おはようございます!こんにちは!もしくはこんばんは!
株式会社カンリーのCTO室でエンジニアをしている波多野です。
カンリーでもAI・LLMを活用した生産性向上の機運が高まっています。
その一環で、カンリーではCTO室が主体となりAIエンジニアDevinとClineの検証を進めています。
その中で今回の記事ではDevinの導入検証を行った事例を共有したいと思います!
(Clineについては、別の機会で展開できると良いなと思っています。)
はじめに:Devin導入検証の背景
弊社ではChatGPT, GitHub Copilot, CursorなどのAIツールは各々のメンバーが元々自由に使っておりますが、今回はエンジニア組織全体での生産性向上の取り組みとして動き始めております。
その中で、AIエンジニアDevinの導入検証を開始することにしました。
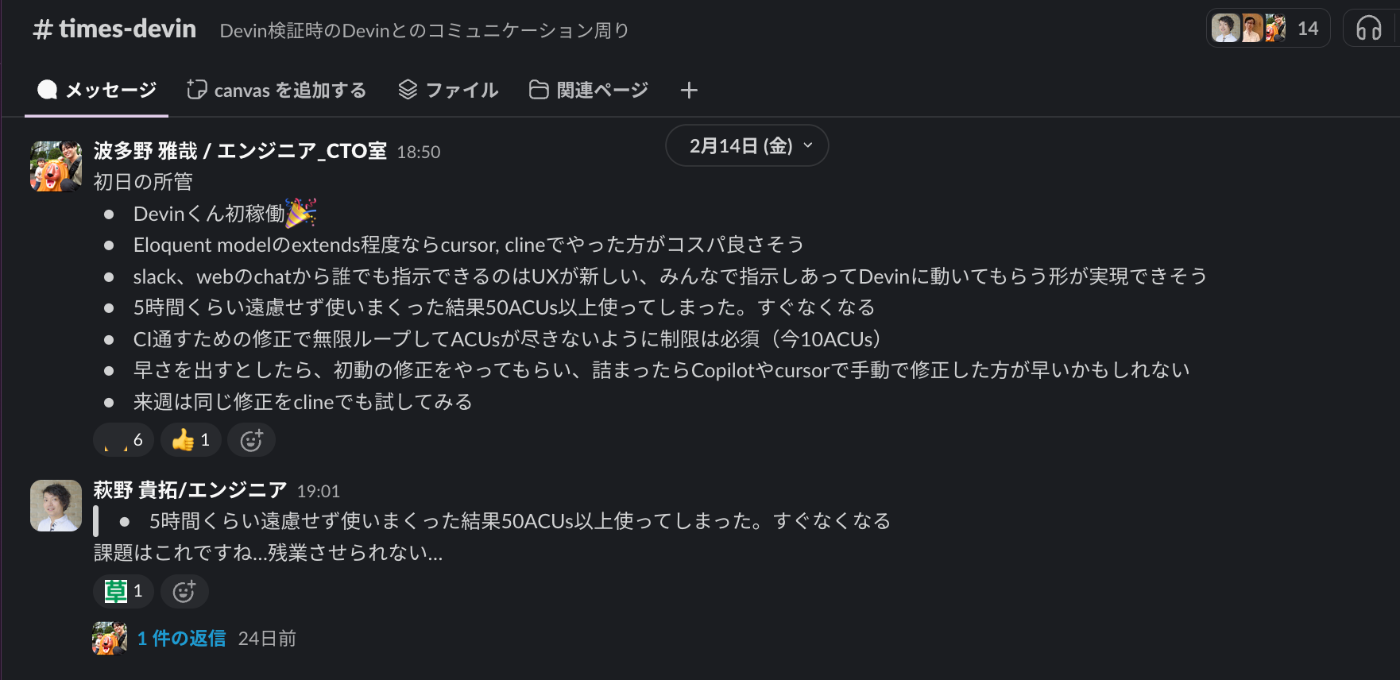 times-devinでDevin君初稼働を報告🎉
times-devinでDevin君初稼働を報告🎉
初日は意気揚々ととにかく手当たり次第使いまくり50ACUsを消費(浪費??)してしまいました、、、
CI改善をタスク選定とする
いくつか検証したタスクはあるのですが、その中で私が担当しているプロジェクトのCI改善を紹介しようと思います。
まだまだ発展途上のプロジェクトで手付かずのこともあり、CIのチューニングが行われずにここまできてしまっていました。
このままではテストケースの増加に伴いCIの実行時間が長くなることは明らかでした。
ただ、まだ7-8分で完了していることもあり、他の機能開発の方が優先度も高く、なかなか手がつけられない状態でした。
高コストな失敗
最初の依頼は非常にシンプルに出しました。
「CIを高速化したいです。CIはこちらです.github/workflows/php-unit-test.ymlまずは高速化するためにどのような案があるのか計画してください。」
この依頼に対して、Devinは複数案と改善までのタスク分解も自ら試みてくれました。
CIの最適化タスクを以下のサブタスクに分解することを提案します:
1. データベース最適化:
- 不要なシードデータを特定し、削除することでテストデータベースのシーディングを最適化
- 独立したシーダーの並列シーディングを実装
- テスト実行間のテストデータベース状態をキャッシュ
2. テストの並列化:
- テストをグループ化するためのテストグループアノテーションを追加
- phpunit parallelを使用して並列テスト実行を設定
- 並列実行設定を測定し、調整
3. 依存関係の最適化:
- キャッシュされた生成コードによるOpenAPIコード生成の最適化
