オートマトンは正規表現の夢を見るか(見るし、夢というかそのものですらある)
何についての記事なの?
ある種の正規表現エンジンの実装には、オートマトンと呼ばれる計算(機)モデルが応用されています
この記事は、オートマトンという計算(機)モデルが正規表現とどう関わっているのかを、実際にオートマトンを紙とペンで操作しながら理解しようという目的で書かれています
結果的に正規表現エンジンの実装にはほとんど踏み込めておらず、計算理論の話に終始しています。それでも面白いと思ってくださる方は、ぜひ読み進めていただけると幸いです
面白そうだなと思って頂けていない方も、ぜひ読んでみて下さい。そして計算科学の面白さがなんとなく伝われば嬉しいです
いきさつ
Goの正規表現パッケージregexpのソースコードを見ると、こんなことが書いてあります
// The regexp implementation provided by this package is
// guaranteed to run in time linear in the size of the input.
// (This is a property not guaranteed by most open source
// implementations of regular expressions.) For more information
// about this property, see
//
// https://swtch.com/~rsc/regexp/regexp1.html
//
// or any book about **automata theory**.
どうやら、RE2(Goでも使用されている正規表現エンジン)の時間計算量は入力された文字列のサイズに対して線形である(いわゆる1次のオーダーになっている)ようです
これはすごいことです。正規表現はとても柔軟な表現記法なのに、入力がどれだけ増えようと計算量が1次のオーダーに収まっているというのですから……!
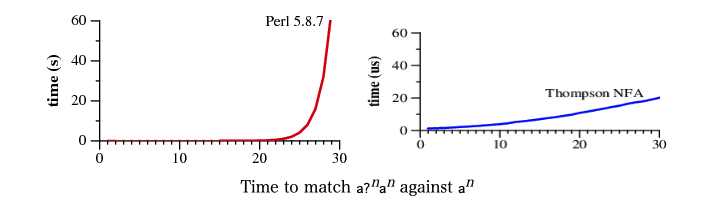
Russ Cox “Regular Expression Matching Can Be Simple And Fast (but is slow in Java, Perl, PHP, Python, Ruby, ...)”より画像を引用
https://swtch.com/~rsc/regexp/regexp1.html
でも今回の記事では時間計算量が線形になる理由は置いておいて(!)、automata theoryというものを深追いすることにします。これは完全に筆者の趣味です
というわけで、実際に手を動かしながらじっくりautomata theoryを見てみましょう。とても不思議な機械じかけの世界への旅行です!
おっと待った、automata?(ダジャレ?)
大まかな定義と例
automataとは、automatonの複数形です。automatonとは自動装置とか人形とかいう意味がありますが、「機械仕掛けで動くもの」というイメージを持っておけば良さそうです。えっ、そんな英語の授業を受けに来たのではないって?それはそうですね……!
さて、コンピューターサイエンスの文脈においてはautomatonはオートマトンと呼ばれ、それは簡単に言えば「一連の入力を受けながら、自らの状態を遷移させる計算機」のことです
例えばパックマンに出てくるおばけを思い出してみましょう
(このパックマンの事例はYash Soni “REAL WORLD APPLICATIONS OF AUTOMATA” https://yashindiasoni.medium.com/real-world-applications-of-automata-88c7ba254e80 を参照しています)

Yash Soni “REAL WORLD APPLICATIONS OF AUTOMATA”より画像を引用
https://yashindiasoni.medium.com/real-world-applications-of-automata-88c7ba254e80
このおばけたちのことを「パックマンの状態やパックマンの認識状態」を入力として、下記のように自らの状態を遷移させる計算機だと捉えることができます
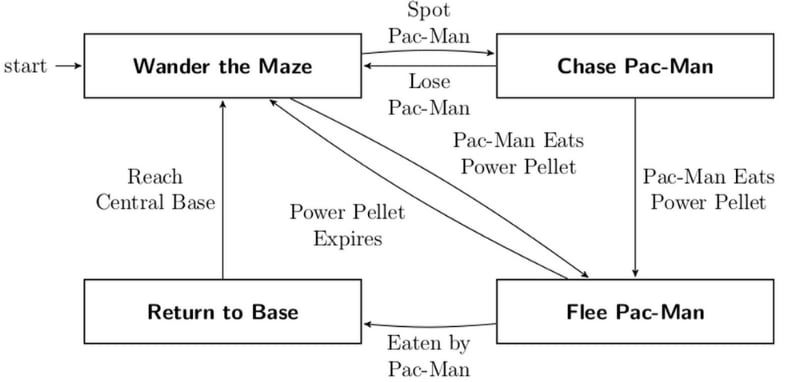
Yash Soni “REAL WORLD APPLICATIONS OF AUTOMATA”より画像を引用
https://yashindiasoni.medium.com/real-world-applications-of-automata-88c7ba254e80
形式言語理論的(けいしきげんごりろんてき)なオートマトン
さて今回は、下記で説明する形式言語理論的なオートマトンを考えます。ここから先、私がオートマトンと言ったらすべてこのようなものだと考えて下さい
しかし「形式言語理論的な」とさらっと書いたはいいものの、そもそも形式言語理論とは何かという話がなされるべきです。形式言語の定義は色々あるようですが、大雑把にいうと「完全に定められた文法(構文規則)に則り記号が配置されることで構成される言語」くらいではないでしょうか。プログラミング言語はまさに形式言語です
形式言語理論で考えられるオートマトンは多くの場合、文字列を入力として、自らの状態を遷移させるものです
例えば{0,1}という2種類の文字からなる文字列を入力として、自身の状態を遷移させるオートマトンを考えてみます。入力によっていったりきたりしたりしなかったりする計算機です
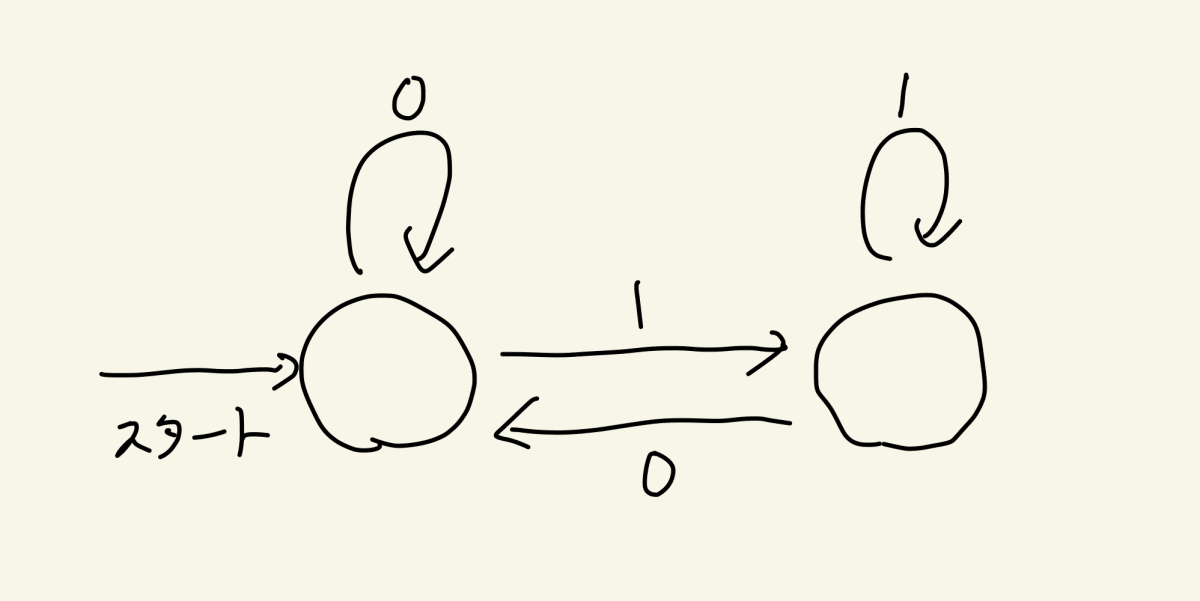
さっそくこのオートマトンに文字列を入力してみましょう!
1を入力するとどうなるでしょうか?スタートして、まずは左の状態にいます。そして1を与えるので、右の状態へ遷移して終わりです
では0は?スタートして、まずは左の状態にいます。そして0を与えるので、くるっと左の状態に留まって終わりです
では01は?下記のようになって右の状態で終わりますね!
