初めまして!
株式会社カナリーでソフトウェアエンジニアをしている Pana です。弊社ではお部屋探しアプリのカナリーを運営しており、自分はバックエンド領域をメインで担当しています!!
カナリーに入社して3か月が経ったのですが、入社した当初はslackに飛んでくるアラートが「オオカミ少年状態」でした😢
アラートの「オオカミ少年状態」...
お部屋探しアプリのカナリーでは、10以上のサービス、常時100個近くのPodが動いているマイクロサービスで構成されています。ログベースでアラートを設定していましたが、そのような状態で
- 重要なログ (アラート) とそうでないログ (アラート) の判断がつかない
- どのエラーログがどれくらいの頻度で発生しているのか分かない。なので、エラーの修正の優先順位をつけづらい
- ログを見てもどういうリクエスト/サービスで発生したエラーなのか分かりづらい
という問題を抱えていました。さらに
4. 急激なリクエスト増加やレイテンシー増加に対するモニタリングが欠けている
5. アラートに対応できる人が社歴の長いメンバーのみに限られている
という課題も抱えていました。
なので、アラートが飛んできてもよく分からないという理由で放置されていたり、そもそもシステムの「異常」を検知できるようなメトリクスが十分に取れていない、というような状態でした!😵
何をしたか?
そこで11月頭から、自分ともう一人のエンジニアでオブザーバビリティを向上させるプロジェクトがスタートしました 🏃
プロジェクトでは、Datadog移行、トレース導入、トレースとログの紐付け、ダッシュボード整備、アラートチャネル整理などさまざまなことを行いました。その中で自分は
- DatadogのError Trackingの導入
- OpenCensus → OpenTelemetryへの移行
- Runbookの整備
の3つを担当しました!具体的に何をしたか1つ1つ解説したいと思います!!
DatadogのError Trackingの導入
まずはDatadogの Error Tracking を導入しました。この機能はめちゃくちゃ素晴らしいです 👏👏👏
Error Trackingを導入することで、以下のことが実現可能になります!
1. 類似のエラーを自動的にグルーピングする
2. 喫緊の問題に関するアラートを設定できる
実際に導入した後、Error Trackingの画面は以下のように表示されます。
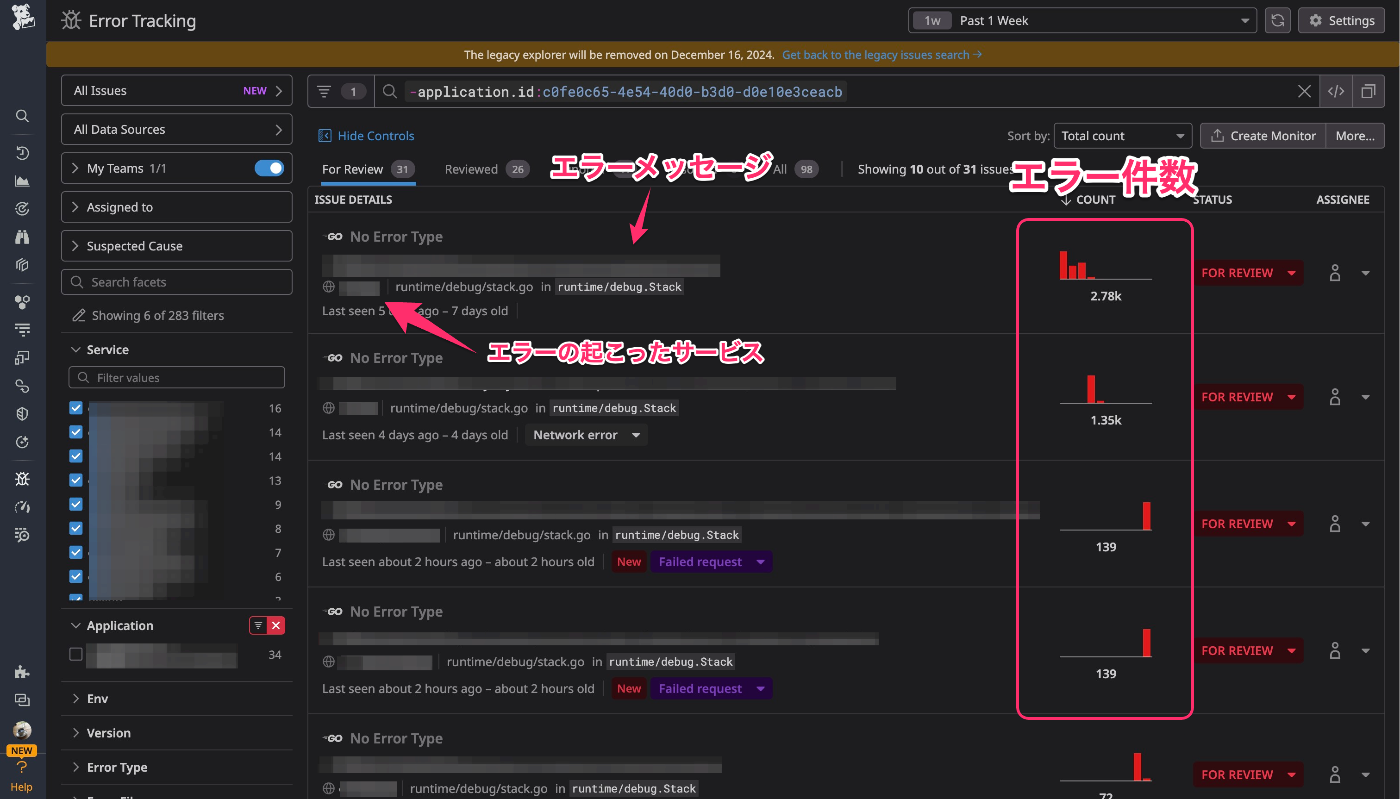
どんなエラーがどれくらいの頻度で起こっているか、をかなり把握しやすくなったと思います 🎉
Error Tracking上で表示されるグルーピングされたエラーは「Issue」と呼ばれます。