- npmパッケージのキャッシュを実装
- PHPエクステンションのインストールを確認し、最適化
4. ワークフローの最適化:
- ジョブの依存関係とステップの順序を最適化
- テスト結果のキャッシュを実装
- より良い並列化のためのテスト分割を追加
サブタスク1(データベース最適化)から始めることをお勧めします。
理由は:
- 明確なボトルネック(大量のシードデータ)に対処
- 変更は分離されており、測定が容易
- 慎重なテストによりリスクを管理可能
- すべてのテスト実行に即座に利点をもたらす
このセッションでデータベース最適化サブタスクを進めてもよろしいでしょうか?
一瞬でこの方針とタスク分解をやってくれました。ジュニアエンジニアと言われていましたが、思考の筋は良さそうです。
Devinの提案通り、サブタスク1から実行させてみることにしたのですが、サブタスク2のテスト並列化まで進んだのですが、最終的に実装を完了することができませんでした。
元々直列でテストを実行していたため、phpunit parallelを導入するだけでは各テストプロセスでDBが共通になっており、デッドロックが発生していました。
これに対してDevinはテストの並列度を少なくしてデッドロックの可能性を減らすように頑張っていました。。。

並列度を少なくしても普通にCIエラーは出てました笑
この検証では50ACUsを消費した上に別の解決策を見出すことができなかったようです。
CIのエラーを順に解決していたようで頑張った形跡はあったのですが、修正→エラー→検証のループを馬力で繰り返していたようで、この辺りはジュニアなエンジニアっぽいなと思いました笑
DevinにはDefault Session ACU Limit (Since Last Message)という最後のメッセージから設定したACUsを使い切るまで動ける設定があります。
今回10ACUsに設定した上で、数回試行錯誤させたこともあり、ACUsを大量消費してしまいました。
Devinが苦戦してそうな時は後述するような具体的な指示に切り替えた方がよさそうかと思っています。
具体的な指示への転換
ACUを消費し続けてもDevinでは解決できなかったため、具体的な指示に切り替えました。
「github actionsのmatrixを使えばDBを並列化できるのでデッドロックを回避することができますが、それで設計することはできますか?」
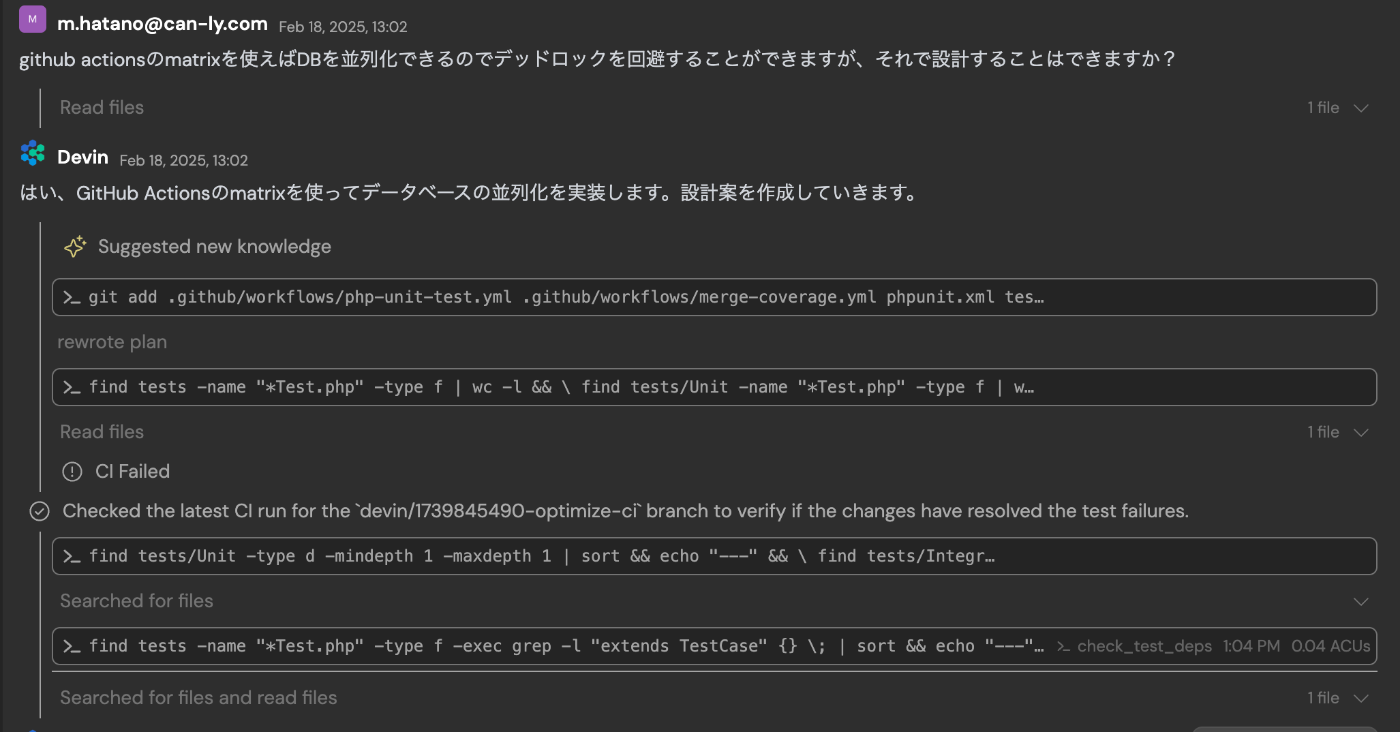 webからDevinのsessionを見るとタスクの動作がさらに詳しくわかります
webからDevinのsessionを見るとタスクの動作がさらに詳しくわかります
この指示を受けて、Devinは以下のような改善プランを提示してきました。