- まず左の状態
- 0を読み込んで、左に留まる
- 1を読み込んで、右へ。終わり
さて、これだけでは何にもなりません。ここで下記のように「受理状態」なるものを考えます
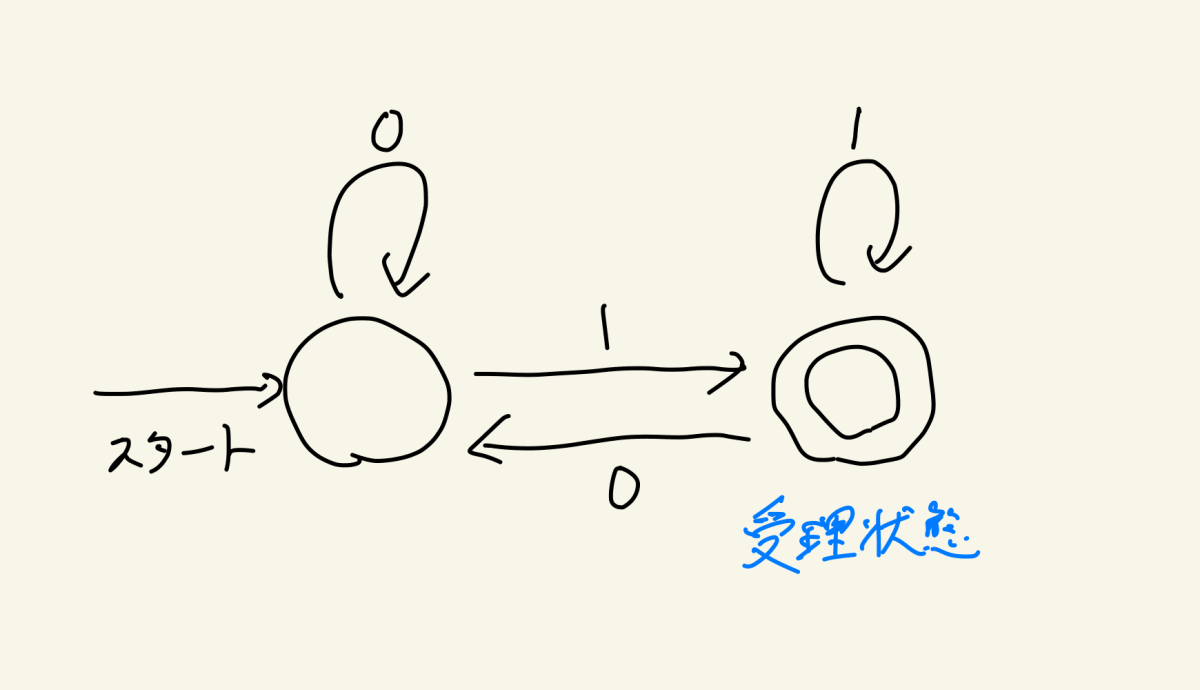
受理状態とは「入力を処理しきった時点でその状態にいるならば、その文字列を『受理』するような状態」です
『受理』とはその計算機が入力を受け取ったということです
ここでは、受け取ったということ単独で意味があるわけではありません。お役所の書類を提出しているわけではないので「受理された!やったー!!おめでとう!!」というわけではないのです
そうではなく、『受理』という結末を考えることで文字列全体を「受理される文字列」と「受理されない(=拒否される)文字列」の2種類に分類できるようになることに意味があります
そして、あるオートマトンが受理する文字列全体はそのオートマトンの「正規言語」と呼ばれます
2種類のオートマトン
ここで2種類のオートマトンに区別をつけておきます
下記2つのオートマトンはともに{0,1}で構成された文字列を入力とするオートマトンです
これらオートマトンの違いは何でしょうか?もちろん正規言語は異なりますが、それだけではなく、より根本的なつくりにおいて決定的な違いがあります
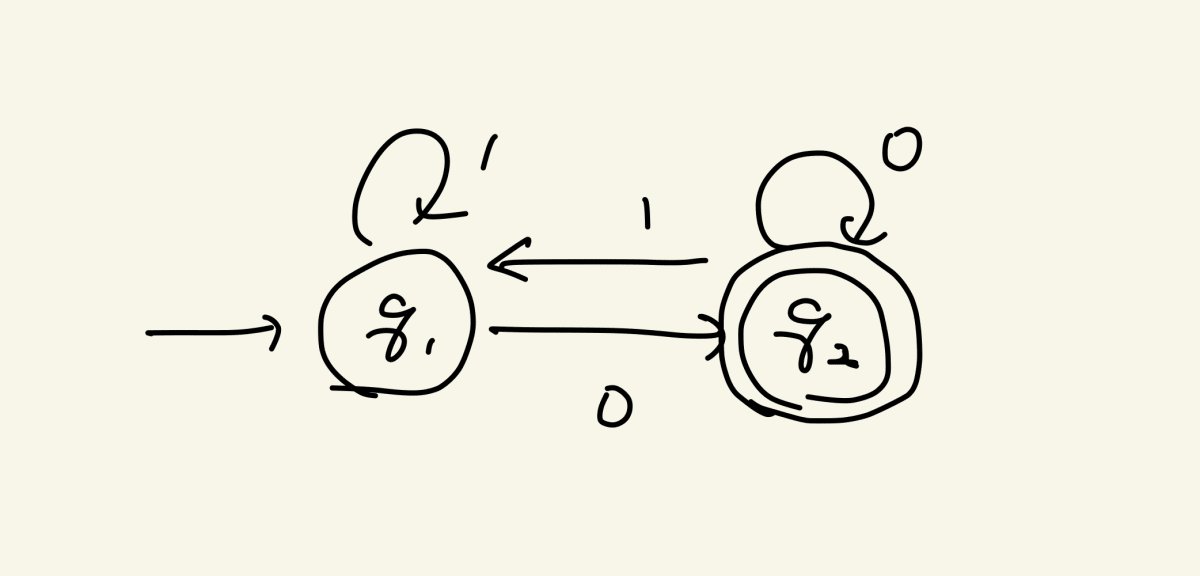
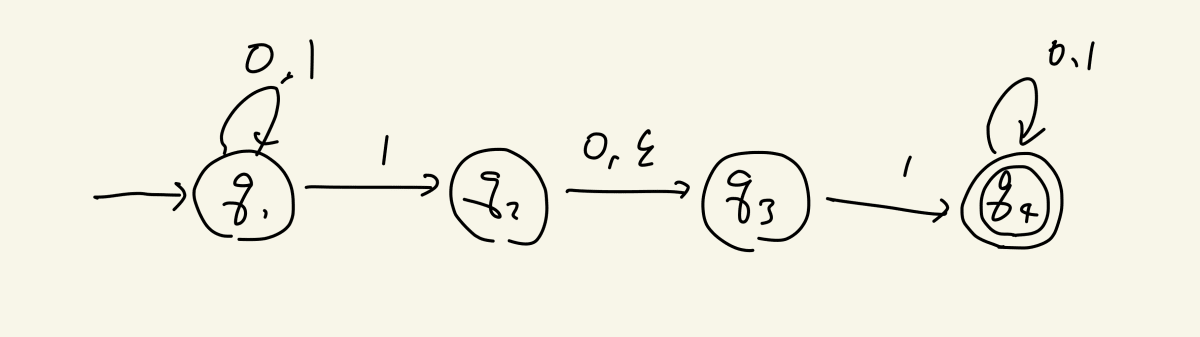
さて、最初のオートマトンはいずれの状態においても、0もしくは1が与えられたときの状態遷移が1つだけ定義されています
2番目のオートマトンはそれとは対照的です。例えばq1は1に対応する遷移が2つ定義されていますし、q2には1に対応する遷移がありません。q3での0に対応する遷移もありません。それに、q2から謎のεという記号で遷移が定義されていますね
ここで、右のようなオートマトンを動かす際には下記のようにするとルールを定めてしまいましょう
- 入力に対してとれる状態遷移をすべて再現し、最後に行き着いた状態の中に受理状態が含まれていれば、その入力を受理するとみなす
- いまいる状態において、遷移が定義されていない入力を受け取った場合は、そこで処理を中止して受理されなかったこととする(その時点で受理状態にいたとしても、受理したことにはしない)
- εは「空文字列」を表すこととする。すなわちεで定められた遷移の先へは、文字を使わなくとも遷移することができる(何も読み込まないまま、ノーコストで状態を遷移できるということ)
さて、このタイプの少しややこしいオートマトンは状態が1つに決定されていないために「非決定性有限オートマトン(non-deterministic finite-state automaton: NFA, NDFA)」と呼ばれます
逆に、状態が常に1つに定まるオートマトンを「決定性有限オートマトン(deterministic finite-state automaton: DFA)」と呼びます
DFAのひみつ
さて、決定性有限オートマトン(ここからはDFAと呼びましょう。大丈夫です、すぐに慣れるはずです)の表現力は高く、例えば下記のDFAの正規言語は「少なくとも1つの1を含み、かつ、最後に現れる1の後ろに偶数個(0個含)の0を含む文字列」の集合です
他にも例えば下記を受理できるDFAが作れます。それほどDFAの表現力は豊かなのです
- 少なくとも3つの1と、少なくとも2つの0を含む文字列
- 1で始まり、(010)を0回以上繰り返したうえで、最後が1で終わる文字列
ところでDFAかNFAかに限らず、オートマトンを構成するということは「文字列全体の集合を2グループに分けてみる」ことに等しいですね。その2グループとは要するに「所定のパターンにマッチするグループ」と「所定のパターンにマッチしないグループ」のことです
ここで正規表現とオートマトンの関係にピンとくる方がいるかもしれません。そうです、我々はある正規表現とある文字列を与えられた時、その正規表現に対応するオートマトンを作ることができれば、そのオートマトンに文字列を食べさせることでその文字列が正規表現にマッチするかが分かるのです
「え、それだけのためにこんな長々と?」と思われるかもしれませんね。大丈夫です、これだけではありません!形式言語理論は驚くべきことを明らかにしました
それすなわち「DFAが表現できる言語群は正規表現が表現できる言語群に等しい」のです!
今回おさえたい要点
ここで念のため、あらためてこの記事でお伝えしたいことを確認しておくと、それは「すべての正規表現がDFAに変換できること」でした
では早速、その要点をこれから一緒にみていきましょう
すべての正規表現はDFAに変換できる!
