こんにちは!
株式会社カンリーでSREをやっている本間です。ほんまですよ!
AIが盛り上がっている昨今、AIを使ったコーディングも助かっていますが、AIでプロダクト運用をもっと楽にしたい!AIOpsしたい!!という想いが強くあります。ということで今回は、現在AWSでプレビュー中の「Amazon Q Developer の運用調査機能」を使ってみることにしました。
(4月に東京リージョンでも利用可能になりました🎉)
試すのにちょうどいい障害が起きれば良いのですが(良くはない)、それは難しいので意図的に障害を引き起こして、Amazon Q Developerがどのような結論を出すのか見てみたいと思います。
今回意図的に起こす障害シナリオは以下の3つです。
- ECSのCPU高負荷
- アプリケーションのエラーログ
- ECS -> S3への権限不足
これらの障害を運用調査していきます!
とその前に、機能の有効化方法について解説しておきます。
Amazon Q Developer の運用調査機能の有効化方法
Cloud Watchのサービスページに移動し、[このアカウント用に設定]ボタンをクリックします

調査グループの作成で、保持期間に任意の値を設定します。私はデフォルトの90日としました。
現在この機能はプレビュー中のためコストはかかりませんが、日数によってコストが変わることもありえそうですね。

Amazon Q Developerの許可で[デフォルトの調査権限で新しいロールを自動作成]を選択。
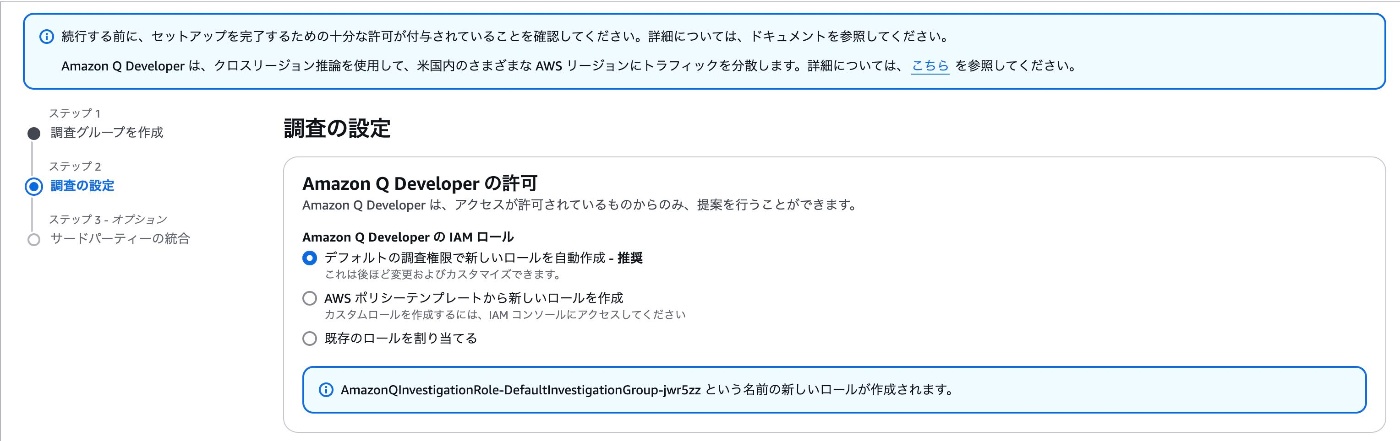
ちなみに作成された権限を見ると、「AIOpsAssistantPolicy」というマネージドポリシーがアタッチされていました!
その他オプション設定はデフォルトにしています。
サードパーティの統合は今回設定しませんでした。設定するとチャットツールに、調査に関する通知を送信できるようです。実際に障害が起こった際は調査結果がいち早く欲しいと思うので、設定するのもありですね。
以上で設定は完了です!
運用調査の検証
前提
まず今回使う検証環境は、ALB + ECS Fargate + S3というシンプルな構成になっています。
本筋とは関係ありませんが、アプリケーションはPythonの軽量WebフレームワークであるFlask(フラスク)を使って構築しています。
また、「調査を強化するためのベストプラクティス」ページが公開されていますが、今回の検証環境では、CloudWatch エージェント・CloudTrailのみ使用しています。
1. ECSのCPU高負荷
まずはECSに負荷をかけて、どのような調査結果を返すか試してみようと思います。
調査の開始は「ログのインサイト」「メトリクス」「アラーム」のいずれかから作成できます。
ECSにはCPUアラートを設定しているので、今回は「アラーム」から設定したいと思います。
該当のアラームを開き、上部の[調査]ボタンから、[新しい調査を開始]をクリックします。