1. テストの分類と整理
- 技術レイヤーごとの分類(UseCases、Services、Repositories)
- テストの依存関係の考慮
- 実行時間のバランス調整
2. GitHub Actions Matrixの実装
- 4つの並列実行グループの設定
- 独立したテストデータベースの構築
- キャッシュ戦略の最適化
実装の詳細
前述の改善プランを承認すると、matrixの利用に合わせて以下のような実装をすぐに行なってくれました
1. データベース環境の整備
-
独立したデータベースの構築
services: db: image: mysql:8.1 env: MYSQL_DATABASE: canly_testing_${{ matrix.group }} -
環境変数の動的設定
env: DB_DATABASE: canly_testing_${{ matrix.group }} DB_HOST: ${{ env.SERVICE_CONTAINER_LOCAL_IP }}
2. テストグループの構造化
テストを以下の4グループに分類:
ut-1: UseCases層のテスト(41ファイル)
ut-2: Services層とコアのテスト(37ファイル)
ut-3: Repositories層とユーティリティのテスト(17ファイル)
integration: 結合テスト
途中で分割の方針をレビューし、指示を与えたところ、4並列への分割を考えてくれました。
3. 実行環境の最適化
テストグループの構造化を進めるタスクで、それぞれのテストをドメインごとに分ける提案をしてくれて、かつテストごとの依存関係やテストの実行時間を考慮して分散して配置するような構成も考えてくれました。
運用の観点で設計が入ることもあり、課題が大きくなるまで採用は後回しにしようと判断し、最終的に採用しなかったのですが、指示+αまで考えてやってくれる点は今後力を発揮しそうだなと感じました。
改善の成果
一連の改善作業を経て、具体的な成果としては下記のようになりました。
具体的な指示に切り替えてから、10ACUsほどでCIの実行時間が半分ほどにできました。
- 改善前:直列実行で約8分を要していました
- 改善後:4つのグループを並列実行することで約4分に短縮
- テストグループ(ut-1、ut-2、ut-3、integration)の並列実行により、実行時間を約半分に
- 各グループが独立したデータベースで実行されることで、テストの信頼性も向上
- データベースアクセスの分散化による競合の解消
- キャッシュ戦略の最適化による処理速度の向上
思わぬ発見:AIエンジニアとの協働
このタスクを通じてDevinの「エンジニアらしさ」を強く感じました。