正規表現の定義
まずは正規表現というものが何かをきちんと定義しておきましょう
標準的な正規表現は下記のように帰納的に定義されますので、今回もこれを採用してみます。「帰納的な定義ってなんのこと?」と思っても、まずは一旦眺めてみてください
- 何か1つの文字は正規表現である
(aとか、あとか、!とか。とにかく、取り扱いたい文字は1文字なら正規表現とみなす) - 空文字は正規表現である → 今回はあまり気にしないで下さい
- φ(空集合)は正規表現である → 今回はあまり気にしないで下さい
- 正規表現R1と正規表現R2があるとき、R1 | R2 (集合でいうところの和集合, OR)は正規表現である
- 正規表現R1と正規表現R2があるとき、R1・R2 (連結)は正規表現である
- 正規表現R1があるとき、R1*(0回以上の繰り返し)は正規表現である
このように定義したとき、これは意外といつもの正規表現だったりします
なんだか仰々しいものに見えますが、要するに「正規表現を作りたかったら、1文字から始めてORか連結か繰り返しで大きくしていってね」ということです
例えば正規表現を下記のように組み合わせていくことで、より大きな正規表現を作っていけます
- ‘a’
- ‘b’
- ‘ab’
- ‘a|b’
- ‘ab(a|b)’
- ‘ab(a|b)*a’
ほらね、意外と簡単でしょう?
いざ、証明のメインアイデア!
正規表現は帰納的に定義されている、つまり小さな部品をもとにしてその組み合わせとして定義されているものでした
おかげさまで、当たり前ですがすべての正規表現を上でやったような「小さな部品の組み合わせ」の結果とみなして問題ないことがわかります
さて、私たちが考えているのはなぜすべての正規表現がDFAに変換できるのかということでした。それを明らかにするためのアイデアとして、「小さな部品の組み合わせ」をオートマトンでも実行してみるというのはどうでしょうか
すなわち、このようなことです
まず、正規表現の最も基本的な「部品」である1文字の正規表現については、1文字を受理する非常に簡単なDFAを構成することができます
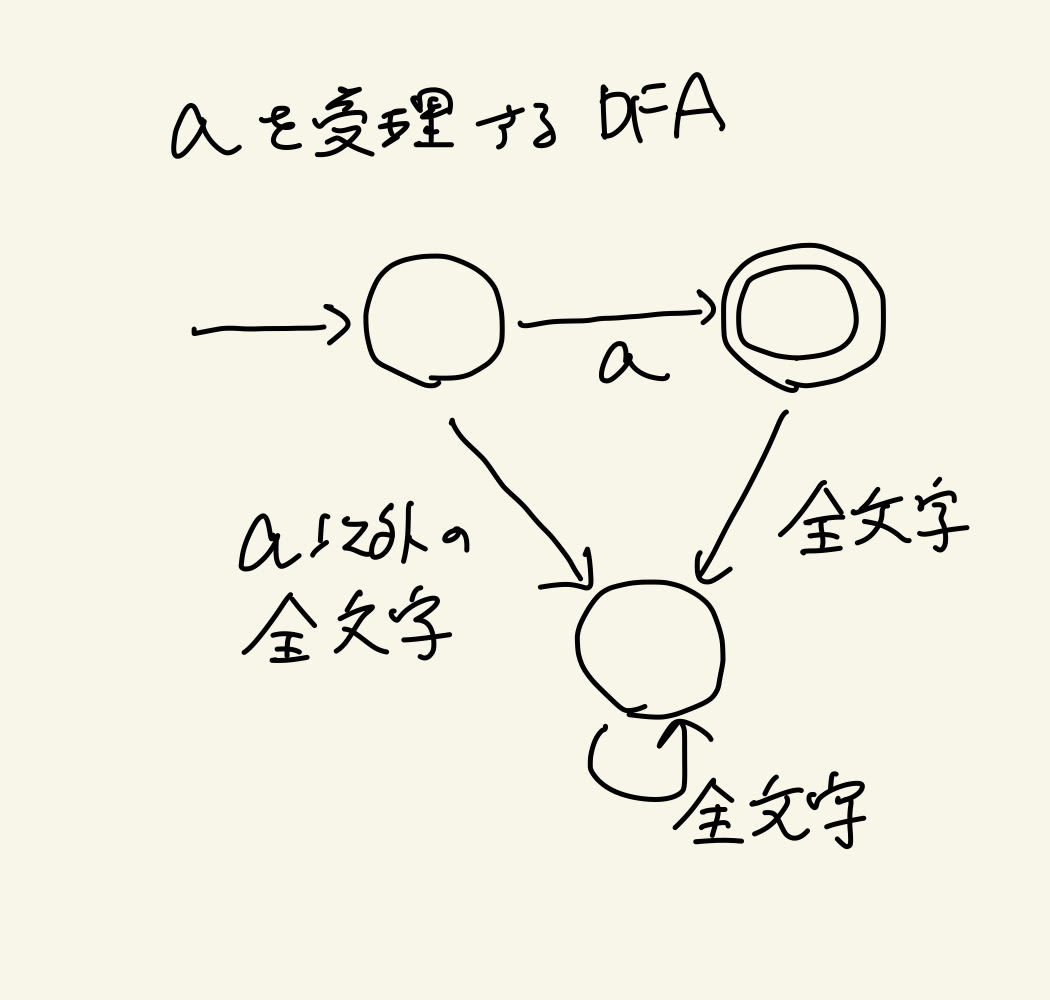