Issueには「FOR REVIEW」「REVIEWED」「IGNORED」「RESOLVED」の4つの状態があります。
まだ運用としてきちんとルール化はできていないのですが、それぞれのIssueを状態ごとに管理していくということが可能になります!
たとえば、修正が必要なIssueを「REVIEWED」にしておいて、修正が完了したら「RESOLVED」にする、などです。「RESOLVED」にした後、同じエラーが発生した場合、「FOR REVIEW」の状態として再び表示されるようになっています。

一度「RESOLVED」にしたエラーが再度発生した場合にはRegressionというアイコンが付く
視覚的にも分かりやすい表示になっており、個人的にも「便利だな〜」と思うポイントの1つになります!Issueの状態に関するより詳細な情報は、Issue States in Error Tracking を参考にしてもらえればと思います!
モニターについても軽く触れたいと思います 🔎
Error Trackingを元にしたモニターは、以下の2つのタイプで設定できます。弊社では両方のタイプのモニターを設定しています。
-
New Issues: 新しく発生したIssueについてのアラートを設定できる -
High Impact Issues: 一定時間の間に、ある閾値を超えて発生するIssueについてのアラートを設定できる

自分の経験上、バグが原因のエラーについては、とくにそのバグをリリースした直後に起こりがちなイメージがあります。ログベースでアラートを設定することで気づくことはできます。しかし、日々大量のアラートが飛んでくるslackのチャンネルであれば、リリースがあってアラートが流れてきていたとしても気づかない人/気にしない人が一定数いるのではないでしょうか?
Error Trackingの場合、ある閾値を超えたときのみにアラートを発火させることが可能になっています。つまり、そもそもアラートの数や頻度を減らせるということです。上記のような、アラートの「オオカミ少年状態」も回避できるので、個人的にはとてもありがたいと思いました 👏
ログの修正
Error Trackingを導入するため、ログの構造を修正する必要がありました。
具体的には以下の3つを対応する必要があります。より詳細な導入方法に関しては、Track Backend Error Logs を参考にしてください!
-
error.kindかerror.stackをログのフィールドに含める- ただし
error.stackを使用する場合、正しいスタックトレースになっている必要がある
- ただし
-
Serviceの属性を設定する -
ERROR,CRITICAL,ALERT,EMERGENCYのログレベルを使用する
2はすでに対応済みだったので、1と3を修正しました!
