MySQLのインデックスの貼っていいとき悪いときを原理から理解したいよ😭
今回答えを出したい問いはこちら!!
- インデックスはどのような仕組みを以て、何を実現したいものなのか
- それを踏まえたとき、インデックスはどういう場合になぜ貼る方が良いのか。また、どういう場合になぜ貼らない方が良いのか
大体分かっているよって人はサヨナラって感じのおさらい記事だぜ!!!!それじゃいってみよー🎉
あと、おれは今回MySQLにしぼっていくぜ👶
ってわけでOracleとかに興味があるやつは引き返しな!
indexの概要
公式の見解としては「where句を使ったselectクエリの実行速度を向上させるために実装されている、各行へのポインターのような振る舞いをする仕組み」って感じ👶
The best way to improve the performance of
SELECToperations is to create indexes on one or more of the columns that are tested in the query. The index entries act like pointers to the table rows, allowing the query to quickly determine which rows match a condition in theWHEREclause, and retrieve the other column values for those rows.
MySQL 8.0 Reference Manual; https://dev.mysql.com/doc/refman/8.0/en/optimization-indexes.html
indexに用いられるデータ構造
後述の仕組みに触れれば分かって頂けると思うが、indexとは「レコードを特定の列の値に着目して、適切なデータ構造で整理したもの」だと言うことができる。インデックスの種類により用いられるデータ構造は異なるが、MySQLにおいてはB+treeが主流である。
MySQLにおけるインデックスの種類と用いられているデータ構造
(MySQL 8.0 Reference Manual; https://dev.mysql.com/doc/refman/8.0/en/mysql-indexes.html)
| インデックスの種類 | 使用対象の限定 | データ構造 | 補足 |
|---|---|---|---|
| index key | 特になし | B+tree | 複数列にまたがって生成できる(=複合インデックス) / PK, UKの制約を設定した列に自動で生成される(UKの場合は複合インデックスになりうる) |
| fulltext index (MyISAM) | CHAR, VARCHAR, TEXT 型のcolumn | B+tree | fulltext indexを利用した検索の仕方: https://techblog.gmo-ap.jp/2020/01/06/mysql-innodb-fulltext-search-tuto/ |
| fulltext index (InnoDB) | CHAR, VARCHAR, TEXT 型のcolumn | inverted index | inverted indexの仕組み: https://ja.wikipedia.org/wiki/転置インデックス |
| hash index | メモリテーブル(=MEMORYストレージエンジン使用テーブル)に限定 | array (used with hash function) | hash index/hash functionの仕組み: https://www.mssqltips.com/sqlservertip/3099/understanding-sql-server-memoryoptimized-tables-hash-indexes / b-tree型indexとの速度比較: https://qiita.com/K-jun/items/a86a3829cf796b6d5ad8 |
| spatial index | 空間データ型のcolumnに限定 | R-tree | 空間データの基本的な使い方(2点間距離のクエリ等): https://qiita.com/onunu/items/59ef2c050b35773ced0d / R-treesの仕組み: https://tanishiking24.hatenablog.com/entry/introduction_rtree_index |