一応説明すると、このオートマトンは、1文字目でa以外の文字が来た場合や2文字目以降が続く場合に「ゴミ箱」に突っ込んでいくようになっています
話を戻して、もし’a|b’を表すDFAが作りたいなら、和集合演算に対応するDFAの組み合わせ方(アルゴリズム)を発明したうえで、’a’を表すDFAと’b’を表すDFAを対象にそれを実行すればよいのです
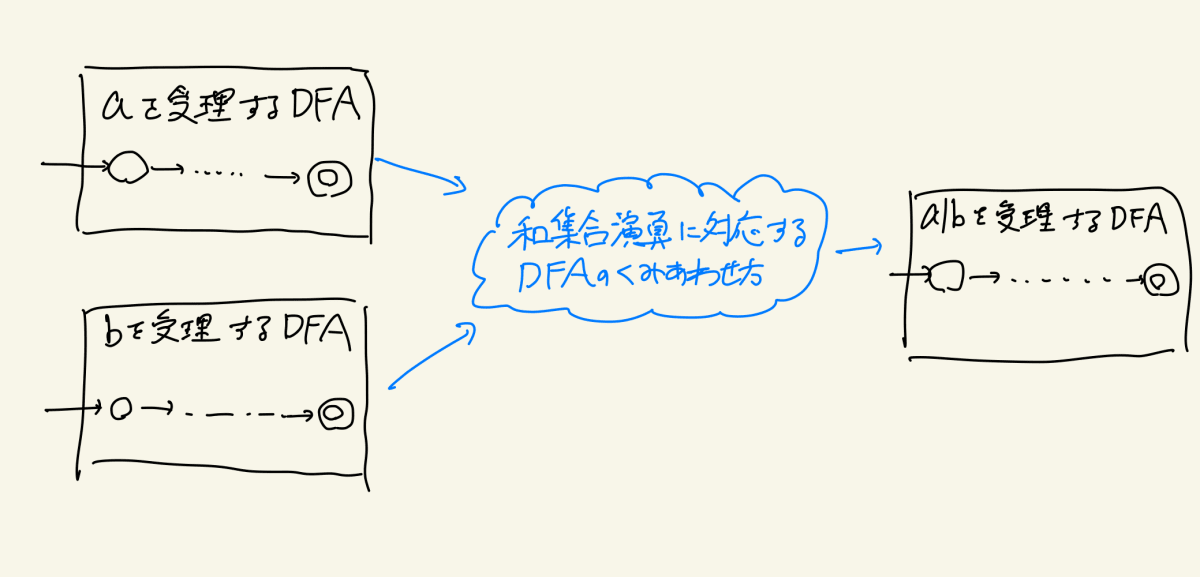
同じことを連結、スター演算でもやれば(すなわち、DFAの連結やスター演算に相当するアルゴリズムを発明すれば)、すべての正規表現をDFAで表せることが証明できますね
これが証明のメインアイデアです。もうここまで来たら、あとは少しです!さっそく取り掛かりましょう
DFAの和集合をとる
まずは和集合演算に相当するアルゴリズムを考えてみます
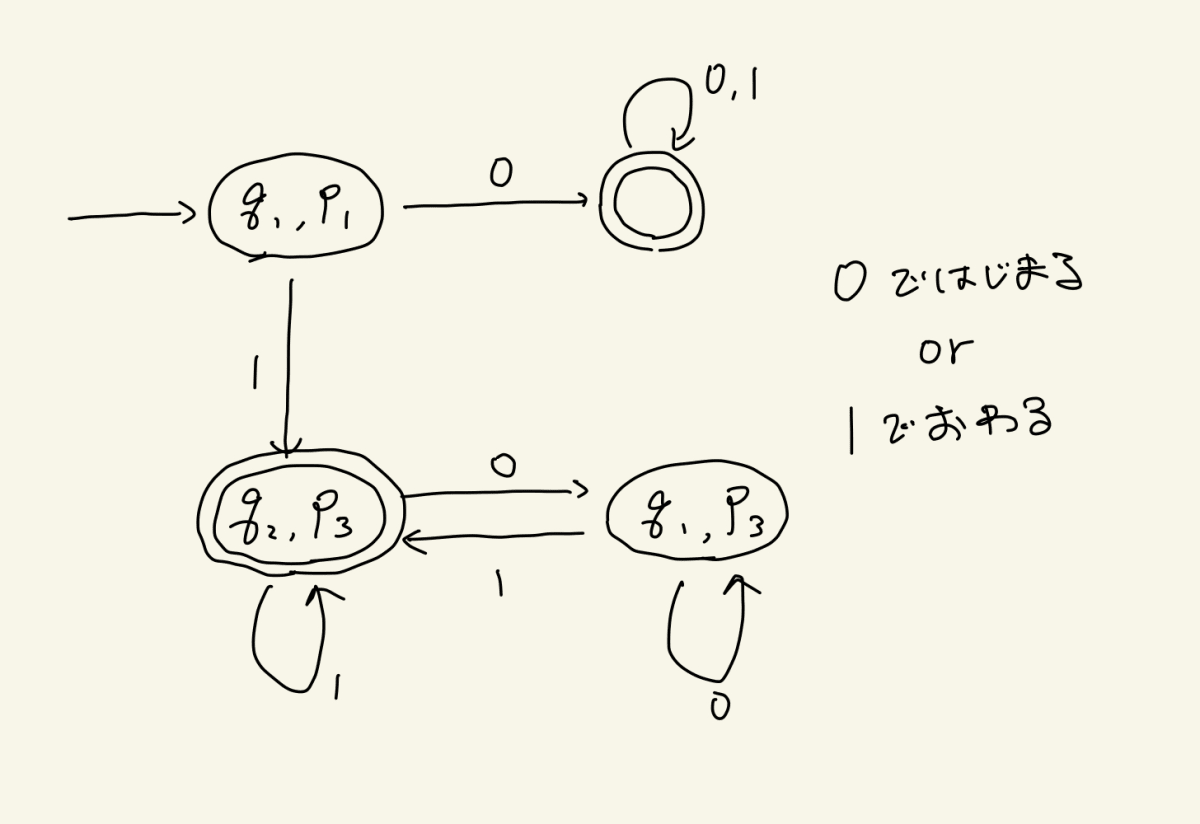
下記2つのDFAの和集合となるようなDFAを実際に構成してみてください(文字は{0,1}の2種類とします)
- 1で終わる文字列を受理するDFA
- 0で始まる文字列を受理するDFA
つまり、0で始まるOR1で終わる文字列を受理するDFAを作ってみようということです
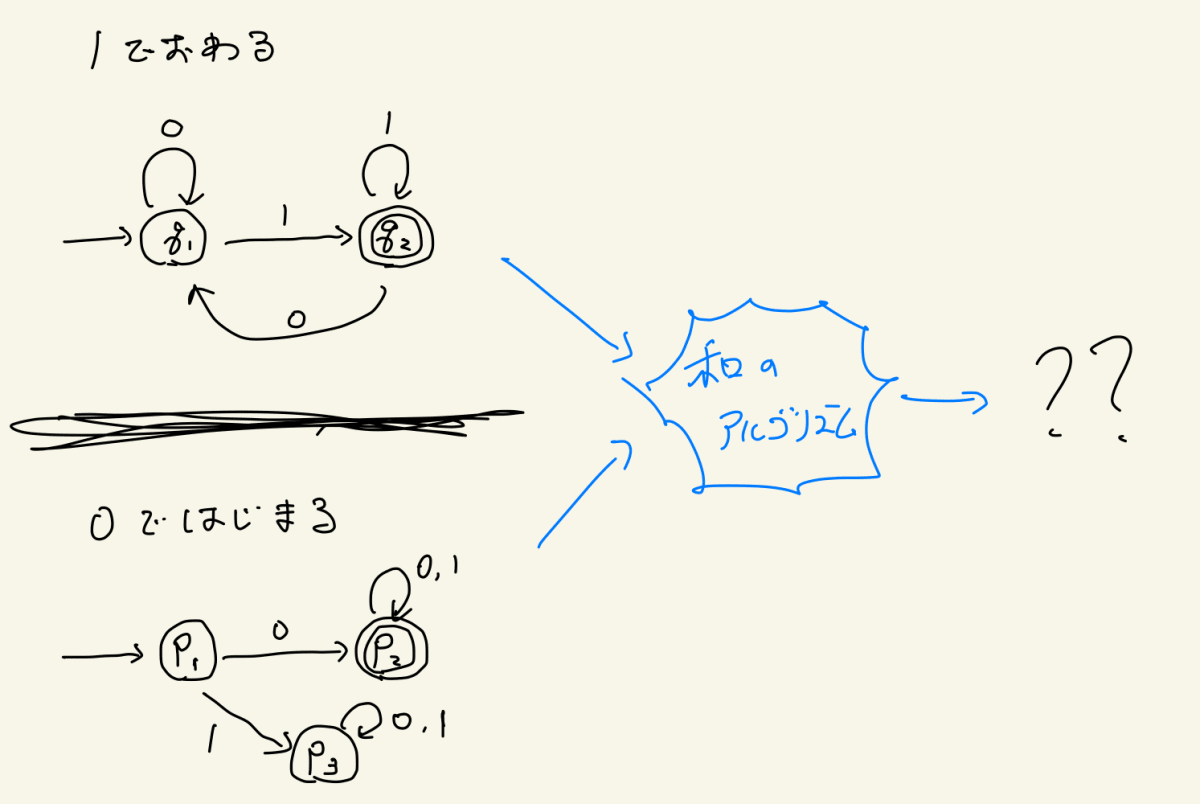
さて、いかがでしょうか
作れた方も作れなかった方(大丈夫です!)も、ここからが本番です
いま2つのDFAの和をとったDFAを構成する際に実践した方法はいつでも誰がやってもできるように、手順書を書くことができますか?
私たちがやりたいのはそういうことです。いつでもどんなDFAに対しても、誰もが和をとれる方法を考えたいのです。でなければ、いつでもDFAの和をとれるとは到底言えません。すごく小さなこどもでも、オートマトンが何かということさえ分かれば、できてしまう方法が必要なのです
すなわち、DFAの和集合演算のアルゴリズムを発明する必要があります
しかしどのようにしたらよいのでしょうか?
2つのDFAがそれぞれどの状態にあるのかを常に記録することができればよいということが肝です
非常に愚直に以下のようなやり方を考えてみてはどうでしょうか