補足:今回は手動作成していますが、CloudWatchアラーム作成画面で調査アクションを設定しておけば、アラート時に自動で調査が作成されるようです。
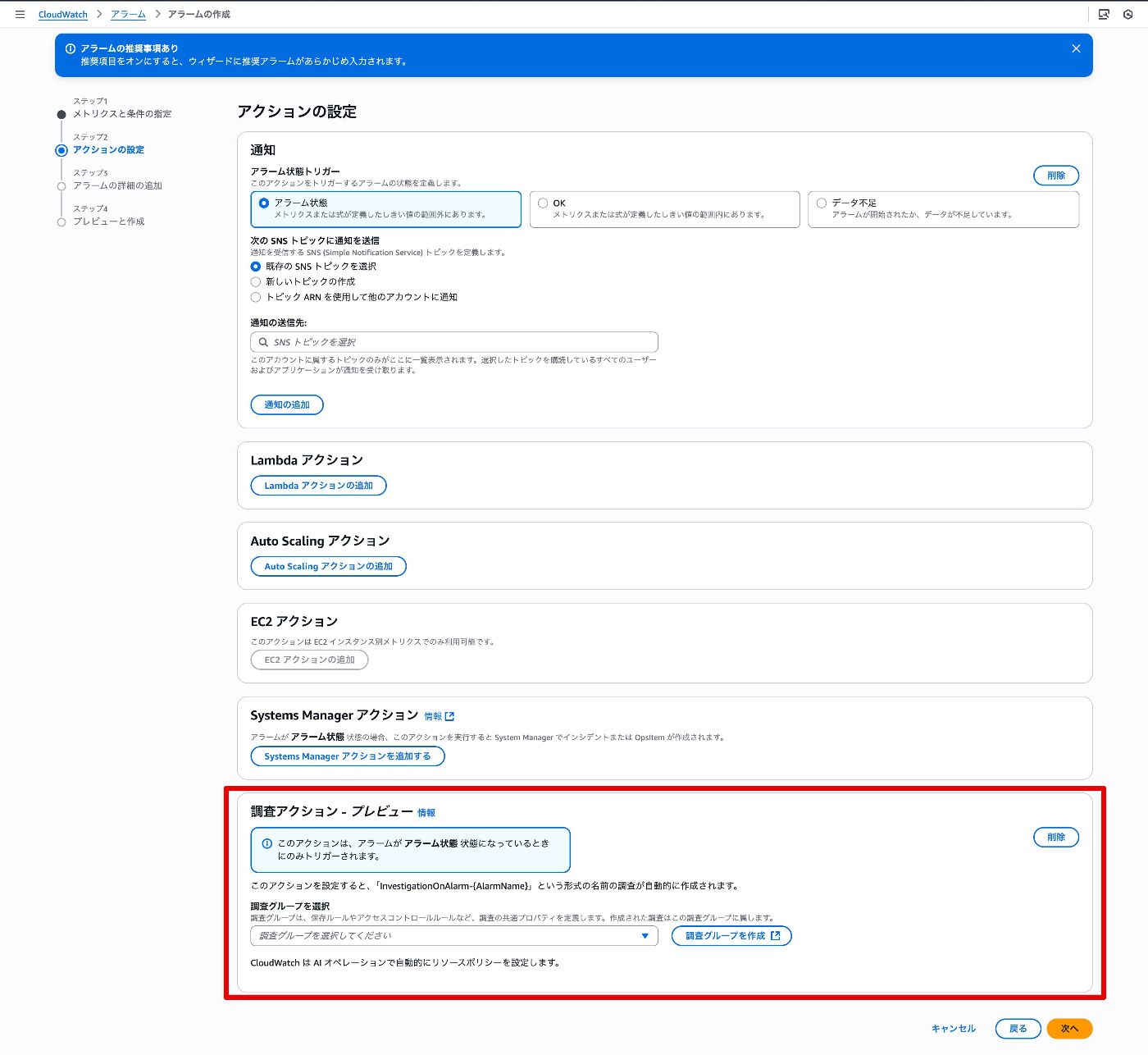
[新しい調査を開始]をクリックします。調査タイトルに日本語を入れると特殊文字は入れられませんと怒られるので(5/28現在)、英語で入力します。

