こんにちは!
株式会社カンリーのプラットフォーム部でSREをしている吉村です。
今回は、Datadog x GitHub x Devinでエラーの自動化に取り組んだ話について紹介します。
👀 エラーログ当番の工数を減らすために
システムが成長してくると、人間の目やSlack通知だけでは拾いきれないエラーが増えていきます。
とくに「軽微だけど継続的に発生している」「特定条件下でしか発生しない」、そんなエラーが気付かぬうちにUXを損なったり、バグの温床になっていることもあります。
カンリーでも、Datadog自体は導入済みだったものの、Error Trackingの設定が不十分で、対応すべきエラーが自動的に可視化されていないケースがありました。
その結果、対応が後手に回ってしまうことも多く、エラーログの確認やタスク化を当番制で行っていましたが、工数的な負担も大きい状況でした。
このような背景から 「Datadogで検知した未対応エラーを自動でGitHub Issue化し、Devinをアサインして解決させる」 仕組みを整備することにしました。
本記事では、Datadogのエラー検知から、GitHub Issueの自動起票、Devinによる初動対応までの一連のフローを紹介していきます。
🚨 解決したかった問題
- DatadogのError Tracking設定が不十分で、エラーがタスクとして適切に起票・可視化されていなかった
- 対応を当番制で行っていたが、確認・タスク化の負担が大きく、初動が遅れることがあった
🛠️ 利用したツールと構成要素
この自動化フローを実現するために、以下のツールやサービスを利用しました!
| 役割 | 使用したツール | 用途 |
|---|---|---|
| モニタリング | Datadog | エラー検知(Error Tracking)とWorkflowのトリガー |
| ワークフローエンジン | Datadog Workflows | エラー発生時の処理自動化(GitHub Issue作成・API連携) |
| ソースコード管理/Issue管理 | GitHub | Issue管理(開発タスクの起票・追跡) |
| AIエージェント | Devin | Issueを元にした自動調査・修正提案・PR作成 |
これらを連携させることで、エラー検知から対応までの一連の流れを人手を介さずに自動で進める仕組みを構築しています。
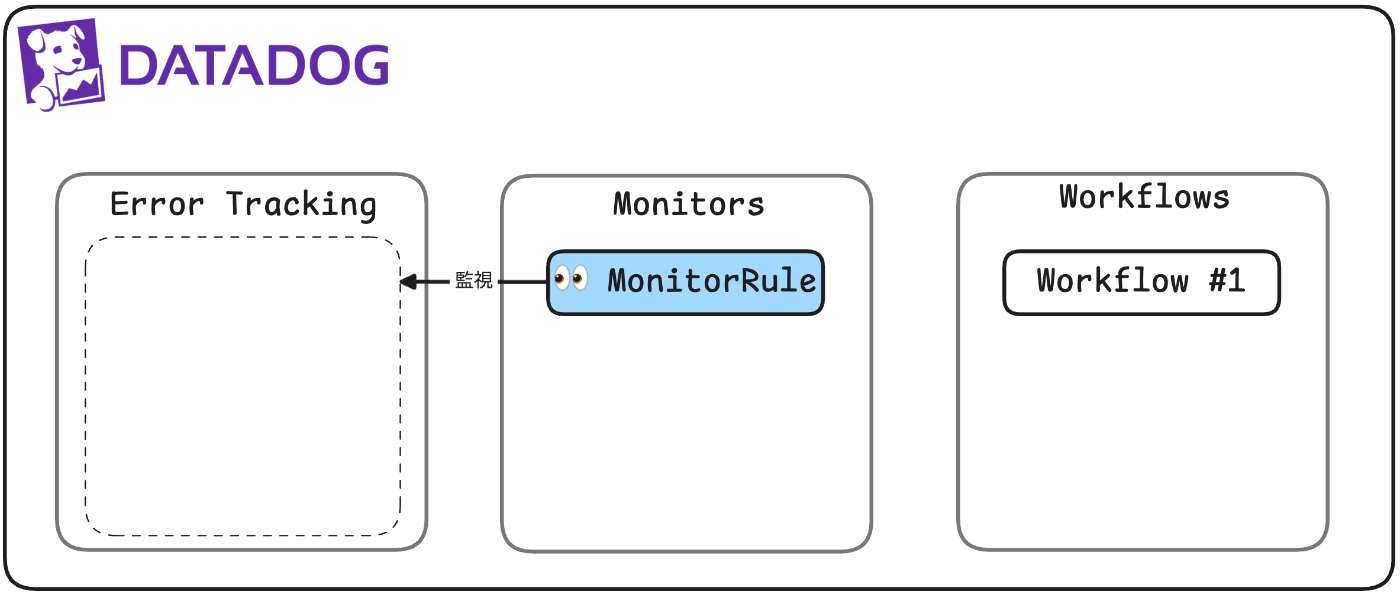
📝 モニターの構成と設計方針
Datadog上に、canly-product-1 の各環境(development / staging / production)を対象としたError Trackingモニターを構築しました。ポイントは以下の通りです:
- モニタータイプ:
error-tracking alert - 対象サービス:
canly-product-1の全環境 - 条件:issue.id ごとにグルーピングし、新規エラー発生時のみ検知(
.new().by("issue.id")) - 集計期間:直近1日(
last("1d") > 0)
この構成により、「過去に一度出た既知のエラー」は無視し、「これまで検知されていなかった新規のエラー」のみを検出できます。
また、エラーの粒度や通知ノイズを抑える工夫も組み込んでいます。
たとえば、issue.id単位でグルーピングすることで、同じ内容のエラーで複数アラートが飛ばないようにしており、必要以上にIssueが乱立しない設計です。
このモニターでアラートが検知されると、Datadog Workflowが即座に起動します。Slackなどの通知は挟まず、createIssue ステップでGitHubにIssueを自動起票し、続けてDevinへの依頼が行われる形になっています。
また、通知メッセージには、エラーの種類、メッセージ、発生ファイル、StackTraceなどの情報を含めており、Issue起票後の初動対応がしやすいようテンプレートを整備しています。
↓↓↓↓
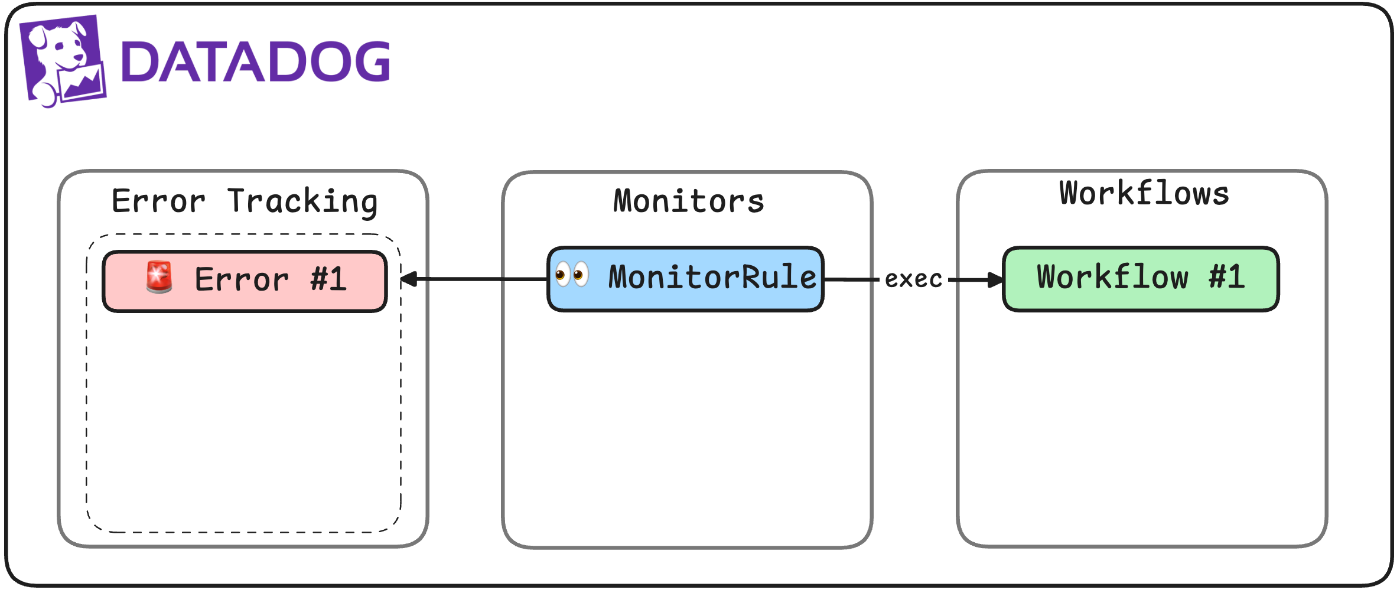
🔄 Datadog Workflowの流れと構成
このセクションでは、Datadog WorkflowによってどのようにGitHubとDevinを連携し、エラー対応が自動で進むのかを、下記のWorkflow図を用いて説明します。

ステップ①:GitHub Issueの自動起票
最初のステップでは、あらかじめ設定しておいたモニターがトリガーされることで com.datadoghq.github.createIssue アクションが実行され、次のようなIssueが作成されます。
お見せすることはできないですが、Issueの中に Stack Traceや ErrorMessageが含まれており、これら付加情報によってDevinが調査・対応を開始しやすい状態が整います。
ステップ②:Devin への対応依頼
次に com.datadoghq.http.request ステップが実行され、Devin API にリクエストを送ります。
{
"prompt": "下記のIssueについて対応してください\n{{ Steps.Create_issue.url }}"
}
ステップ③: Devinによる対応開始
Devinは該当Issueを元に調査・分析を開始し、必要に応じて修正案やPRを提案してくれます。

ここでも中身をお見せすることができませんが、変更内容や技術的な修正内容、テストの結果などを記載してくれています。