まず、上の2つのDFAを同時に作動させた時、最初はそれぞれp1とq1にいることになります
それから0が出た場合と1が出た場合を考えてみます。まずは1が出た場合。この場合、p1はp3に遷移し、q1はq2に遷移します。図にすると下記のようになりますね
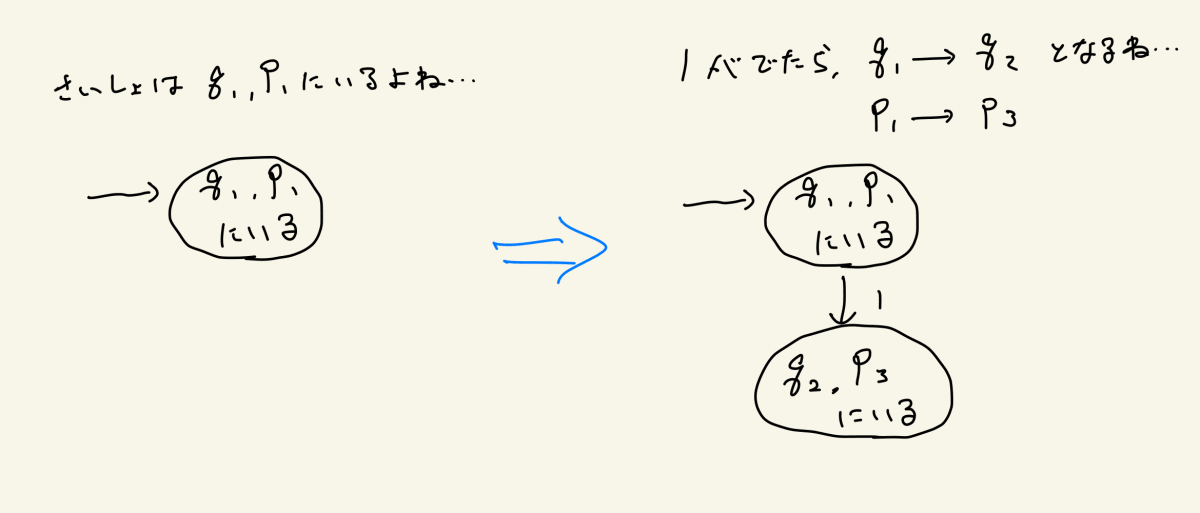
これをどんどん続けていくと、こうなります
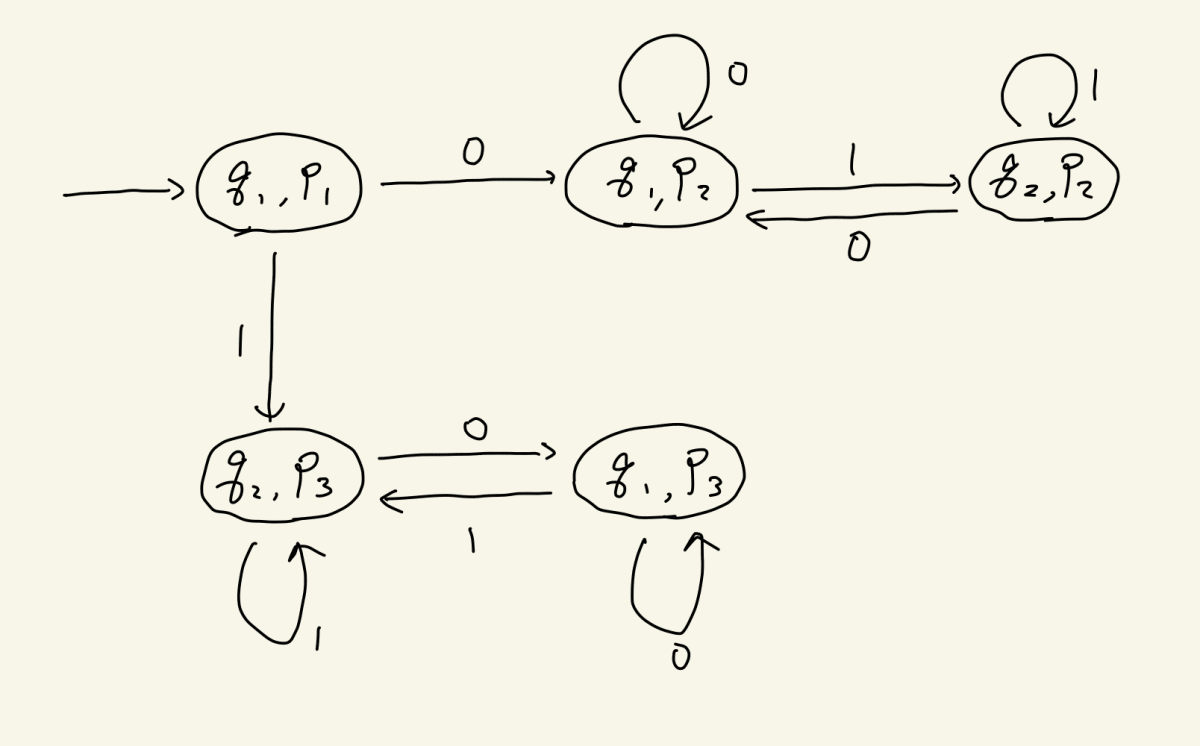
矢印を書ききりましたね!ところで、最後に受理状態をつけなくてはいけません。ORで2つのDFAをつないでいるのですから、どちらか一方の受理状態を含む状態は受理状態になるはずです。それを定義して完成です
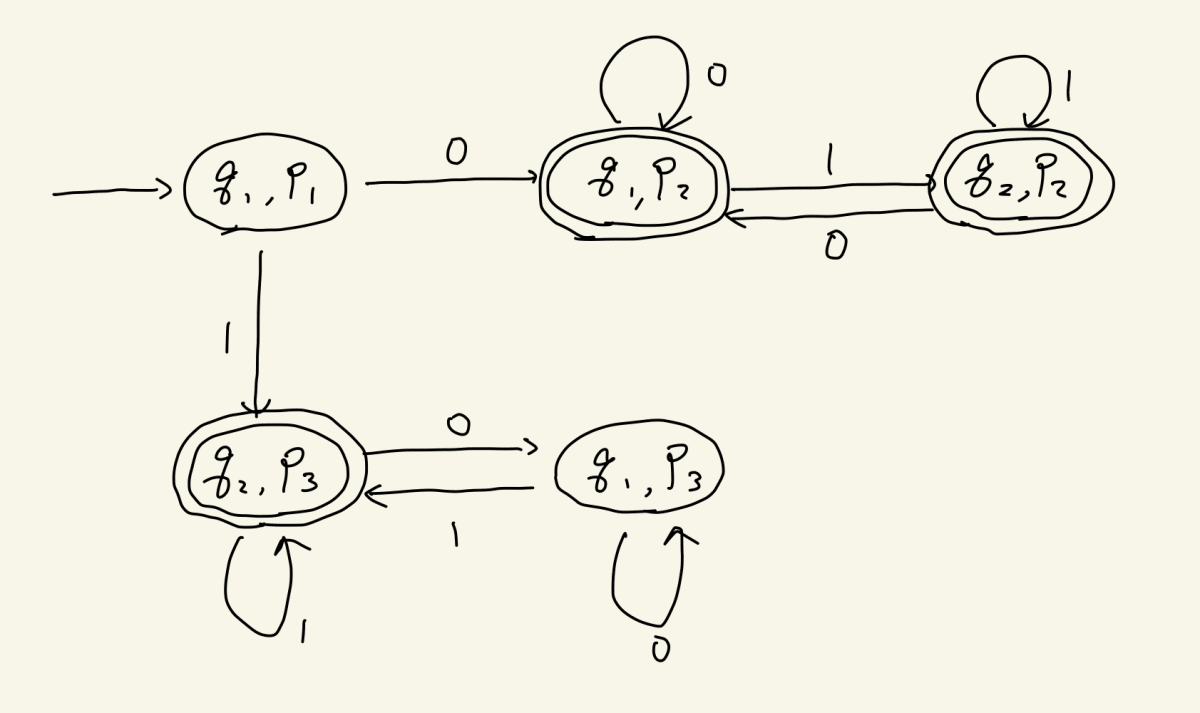
今回はたまたまもう少しきれいにできそうなので、もうちょっとやってみます。ただし、これはいま考えている「和集合演算のアルゴリズム」とは関係ないですよ!
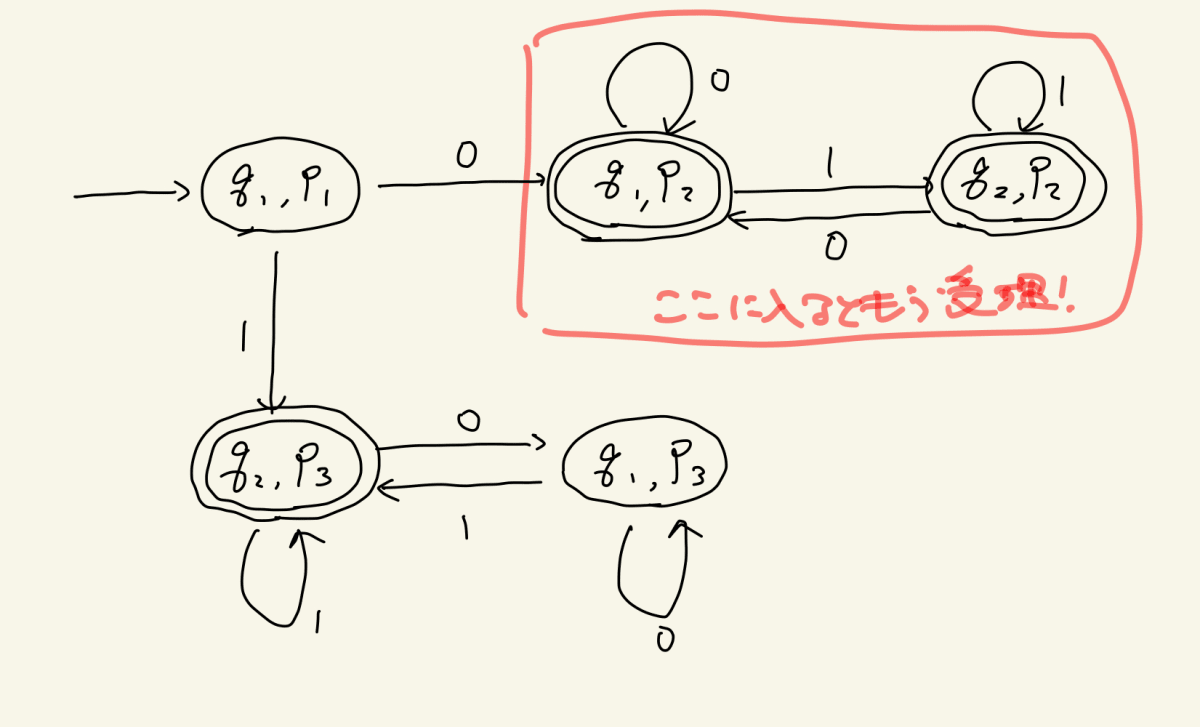
ついに和集合演算ができました!
これをどんなときでも戸惑わないように(こどもがスケートリンクを走りながらでもできるように)定式化してみると、下記のようになるはずです
- 状態と状態の掛け合わせからなる状態を定義する(演算対象となる2つのDFAがそれぞれm個、n個の状態を持っていたら、mn個の状態を定義することになりますね)
- 各状態の遷移については、掛け合わせている2つの状態それぞれの遷移先を再度かけ合わせた状態へ定義する(同じ文字に対してそれぞれのDFAがp1→p2、q1→q3と遷移するなら、その文字について{p1,q1}→{p2,q3}という遷移を定義する)
- 掛け合わせの中に受理状態が1つでも含まれている状態をすべて受理状態とする(p2が受理状態なら、{p2,q1}や{p2,q4}は受理状態となる)
これこそがDFAの和集合演算アルゴリズムです!完成したDFAの状態の構造、すなわちメモリ構造はまるで2つのDFAの状態をメモしているかのようですね。こうしてDFAの和集合ができるようになりました
DFA同士を連結させる!……いや、待てよ?