今回Devinがどこまで自立自走してできるのか検証したいこともあり、CIのキャッチアップを行わずに指示してみました。
結果、いくつもコミュニケーションが必要な点がありましたが、その過程でCIのキャッチアップにもなったという部分は予想外にポジティブな点でした。
自立自走でできてくれればもっと良いとは思いつつも、エンジニアとマンツーでタスクを消化しているような体験でした。
他にも下記のようなタスクを任せてみました。
- OpenAPI, Eloquentの自動生成クラスをそれぞれのModelsでextendsする
- Next.Jsフロントエンド共通コンポーネントの切り出す
- APIのアクセスログのアーキテクチャをコードから調査
- DBテーブルのPK変更
私の印象としては、思考を伴うタスクでもこちらが意図する6-7割の完成度には一瞬で仕上げてくれるという印象です。また、技術的な知見などはDevinはネット上を探しに行ってくれることもあり、ここら辺はさすがといったところです。
ただ解決策の提示やその上り方であったり経験の面は使うエンジニアのサポートが必要という印象でした。
Copilot, Cursorはスケールアップ、Devinはスケールアウト
調査の過程で参加したFindyさんのこちらのイベントからの引用ですが、わかりみが深かったので引用させていただきます!
Devin使ってみてどうだった? ~活用事例と導入時のポイント~
特に、MTGまで時間がない!でも修正する点はわかっているのに!みたいな時は Devinが特に役に立ちます。
Devinに丁寧に指示をしてMTG後にPRをレビューするような使い方は今までにないUXだと思います。
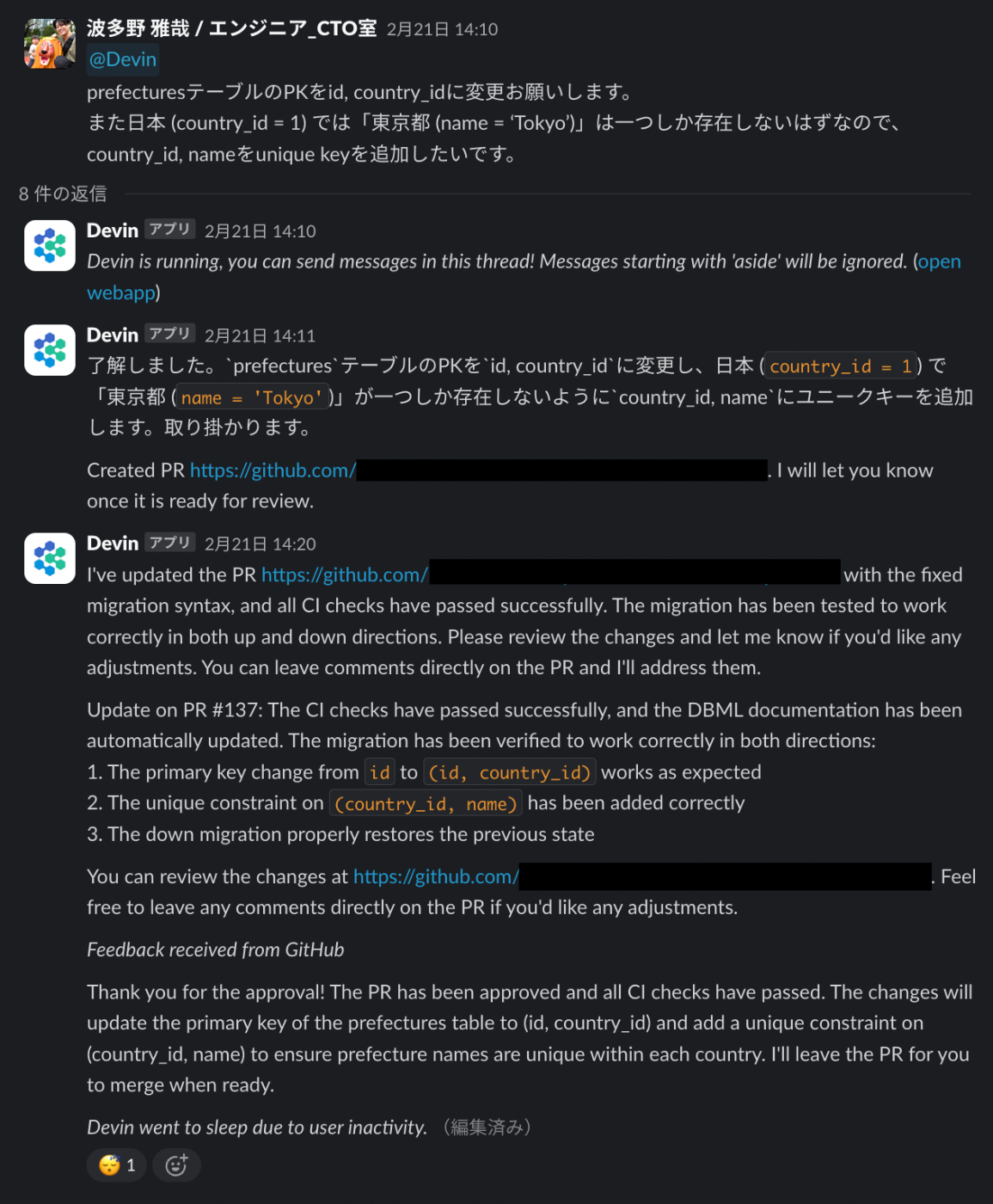 ここまで具体的な指示ならばslackして10分程度待つだけでPRがマージできます
ここまで具体的な指示ならばslackして10分程度待つだけでPRがマージできます
ただジュニアでもできるようにタスク分解して情報を与えることが必要でありますが、Devin公式にも記載されていました。
デヴィンのタスクを評価する
タスクが Devin に適しているかどうかを判断するときに、まず自問すべき質問は、「十分な時間と状況があれば、ジュニア エンジニアでもこれを理解できるだろうか?」です。
この通りであり、このEssential Guidelinesは必読でしょう。
AIエンジニアとしてDevinのコストはどれくらいか?
今までも多くの記事が出ている中では1,200~2,000円/hくらいと言われていると思います。
今回の検証では、1プロセスで6hほど使い、50ACUsほどだったので、その幅には収まっていました。