⚡️ 注意点・補足事項
この仕組みを構築・運用していく中で、いくつか注意すべき点があります。
1. 認証情報の管理(APIキーなど)
Datadog Workflowで外部サービス(GitHubやDevin API)と連携する際、APIキーやアクセストークンなどの認証情報が必要になります。これらは DatadogのConnection機能 を利用して管理することにしました。
Connectionとして一度登録しておくことで、Workflow内のアクションからは直接キーを記述せずに参照することができ、セキュリティと再利用性を両立できます。
2. モニター条件・通知テンプレートの設計
※先述の「モニターの構成と設計方針」で触れた内容と重複しますが、改めて補足します。
自動化によりIssueが大量に立つ可能性もあるため、モニターの条件設定やラベル付けには特に注意が必要です。重要度やエラー種別によってフィルタリング・分類をする工夫も今後必要になってくるかもしれません。
📖 実際に使用してみて
まだ運用を開始してから日が浅いため、大きな定量的効果が出ているとは言えませんが、少しずつ次のような手応えを感じ始めています。
- 自動でIssueが立つことで、チーム内での対応漏れが発生しにくくなった
- Devinによって初動の調査が進むため、着手までのスピードが格段に上がった
エラーログを見ていなかったわけではありませんが、当番制の運用はどうしても負担が大きく、確認や対応が後回しになってしまうことも多くありました。
しかし今では、確認する頃にはIssueが立ち、DevinがPRの準備まで進めてくれている、そんな状況が少しずつ当たり前になりつつあります。
✊ 今後やりたいこと
- Issueの優先度分類や通知フローの最適化
- Devinによる再発防止提案やログ調査の自動化
- 他プロダクトやサービスへの横展開
🙏 おわりに
Datadog → GitHub → Devin という流れをつなげることで、これまで拾いきれなかったエラーにも即時対応できる体制ができました。
以前はメンバーがDatadogを見て手動で拾いにいく必要があったエラーも、今では確認する時点ですでにタスク化され、Devinが調査を始めている。そんな状態が当たり前になりつつあります!
今後さらに改善を重ね、開発サイドの運用の一助になるような仕組みに作っていければと考えています!!

株式会社カンリーは「店舗経営を支える、世界的なインフラを創る」をミッションに、店舗アカウントの一括管理・分析SaaS「カンリー店舗集客」の開発・提供、他複数のサービスを提供しております。 技術系以外のnoteはこちらから note.com/canly
Discussion