さて次は連結です。先ほどの例を使ってぜひ少し考えてみてください
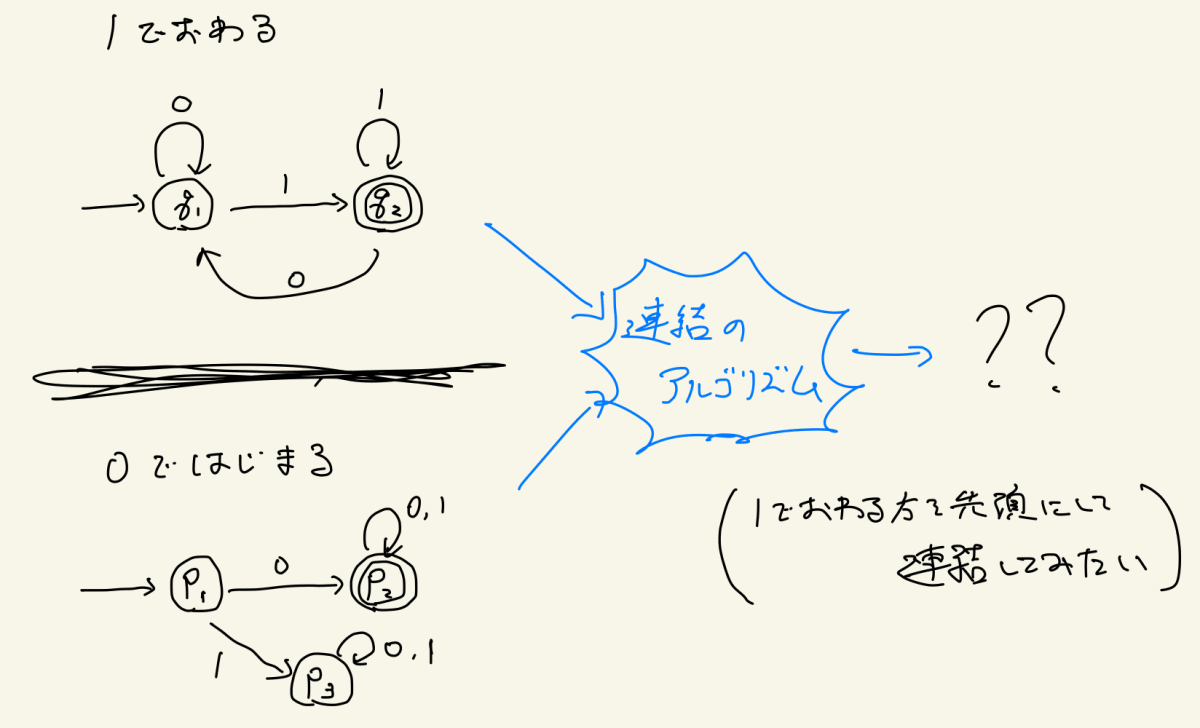
さて少し考えてみると、なかなか難しいのではないでしょうか
少なくとも、単純につなぐだけではできないはずです。なぜなら、それで出来上がったDFAは、入力される文字列のどこまでを初めのDFAが処理すべきか、どこからを2番目のDFAが処理すべきかということを決めることができないからです。
さて、ここで突然ですが、アルゴリズムを適用した末に出来上がるオートマトンがNFAでも良いと言われたらどうでしょうか
そうです、すごく簡単になるのです!
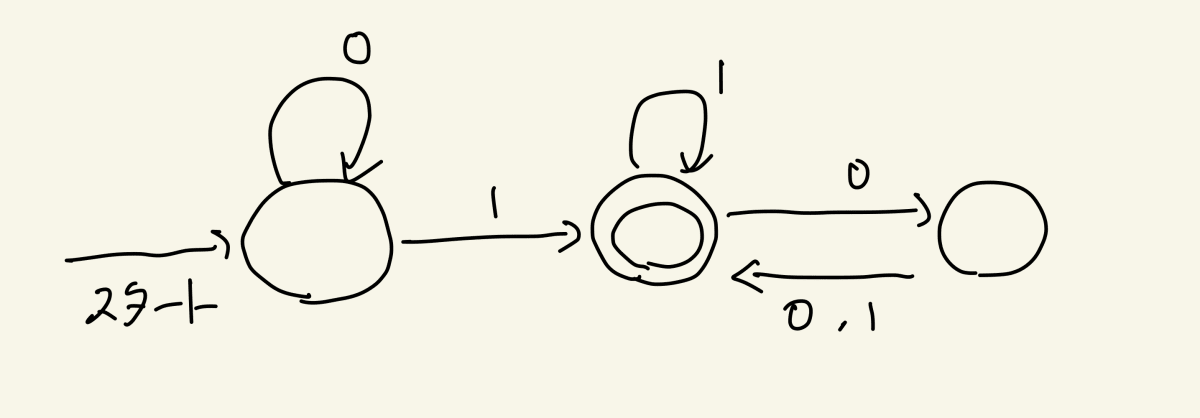
なぜなら文字列同士の連結に相応するDFAは下記のように構成できてしまうからです。ここでεは空文字、すなわち文字を受け取ることなく状態を遷移できる「ノーコスト魔法」の文字であることを思い出してください!
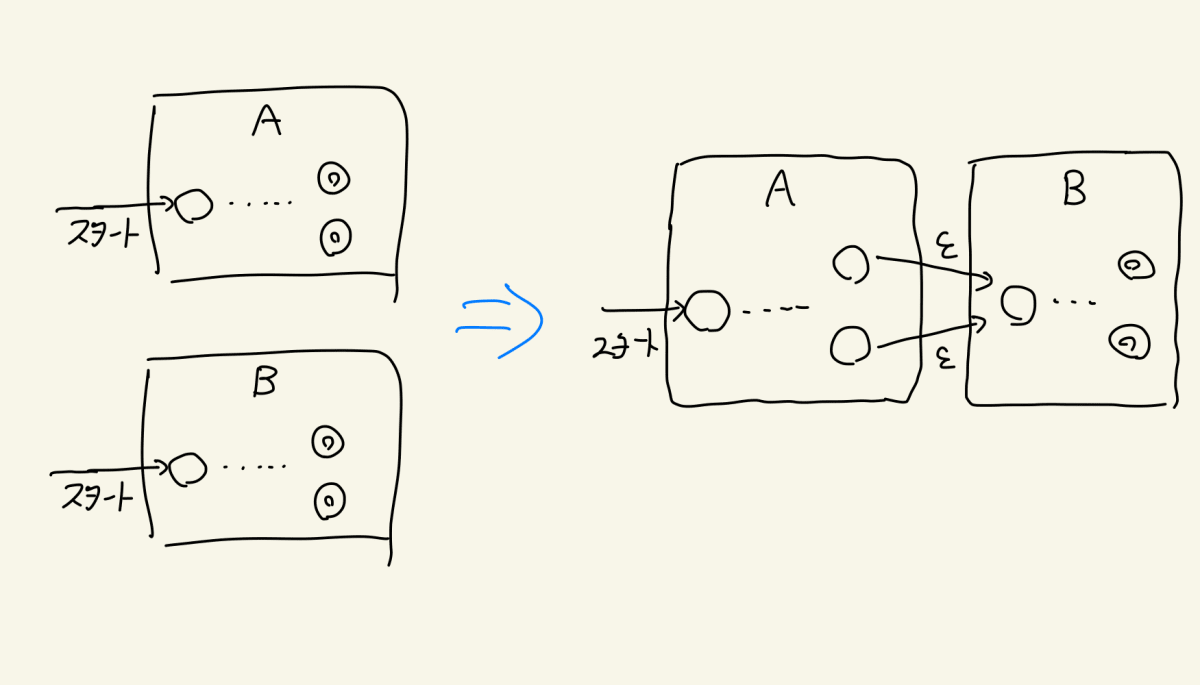
「いやいや、元々はDFAで考えていたでしょう。反則ですよ」という声が聞こえてきますね
さて、ここでとんでもないショートカットを導入します!実はNFAからDFAを生成することができるのです
おお、我にDFA錬金術を授けん
NFAのおさらい
念のため、NFAの動かし方をもう一度だけおさらいしましょう
このようなオートマトンを動かす際には下記のようにすると定めました
- 入力に対してとれる状態遷移をすべて再現し、最後に行き着いた状態の中に受理状態が含まれていれば、その入力を受理するとみなす
- いまいる状態において、遷移が定義されていない入力を受け取った場合は、そこで処理を中止して受理されなかったこととする(その時点で受理状態にいたとしても、受理したことにはしない)
- εは「空文字列」を表すこととする。すなわちεで定められた遷移の先へは、文字を使わなくとも遷移することができる(何も読み込まないまま、ノーコストで状態を遷移できるということ)
このタイプのオートマトンを、状態が1つに決定されていないために「非決定性有限オートマトン(non-deterministic finite-state automaton: NFA, NDFA)」と呼ぶのでした
DFAによるNFAモノマネ
さて、ここでの目標はNFAをDFAで再現することです