調査を開始すると、観察結果が次々追加されていきます。Amazon Qがどのような手順で調査をしたかの履歴も見ることができます。

観察結果には、CPU高騰のメトリクスと、直近のECS変更イベントを表示してくれています。

関連するメトリクスとして、ALBのTargetResponseTimeも上昇している観察結果も追加されました。

最後に今回の事象の仮説が追加されました。

日本語翻訳:
根本原因は、ECSサービス「development-web-test」におけるCPU使用率の短時間かつ大幅な急上昇であり、「development-web-test-cpu-high」アラームがトリガーされました。この結果、アラームは2025年5月27日8時18分43.348秒にALARM状態に移行しましたが、すぐに解消し、2025年5月27日8時19分43.348秒にOK状態に戻りました。このインシデント発生の直前、8時15分にCPU使用率とロードバランサのTargetResponseTimeの両方が低下しており、アクティビティが減少した後、急激な増加が生じたと考えられます。正確なトリガーは不明ですが、ワークロードの急激な増加や最近のデプロイメントアクティビティに関連している可能性があります。アラーム状態が約1分と短かったことから、これはサービスの構成やキャパシティに関する永続的な問題ではなく、一時的な問題であった可能性が高いと考えられます。
ということで、永続的な問題ではなさそうという回答を得られました!
障害発生時にシステム構成を知らない場合でも、紐づいているロードバランサーのメトリクス情報もサジェストしてくれるのは嬉しいですね!
2. アプリケーションのエラーログ
続いて、アプリケーションで意図的に例外を発生させてエラーログをCloudWatchに出し、ログのインサイトからどのような調査結果を返すか試してみようと思います。ちなみにログは「意図的に発生させたエラーです」というメッセージで出すように実装しています。

ログはCloudWatch Logs Insights画面から調査を作成することができます。CloudWatch Logs Insights クエリ言語 (Logs Insights QL)で調査したい対象を絞って[実行]、その下に[調査]ボタンがあるのでこれをクリック、[新しい調査を開始]をクリックします。