「error.kind か error.stack をログのフィールドに含める」修正
結論: error.stack を使用することにしました
理由としては、
- ログにスタックトレースを含めるような実装がすでにされていた
-
error.kindの場合、どのようなときにどのkindを使うのか、kindはどのような粒度で定義するのか、を整備する必要がある - エラーの発生箇所特定にはスタックトレースが便利
ということが挙げられます!
実際に修正してみると、以下のような表示になります(モザイクばかりで分かりづらいかもですが)

スタックトレースがフレームごとに(視覚的に)分かれて表示される
クラウドサービスが提供するロギングサービスの表示よりも、かなりみやすくなっていると思います!
「ERROR, CRITICAL, ALERT, EMERGENCY のログレベルを使用する」修正
結論: ERROR のみを使用し、エンジニアの対応が必須なエラーは別途フィールドを追加することにしました
弊社では、ロギングライブラリに zap を使用しています。当初では以下のような実装ができれば良いと考えていました。
💡 エンジニアの対応が必須なエラーはCRITICAL や ALERT など ERROR より上のログレベルとして設定する
しかし、zapには以下のような課題点があります。
-
ERRORより上のログレベルが、パニックを起こしたり、プロセスを終了させる挙動になっている - カスタムなログレベルを定義できない
対応必須なエラーが起こるときに、パニックになったり、プロセスが終了してしまうのは意図する挙動ではありません。また、パニックを起こしたり、プロセスが終了しないようなカスタムな(ユーザー定義の)ログレベルも設定できません。
社内で議論した結果、
💡 基本的にエラーはすべて ERROR のログレベルを使用する。エンジニアの対応が必須なエラーは "need_action": true" のフィールドを追加する
という方針にしました。上記のフィールドベースで、対応が必須かどうかのアラートを分けています。
Error Tracking導入&ログ整備で解決したこと
さて、ここまでで冒頭の課題がいくつ解消したのかまとめてみます!
-
ログベースでアラート設定しているものの、重要でないログ (アラート) とそうでないログ (アラート) の判断がつかない
→ 特別なフィールドを用意し、そのフィールドベースでアラートを設定することで解決 ✅ -
どのエラーログがどれくらいの頻度で起こっているのか分からず、修正の優先順位がつけづらい
→ Error Tracking導入で解決 ✅ -
ログを見てもどういうリクエスト/サービスで発生したエラーなのか分かりづらい
→ ログにスタックトレースを含めることで解決 ✅ - 急激なリクエスト増加やレイテンシー増加に対するモニタリングが欠けている
- アラートに対応できる人が社歴の長いメンバーのみに限られている
後半は4,5の課題に対してアクションを起こした話をします!
OpenCensus → OpenTelemetryへの移行
課題をもう少し整理してみる
弊社では、メトリクスの収集は OpenCensus を使用していました。しかし、以下のような課題点が存在しました。
- OpenCensusのGoによる計装 opencensus-go は、2024/12時点ですでにアーカイブされている
- レイテンシーやリクエスト数の詳細な統計情報(e.g. p99やp95)をDatadog上で取得できない

OpenCensusで収集しているレイテンシーのメトリクス。Metric TypeがNot assignedになっている。p99などの統計情報が欲しい場合は、HistogramのMetric Typeである必要がある
上記の課題から OpenCensus → OpenTelemetryへの移行 を行いました!
以下の2つのメトリクスを取得するように実装しました。また、API/サービス/ステータスコードごとに統計情報が取れるようにしました
- レイテンシー
- リクエスト数
実装(計装)
弊社では、Datadog Agent を用いてログやメトリクスの収集していました。したがって、以下のように実装(計装)を進めました。
- Datadog Agent側に、OTLP形式のメトリクスを受け取れるエンドポイントを用意する
- サーバー側に、メトリクスを送るエンドポイントを用意する
- メトリクスを収集するように、アプリケーションコードを修正する
インフラ側の修正
1と2に関しては、OTLP Ingestion by the Datadog Agent を参考にしました。
修正コストもそれほど大きくなく、ドキュメント通りに設定すれば問題なくメトリクスが収集できました 👏(個人的には、ドキュメントが充実しているのもDatadogの素晴らしい点だと思います!)
アプリケーション側の修正
3のメトリクスの収集については、OpenTelemetryの GoのInstrumentation のドキュメントを参考に、以下のような流れで計装を行いました!