もうだいぶ慣れてきた頃合いだと思いますので、さっそく考えてみてください!もちろん必要であれば、これまでで登場したNFAやDFAをご自由にお使いくださいね
ここまでくると、説明するよりも見てもらう方が早そうです。さっそくやってみましょう。先ほどのNFA(下図)をいまからDFAにしていきます
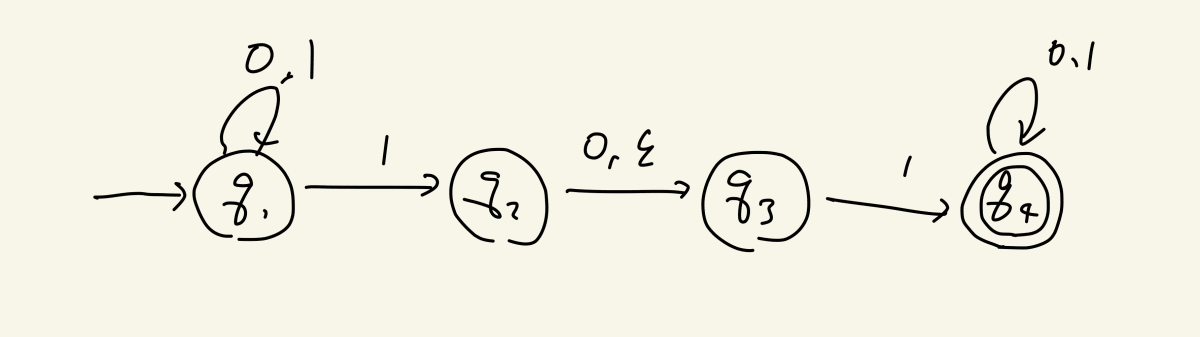
ポイントからお伝えしてしまうと、今回も和集合の時と同じノリでいけてしまいます。すなわち、NFAを動かしているとしたときに自分がいまいる状態をメモしていくのです
スタートした時点でq1にいますので、まずはq1をメモしましょう
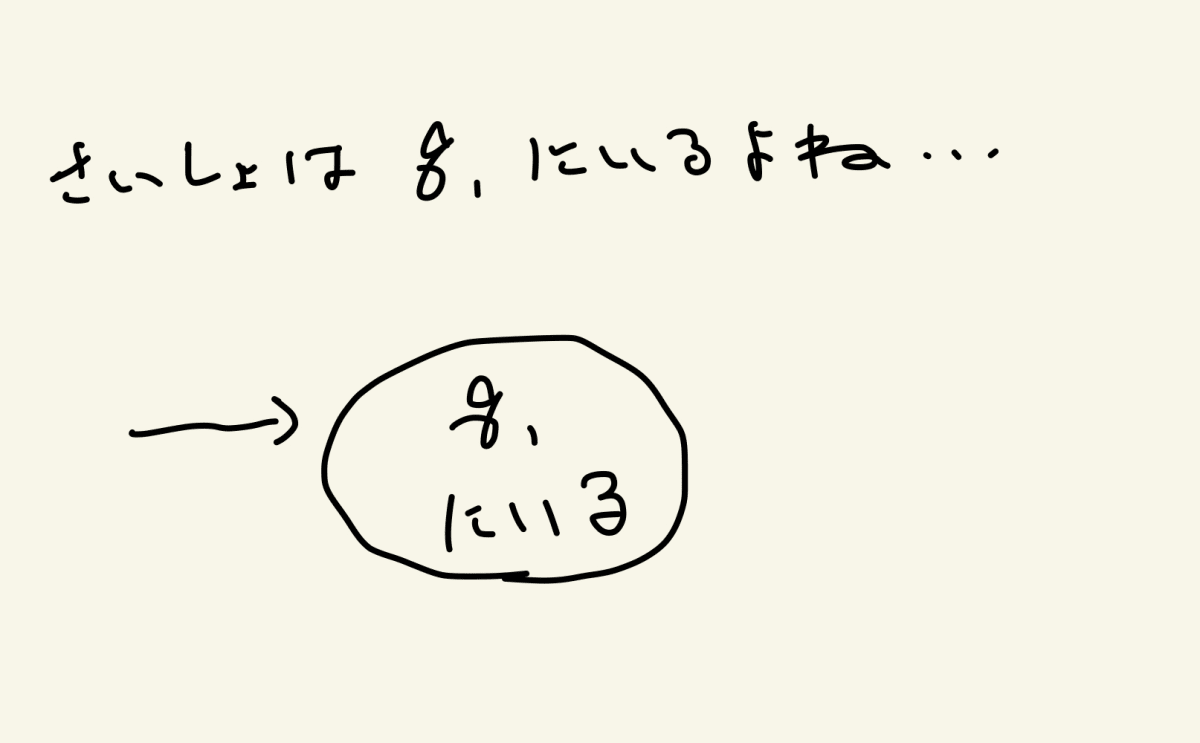
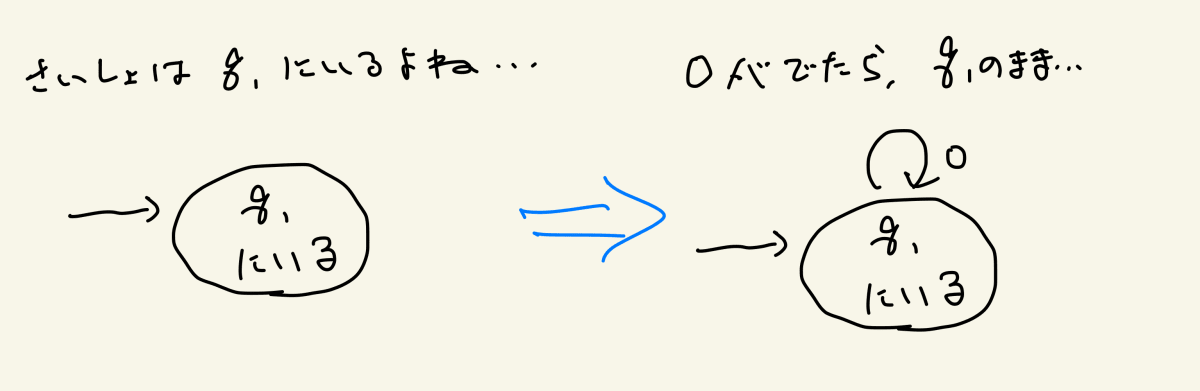
では0が出たら?q1のままですね。q1に対応する状態から自分自身へ、0による遷移を追加します
q1から1が出たらどうなるでしょうか?これまで見てきたように、q1とq2とq3にいることになりますね。それを新たにメモして、始めの状態から1で遷移させましょう
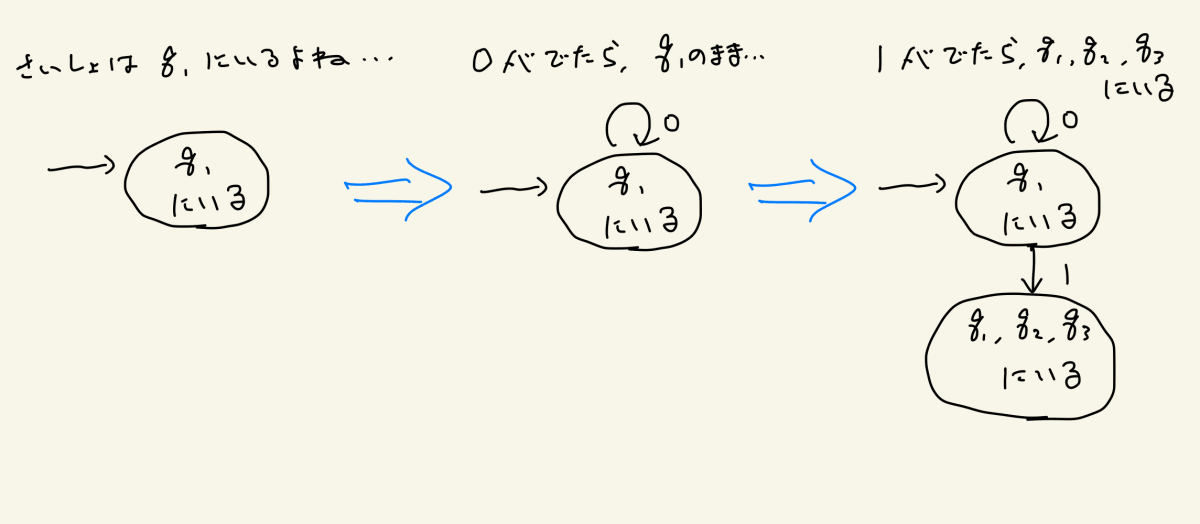
さて、このようにして自分がどの状態にいるのかメモしながらどんどん状態と遷移を書き足していくと、下記のようになります
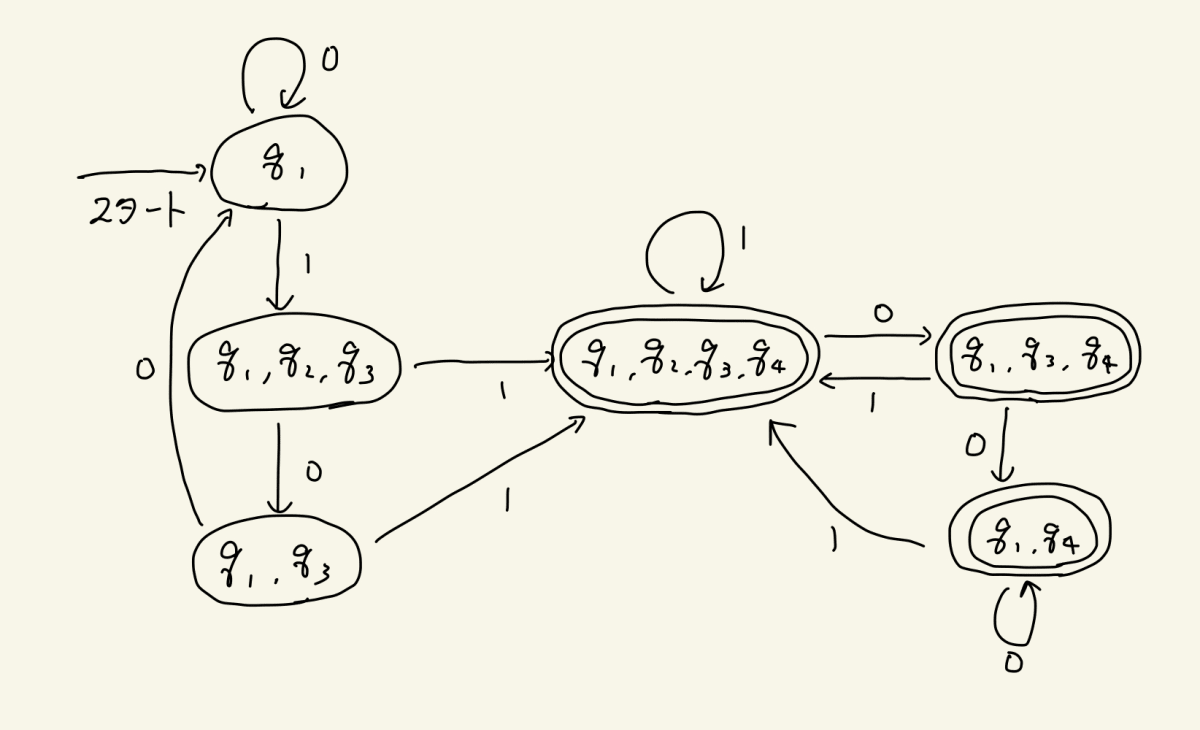
完成しました!このDFAに’011’という入力を与えると受理されることをぜひ確かめてみてください
さて、NFAをDFAに変換する手続きをまとめてみましょう
- NFAの状態の全ての組み合わせ(べき集合)を考え、各組に対応する状態を定義する(もとのNFAがn個の状態を持っていたら、2^n個の状態を定義することになりますね)
- 各状態の遷移については、その状態に含まれるもとのNFAの状態全ての遷移先を考え、その遷移先の組み合わせに対応する状態へ定義する(例えば、もとのNFAにてaという文字でp1→p5およびp2→p2,p3,p4と遷移するなら、新しいDFAの{p1,p2}状態から{p2,p3,p4,p5}状態へaという文字で遷移を定義する)
- 掛け合わせの中に受理状態が1つでも含まれている状態をすべて受理状態とする
さあ、いまや私たちはDFAとNFAとを同じように扱っていいことになりました。これが驚くべき効果を持つことが次の節で分かるでしょう!