後の流れはアラームのときと一緒で、調査に名前をつけて調査開始します。
観察結果は、ログインサイトのクエリ結果を元にしたと思われる、以下の内容で追加されました。
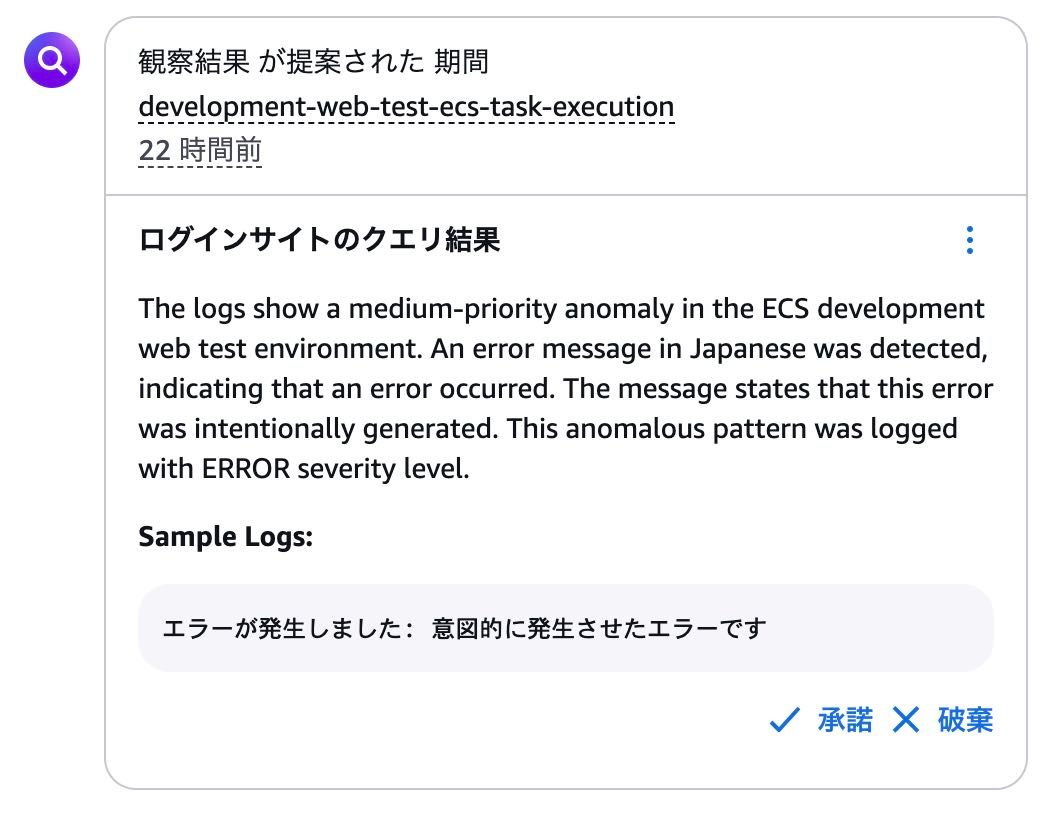
日本語翻訳:
ログには、ECS development web test環境で中優先度の異常が発生していることが示されています。日本語のエラーメッセージが検出され、エラーが発生したことが示されています。メッセージには、このエラーが意図的に生成されたことが示されています。この異常なパターンは、重大度レベルERRORでログに記録されました。
CPU高負荷の調査でも観察結果として出ていた、直近のECS変更イベントとCPU使用率も表示されました。直接関係なくても、時間軸が近いイベントも出してくれるのはありがたいですね。