- Exporterを初期化する
- メトリクスはgPRCで送るように、otlpmetricgrpc を使用しました
- MeterProviderを初期化する
- メトリックのInstrumentを生成する
Exporterを初期化する際のコードの一例です。deltaSelector は、Aggregation Temporalityに関する実装になっています(後述)。
func newExporter(ctx context.Context) (sdkMetric.Exporter, error) {
return otlpmetricgrpc.New(ctx,
otlpmetricgrpc.WithEndpointURL(
os.Getenv("OTEL_EXPORTER_OTLP_ENDPOINT"),
),
otlpmetricgrpc.WithTemporalitySelector(deltaSelector),
)
}
OTLP形式で送られるメトリックの Aggregation Temporality に注意が必要です。Aggregation Temporalityには「delta」と「cumulative」の2種類が存在します。
metric.InstrumentKindCounter や metric.InstrumentKindHistogram のInstrumentを使用する場合、「delta」を使用するとDatadogと相性が良いそうです。 詳細は Producing Delta Temporality Metrics with OpenTelemetry を参考にしてください。
MeterProviderを初期化する実装は、以下のようになっています。
var meter metric.Meter
func InitMeter(ctx context.Context) error {
// Exporterを初期化
exporter, err := newExporter(ctx)
if err != nil {
return fmt.Errorf("failed to init metric exporter: %w", err)
}
// MeterProviderを初期化
meterProvider := sdkMetric.NewMeterProvider(
sdkMetric.WithReader(
sdkMetric.NewPeriodicReader(
exporter, sdkMetric.WithInterval(1*time.Minute),
),
),
)
otel.SetMeterProvider(meterProvider)
meter = otel.Meter("github.com/XXX/YYY/ZZZ")
return nil
}
MeterProviderの初期化について、とくに特筆すべき点はないです!
meter はInstrument生成ごとに引数で渡すのが煩雑だと思い、グローバルな変数として定義しています。
const (
// Unitは https://unitsofmeasure.org/ucum の規則に従っている必要がある
unitMilliseconds = "ms"
unitDimensionless = "1"
)
var (
metricHTTPLatencyDistribution metric.Int64Histogram
metricHTTPRequestCount metric.Int64Counter
)
// InitMeterの中で呼ぶ
func newHTTPLatencyDistributionInstrument() (metric.Int64Histogram, error) {
return meter.Int64Histogram(
"http.server.request.duration",
metric.WithUnit(unitMilliseconds),
metric.WithExplicitBucketBoundaries(
0, 5, 10, 20, 40, 80, 160, 250, 500, 750,
1000, 1250, 1500, 1750, 2000, 2250, 2500, 2750,
3000, 3250, 3500, 3750, 4000, 4250, 4500, 4750,
5000, 10000, 20000,
),
metric.WithDescription("The distribution of http API latencies"),
)
}
func MeasureHTTPLatencyDistribution(ctx context.Context, ms int64, attrs ...attribute.KeyValue) {
metricHTTPLatencyDistribution.Record(ctx, ms, metric.WithAttributes(attrs...))
}
// InitMeterの中で呼ぶ
func newHTTPRequestCountInstrument() (metric.Int64Counter, error) {
return meter.Int64Counter(
"http.server.request.count",
metric.WithUnit(unitDimensionless),
metric.WithDescription("The count of http API"),
)
}
func IncrementHTTPRequestCount(ctx context.Context, attrs ...attribute.KeyValue) {
metricHTTPRequestCount.Add(ctx, 1, metric.WithAttributes(attrs...))
}
メトリクスの計測はミドルウェアで行うようにしたかったので、外部に公開された関数として MeasureHTTPLatencyDistribution と IncrementHTTPRequestCount を実装しています。
HTTPサーバーのSemantic Conventionsは Semantic Conventions for HTTP Metrics に記載されています。本来ならSemantic Conventionに従ったほうが良いのですが、内部で取得するメトリクスなので、そこまでの厳密さは求めずに実装しました。
どんな感じでメトリクスが取れたか
最終的に、サービス、API、ステータスコードごとのレイテンシーやリクエスト数をDatadog上で表示できました 🎉🎉🎉

サービス、API、ステータスコードごとのレイテンシー。縦軸の単位はms
OpenTelemetryでのHistogramのメトリックは、Datadog上ではDistributionとして扱われます。さらにDistributionのパーセンタイルの情報を表示するには、こちらに記載のある操作 を行わなければなりません。(自分はこのことを知らずに実装ミスだと思い、何回もコードを書き直したり読み直したりしました、、、)
OpenCensus → OpenTelemetryへの移行で解決した課題
-
急激なリクエスト増加やレイテンシー増加に対するモニタリングが欠けている
→ レイテンシーのp95やp99をOpenTelemetryで取得し、それらのメトリクスベースのアラートを設定することで解決 ✅ - アラートに対応できる人が社歴の長いメンバーのみに限られている
残された課題は1つになりました!