ゴール!(正規表現を思うがままに!)
そもそもこの記事の目的をもう一度思い出しておくと、「すべての正規表現がDFAに変換できること」に納得することでした
しかし今の私たちはNFAからそれに等しいDFAを構成できること、つまりNFAとDFAを同等に扱ってよいことを知っています。ということは、私たちが本当に納得しなければならないことは「すべての正規表現がDFAにNFAに変換できること」です!
さて証明の方針は、正規表現を作る手段である和集合演算、連結演算、スター演算(繰り返し)をDFAでも再現することでした。そして、和集合演算はDFAでも再現できたものの、連結演算が大変だったところでNFAがDFAと同等であることを証明したのでした
連結演算がNFAでできることは、実は先ほどフライングで見せてしまっていましたね
これだけです!εは魔法の空文字でしたから、連結した文字列はその前半部分である「Aに受理される部分」がAで読み込まれた後に、残りの部分をBで読み込まれて無事に受理されます
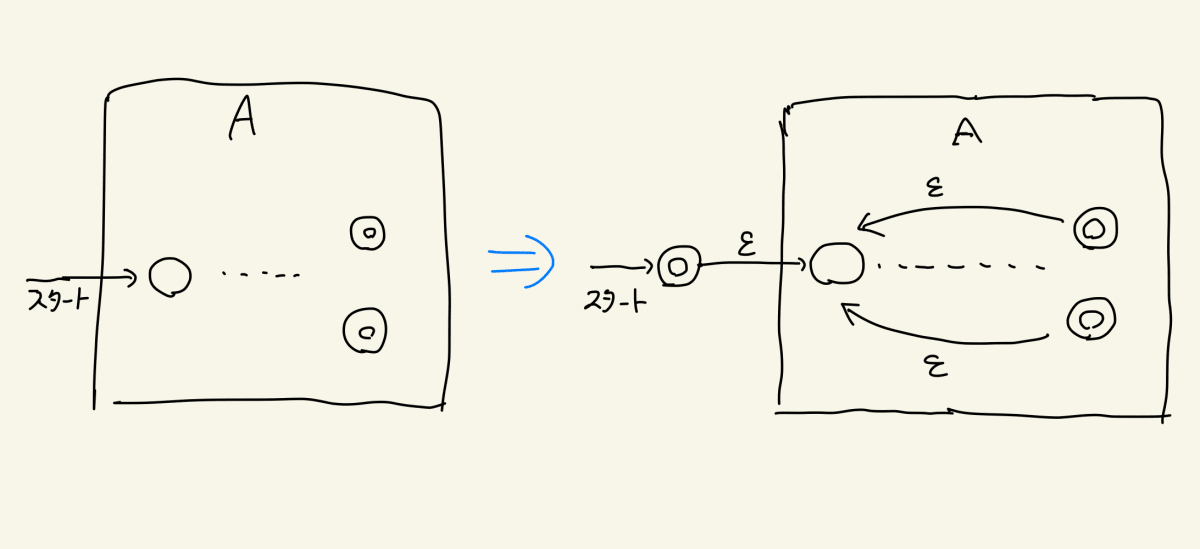
ではスター演算、すなわち繰り返しについてはどうでしょうか
なんと下のようにして終わりです!左のもともとのオートマトンを、右側のように改造してしまえばいいのです。文字列が何回繰り返されるかNFA自身は分かっていなくとも、魔法の空文字を使うことでその不確定性が吸収されるのです
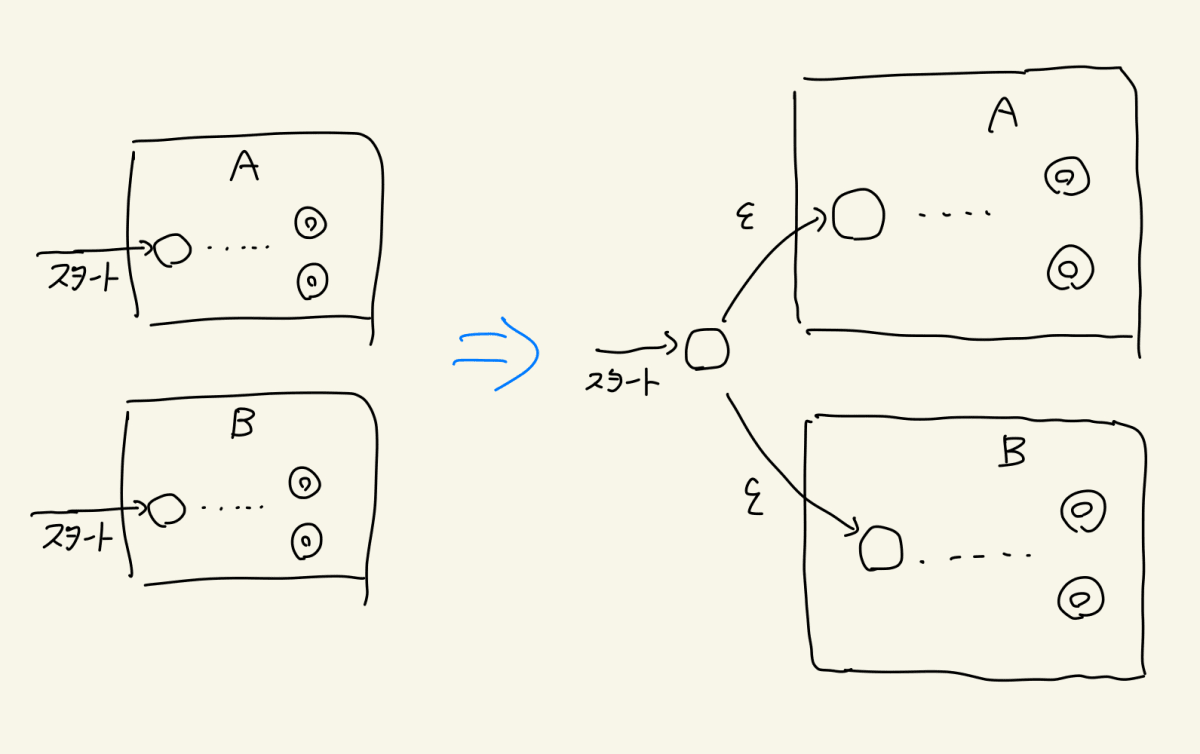
ちなみに和集合演算もNFAならすっきりしますね
けっきょく何がどうなったのか
さて、前節では正規表現の全ての演算をNFAで再現できることを確認しました
加えて、NFAからはそれと等しいDFAが構成できることを示していたはずです
となると、正規表現は下記のようにしてDFAに変換できますね!
- ある正規表現があったとき、もともとの文字単体に対して和集合演算、連結演算、繰り返し演算をどのような順番で適用して構成された表現なのかを読み取る
- もともとの文字単体を受理するDFAまたはNFAを用意し、正規表現から読み取ったのと同じ順番で和集合演算、連結演算、繰り返し演算を適用してNFAを作る
- できあがったNFAをDFAに変換する
いやはや、おつかれさまでした……!
これが「すべての正規表現がDFAに変換できること」を確認する長い長い道のりだったわけです!
まだまだ旅は続く?
さて、今回の記事では正規表現がDFAに変換できることを示しましたが、これは形式言語理論もしくは計算理論の世界を垣間見たに過ぎません。下のような色々なテーマがまだまだ数え切れないほどあります
- 今回の内容を厳密に議論するにはどのような概念および議論の方法が採用できるか
- DFAを正規表現に変換するにはどうするのか
- 正規表現では表現できない文字列とはどのような文字列か
- 正規表現よりも複雑で豊かな形式言語はどのような計算モデルに対応するのか
- そもそも複雑な計算とは何か
- 計算とは何か
- ここには書ききれないくらい本当にもっともっとたくさんある、色々な面白い話
上記で気になる項目がある方は、冒頭でもご紹介した下記の本を手にとってみて下さい!この記事の内容も多くをこの面白い本に依っています
さて最後になりますが、今回の記事を読んで形式言語や計算についての理論に興味を持ってくれれば嬉しいです!
ではでは、よいオートマトンライフをお送り下さい
Discussion
なんとなく聞いたことはあるけど理解していなかった、オートマトンの詳細な説明ありがとうございます。
(まだよく理解していませんが)
以下の用語の部分は typo と思われます。
読んで下さりありがとうございます!!私も、なんかこんな話あったよなあという記憶がきっかけで今回調べるに至りました。
ご指摘頂いた部分はtypoでしたので、修正させていただきました。こちらでも一応お調べしたところ、finite-stateという言葉が使われるようだったのでそのように致しました。
ありがとうございます!!