最後に今回の事象の仮説が追加されました。
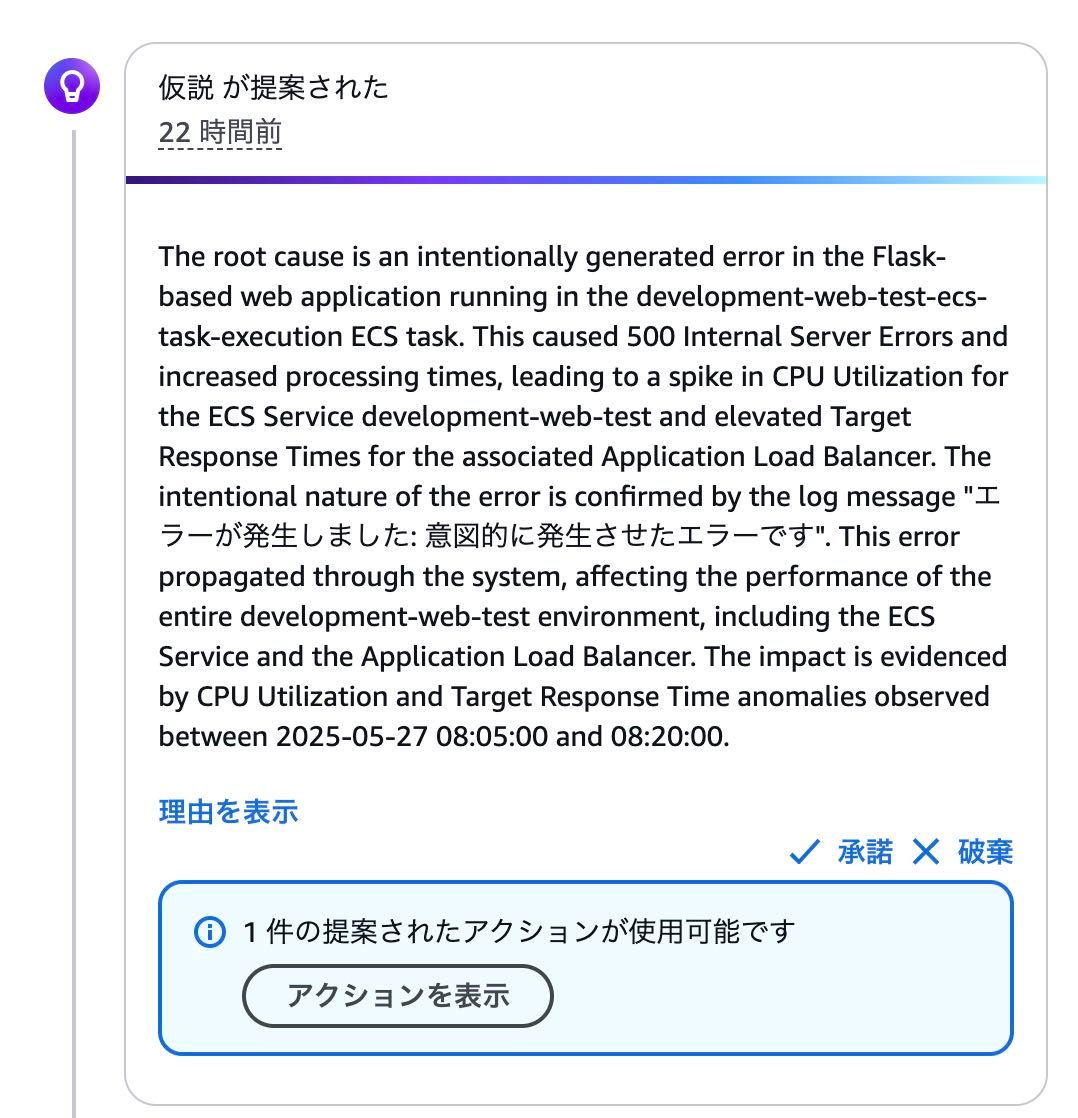
日本語翻訳:
根本原因は、development-web-test-ecs-task-execution ECS タスクで実行されている Flask ベースの Web アプリケーションで意図的に生成されたエラーです。これにより、500 の内部サーバー エラーが発生し、処理時間が増加し、ECS サービスの開発、ウェブ、テストの CPU 使用率が急増し、関連する Application Load Balancer のターゲット応答時間の上昇につながりました。エラーの意図的な性質は、ログ メッセージ「エラーが発生しました: 意図的に発生させたエラーです」によって確認されます。このエラーはシステム全体に伝播し、ECS サービスや Application Load Balancer を含む開発、Web、テスト環境全体のパフォーマンスに影響を与えました。この影響は、2025-05-27 08:05:00 から 08:20:00 の間に観察された CPU 使用率とターゲット応答時間の異常によって証明されています。
ECSに負荷をかけたシナリオと、今回のエラーログのシナリオは15分程度時間を空けてから実施したのですが、Amazon Q 的には2つのイベントを関連付けてしまったようです。障害調査において事象の切り分けは大切だと思っていて、それ次第で対策が変わったり、調査にかける時間ややり方も変わってきます。この結果だけを見ると、与えられた情報から結論急いじゃった感じがあるなぁという印象です。
…しかし!エラーログ以外にも正常なログはたくさんある中で、しっかり問題のログは抽出できているので、かなり良いところまで来ていると感じます。
また、自身で任意のコメントを入れる機能もあるので、起こっていることをこちらからも共有することで、より精度の高い提案がもらえるのかなと思います。
コメントはこちらから追加することができます