Runbookの整備
最後にRunbookの整備を進めました 🏃
行動に移す前、 「Runbookを整備することで何を達成したいのか?」 をよく考えました。
個人的には「誰でもアラートに対応できる状態」は達成したいことの1つに過ぎないのでは、と思っています。
それだけでは不十分と感じており 「頻繁に起こるアラートや対応に時間がかかるアラートを定量的に可視化し、システム改善の意思決定の判断材料の1つにする」ということを目指すことにしました!(エラーバジェットやSLI/SLO策定をシステム改善の意思決定として使う、という方法もあると思います)
どうやったか?
やったこととしてはシンプルで、
1. Runbookを作成する
2. アラートにRunbookのリンクを貼る
3. Runbookからすぐ対応ログを残せるようにする
ということを行いました。
作成したRunbookの1つを載せます!

シンプルなRunbookです。ポイントとしては、過去対応事例 の部分に対応したログを残せるようにしているところです! RunbookはNotionで管理しています。ログ用のDBとRunbook用のDBを紐づけることで、Runbookに沿って行われた対応が過去何回あるか、以前の対応はどうやったのか、を把握しやすくしています!
またRunbookには、想定対応時間 を記入する箇所があります。対応した回数と想定対応時間を掛け合わせることで、どの対応に時間が取られているのかを把握しやすくしています!

一番上のアラートは他のアラートに比べて頻繁に発生することが定量的にわかる
みんながログを残してくれれば、システムの改善の意思決定もしやすくなるのかなと思っています!🤔
Runbookの整備で解決した課題
-
アラートに対応できる人が社歴の長いメンバーのみに限られている
→ Runbookを整備し、過去の対応ログと紐づけることで解決 ✅
結果
さて、冒頭でお話ししたすべての課題が解決できました 🎉
解決前と解決後で、アラートの見え方やログの見え方、みんなの反応がどう変化したかを見てみます!
アラートの見え方
| Before | After |
|---|---|
 |
 |
Afterの方が
- 対応が必須かどうかすぐにわかる
- エラーの発生したサービスがわかる(図の
Serviceの部分) - ログやRunbookへのリンクがある
ようになっていると思います。個人的にはアラート対応する敷居がかなり下がっているのではと思います!👏
ログの見え方
続いてログの見え方についてもBefore/Afterを見てみます(以下の画像は同じエラーログを表示しています)。
| Before | After |
|---|---|
 |
 |
Beforeではクラウドのロギングサービスを使っていましたが、Datadogで表示することで
- 視覚的にスタックトレースやエラーメッセージが見やすくなった
- サービスごとにどれくらいのエラーが起こっているか、などの統計処理がしやすくなった
と感じています!
みんなの反応
最後にアラートに対する、エンジニアの反応を見てみたいと思います!
| Before | After |
|---|---|
 |
 |
アラートに対してもとくに何も反応のない状態が多かったですが、Afterでは
- スタンプを押したりして、何かしらの反応がある
- スレッドで、問題ないかどうかのやりとりがある
というように、反応してくれる人が増えたのかなという印象を受けます!
今後の展望
オブザーバビリティ向上のため、カナリーで行ったことを紹介しました!
以前よりアラートやエラーログを見やすくなったのではと思っています!将来的にはSLI/SLOやエラーバジェットの策定等を行って、システム改善のための判断材料を定量的に測定する仕組みを整えていきたいと思っています!
最後に、弊社ではエンジニアを絶賛採用中です!エンジニア向けEntrance Bookには、扱っている技術スタックや開発組織、大事にしている価値観などが記載されています!興味がある方は、ぜひ一読してみてください!
ここまでお読みいただき、ありがとうございました!!!

Discussion