. 手順3-5を5回繰り返し、ユーザーストーリにある仕様の記載漏れがないか確認し、内容をブラッシュアップする
【出力例】
"XXXエンドポイント実装","スプリント#50","3","バックエンド","未対応","XXXを返却できる"
"XX表示コンポーネント作成","スプリント#50","3","アプリ","未対応","XXXが正しく表示される"
【CSV出力】
- ../../.outputs/task-listing/ ディレクトリを作成
- ../../.outputs/task-listing/ユーザーストーリー名.csv に結果を出力
【補足情報(CSV外)】
総ストーリーポイント: [合計値]
推定期間: [日数]
クリティカルパス: [最も重要な依存関係]
このテンプレートを利用すると、いい感じの粒度に分解したタスクの一覧を指定したformat通りのCSVを作成してくれます。
まだアウトプットの品質に対する課題はありますが、「ゼロから全員で考える工数」をAIに担ってもらえる点は大きなメリットだと考えています。
さらなる効率化に向けて
ここまで、情報の集約や自動化によるプロジェクト管理工数の削減、そしてAIを活用した開発フロー改善の取り組みを紹介してきましたが、今後さらに効率化を進めていきたいと考えています。
- QAテストの自動化
- Playwright MCP を活用し、自動テストの仕組みを整備。
- フロントエンドコード生成の精度向上
- FigmaのMCP(Figma-Context-MCP / Dev Mode MCP)の比較検証を進め、リファクタリングや構造化を徹底することで、生成後の手直し工数を削減。
- 複雑化したコードベースの整理
- 一部リポジトリでリファクタリング前後のコードが共存しているのをリファクタリングし、AIがコード生成する際にリファクタリング前のコードが参照されてしまうのを防ぐ。
まとめ
今回私たちのチームは、情報の集約、手動作業の自動化、AIによるコーディング速度と開発サイクルの向上を通じて、ベロシティを向上することができました。
この他にも
- AIプロンプト振り返りMTGを各週で実施し、どんなプロンプトが成果に直結したかを共有
- 3000行以上に肥大化していたOpenAPIをTypeSpecで定義し直して変更容易性と保守性の向上を図る
- コンテキストマップをリポジトリ内で管理してドメイン境界を明確化し、チーム共通認識を強化
など、試行錯誤を繰り返しています。
まだまだ課題はたくさんありますが、今後も「人間とAIの協働開発」を通して会社も個人も成長できるようにいろいろなことに挑戦していきます🚀

株式会社カンリーは「店舗経営を支える、世界的なインフラを創る」をミッションに、店舗アカウントの一括管理・分析SaaS「カンリー店舗集客」の開発・提供、他複数のサービスを提供しております。 技術系以外のnoteはこちらから note.com/canly
Discussion