3. ECS -> S3への権限不足
続いて、AWSの設定ミスを再現し、どのような調査結果を返すか試してみようと思います。こちらもログのインサイトからどのような調査結果を返すか試してみます。list-objects-v2を実行し、返って来たエラーをそのままログに流しています。

これはエラーメッセージで原因まで出ているので、すぐに特定できる予感がします。
観察結果は、ログインサイトのクエリ結果を元に以下の内容が追加されました。

日本語翻訳:
ログには、development-web-test 環境の Amazon ECS サービスログにおいて、中程度の優先度で異常なパターンが検出されていることが示されています。この異常は、S3 バケットに対して ListObjectsV2 オペレーションを呼び出そうとした際に発生する AccessDenied エラーに関連しています。具体的には、ECS タスクに割り当てられたロールに、S3 バケット「development-web-test」に対して s3:ListBucket アクションを実行する権限がありません。このエラーは、必要なアクションを許可するアイデンティティベースのポリシーが存在しないために発生します。
もうこの時点でわかってますね。
最後に今回の事象の仮説が追加されました。

日本語翻訳:
根本的な原因は、ECSタスクロール(arn:aws:sts::xxx:assumed-role/development-web-test-ecs-task)にS3バケット「development-web-test」に対するs3:ListBucket権限が付与されていないというIAM権限の設定ミスです。これにより、development-web-test-ecs-task-executionサービスがS3バケット内のオブジェクトを一覧表示しようとした際にAccessDeniedエラーが発生しました。他のアプリケーションエンドポイントは正常に動作していることから、この問題はS3オペレーションに限定されています。このエラーは、ECS サービスログに「ユーザー: arn:aws:sts::xxx:assumed-role/development-web-test-ecs-task/807dc206d0a84a17ac395f899ffdcd08 は、リソース「arn:aws:s3:::development-web-test」に対して s3:ListBucket を実行する権限がありません」というメッセージとともに表示されます。この権限の問題により、アプリケーションは S3 バケットと正常にやり取りできなくなり、バケットの内容の一覧表示に依存する機能に影響する可能性があります。
初回の観察結果からもう原因はわかっていそうでしたが、以下の部分の補足が入ったことで説得力が増した気がします!
「他のアプリケーションエンドポイントは正常に動作していることから、この問題はS3オペレーションに限定されています。」
ログに手がかりを残すのは、人間であってもAIでも大切ですね。
まとめ
3つのシナリオを試した限り、仮説の精度よりも、起こっている事象をサマってくれる点で優秀な印象を受けました。Amazon Q Developerが収集した情報を取り出し、他サービスの情報等と組み合わせて、総合的に何かしら別なAIモデルで最終的な仮説を出してもらう使い方がいいかもしれません。
しかし、障害調査は現場で何度も経験しないと身につき辛いスキルなので、こういったAIによる支援で調査のハードルが下げられるのはとても良いことだと感じます!
今回の検証した機能以外でもまだまだ気になるものがあるので引き続き検証していき、AIによるプロダクト運用で少しでも楽ができないか探っていこうと思います。

株式会社カンリーは「店舗経営を支える、世界的なインフラを創る」をミッションに、店舗アカウントの一括管理・分析SaaS「カンリー店舗集客」の開発・提供、他複数のサービスを提供しております。 技術系以外のnoteはこちらから note.com/canly
Discussion