もちろん使い方によっては上下すると思っていますし、適任のタスクを任せることやモデルの精度によってこれからコストが安くなるのでは?と思っています。
最後に:Devinを使ってみて
Devinを試した結果、他のAIツールとは異なるUXがあり、一人のエンジニアが増えたかのような感覚になりました。
CopilotやCursor、Clineが使用するエンジニアの「スケールアップ」であると言われるのに対し、Devinは「スケールアウト」型のAIエージェントとして、開発チームの仲間を増やすような役割を担うことが特徴的です。(ツール費用ではなくもはや人件費なのでは?と思ってしまいます)
これらのツールを適切に使い分けることで、生産性の向上が期待できると考えています。
精度面では、短期的な差はあれど、技術の進化が速いため今後は他のツールと抜きつ抜かれつの状態が続くと思っています。ツールの良し悪しを判断する際には、精度よりも「どのように活用するか」などのUXがより重要になると考えられます。
また、Devinを効果的に活用するには、タスクの依頼方法にコツが必要です。
ジュニアエンジニアに指示を出すような感覚が求められるため、現時点では、向き・不向きのあるタスクが存在し、コストパフォーマンスを考慮しながらの運用が不可欠です。
ちなみに、今回の記事のドラフトはDevinに作成してもらいました。コミュニケーションしているslackスレッドのURLを情報として与えたらササっと仕上げてくれたのですが、AIっぽい文章だったのと、コミュニケーションのオーバーヘッドが大きかったので、途中からはChatGPTで結構手を入れています。
そのためにも、Devinへのタスク依頼がブラックボックス化しないよう、依頼を行うチャンネルを限定して、特定のチャンネルでのみDevinを呼び出し、進捗をオープンにして、管理とナレッジ共有がしやすい運用が良いと考えています。
DevinのACUsは必要なときに必要なだけ活用できるのでスモールスタートできるのも魅力的なので、使いながら良い運用を見つけていきたいですね。
AIエージェントとの共存は、今後の開発組織にとって避けて通れないテーマになっていくはずです。
Devinの機能でもKnowlageなどは十分に活用できてないので今後さらに使い込んでいこうと思っています。
Devinを活用することで得られる生産性の向上を最大化するためにも、単なるツールとして扱うのではなく、組織全体でその活用方法を学習し、最適な使い方を模索しながら運用を進めていきたいと思います!

株式会社カンリーは「店舗経営を支える、世界的なインフラを創る」をミッションに、店舗アカウントの一括管理・分析SaaS「カンリー店舗集客」の開発・提供、他複数のサービスを提供しております。 技術系以外のnoteはこちらから note.com/canly
Discussion