注意: MySQLにおいては全てのデータ型に対してindexを作ることができる
(https://dev.mysql.com/doc/refman/8.0/ja/optimization-indexes.html)
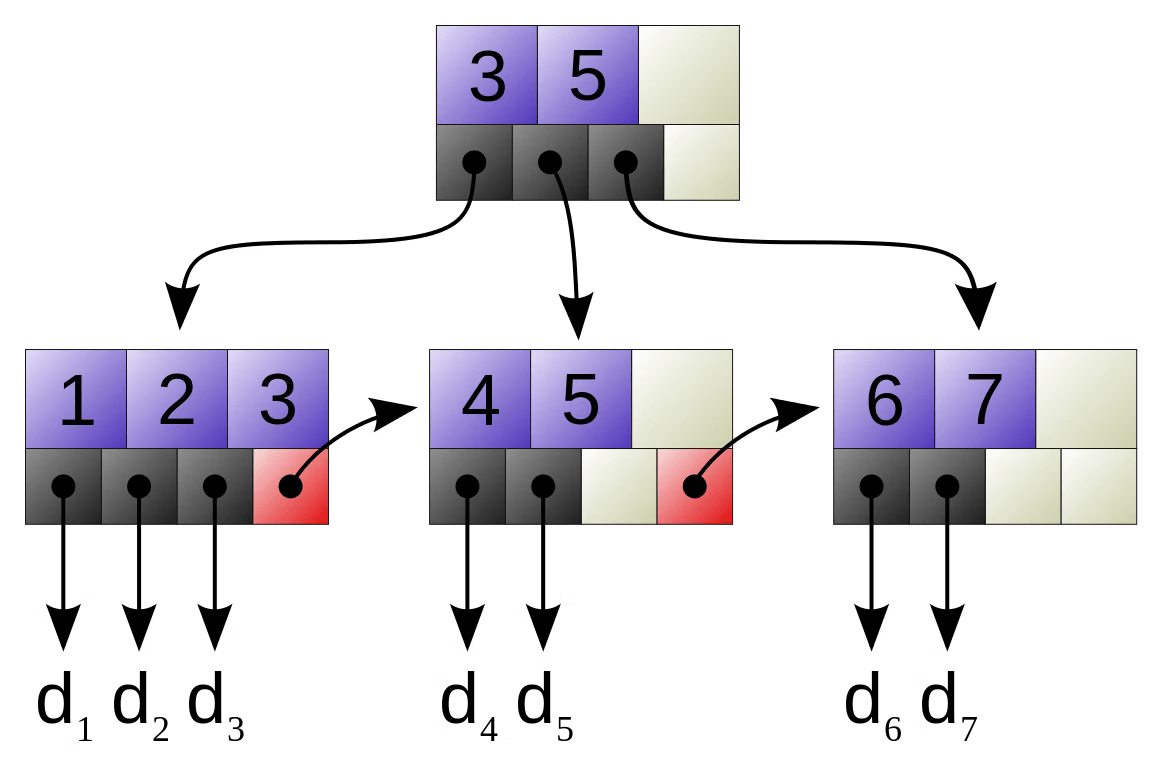
データ構造がクエリを効率化する仕組み(B+treeの例)
どのindexも特定のデータ構造を用いることで全てのレコードを見ることなく、レコードの検索ができるようになる。
イメージを掴むために、具体的な仕組みをB+treeの場合で実際に見てみる
B+treeの定義
ざっくり言うと下記のような木構造だと思えばいいかも👶
- 複数の枝があり
- 葉同士がつながっていて
- 実データは葉にのみ置かれている
より厳密っぽく(これも厳密ではないけど)言うと下記のような感じ
- ルートノードと子ノードは下記を持つ
- キー
- 子ノードへのポインタ
- リーフノード(末端のノード)は下記を持つ
- キー
- 実際のデータへのポインタ
- 他リーフノードへのポインタ
参考画像: B-treeインデックス入門; https://qiita.com/kiyodori/items/f66a545a47dc59dd8839
補足: 2分木、ALV木、からのB-tree
この補足はかなりの部分を「B-treeインデックス入門」に依拠しています。もとの記事を是非お読み下さい!!; https://qiita.com/kiyodori/items/f66a545a47dc59dd8839
さて御存知の通り、2分木を使うと探索がlogNでできる。
でもバランスしていないとNになっちゃうから、気をつけて作らないといけない。

でもデータとは常にうつろうもので、挿入や削除がしたい。そうすると木はバランスしない。
そこで、2分木に回転という操作を加えてはどうか?回転で木の高さを一定に保つ。これがAVL木。
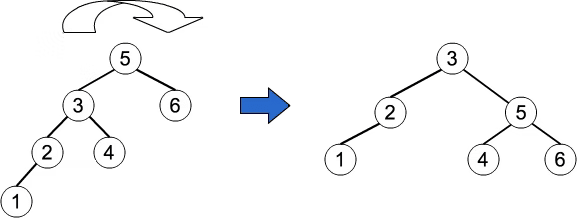
これだけでも嬉しいものだけど、下に潜っていく回数をもっと減らせばもっと計算量が減るはず(もちろんノードごとの判定に要する計算量は同じくらいであることが必要)。
そのように考えて、ノードが持つ枝の数を増やしたのがB-tree。
そしてB+treeは実際のデータを最下層だけに持たせたB-tree。下図はB+tree。
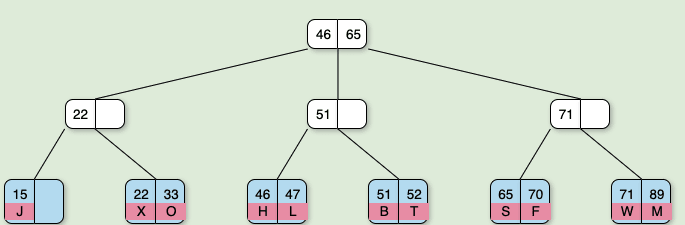
上記画像出典: OpenDSA; https://opendsa-server.cs.vt.edu/ODSA/Books/CS3/html/BTree.html
なお、範囲検索は範囲の開始地点にあたる葉ノードを見つけ、葉から葉へと順次たどっていけば良いため、B+treeは範囲検索が得意と言われる。
B+treeにおける検索、追加、削除などの実際の動き
OpenDSAなるサイトで実際にB+treeを動かせる。
めちゃくちゃインデックスのイメージが湧くのでチェケラ必須!!!!
https://opendsa-server.cs.vt.edu/ODSA/Books/CS3/html/BTree.html
クラスタインデックスの仕組みとメリット・デメリット
クラスタインデックスの仕組み
クラスタインデックスとは、葉ノードにインデックス対象のカラムの値だけでなく、全てのカラムの値が埋め込まれたインデックスのこと。
InnoDBで採用され、通常はプライマリーキーインデックスがクラスタインデックスになっている。
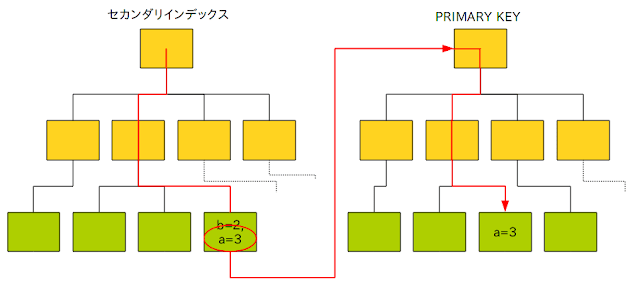
InnoDBにおいてはクラスタインデックス以外のインデックスをセカンダリインデックスと呼び、それらの葉ノードにはインデックス対象の列の値とプライマリーキーが埋め込まれている
すべての InnoDB テーブルは、行のデータが格納されているクラスタ化されたインデックスと呼ばれる特別なインデックスを持っています。
...
テーブル上で PRIMARY KEY を定義すると、InnoDB ではそれがクラスタ化されたインデックスとして使用されます。
...
テーブルに PRIMARY KEY が定義されていない場合、MySQL はすべてのキーカラムが NOT NULL の UNIQUE インデックスを最初に検索し、InnoDB はそれをクラスタ化されたインデックスとして使用します。
...
クラスタ化されたインデックス以外のインデックスは、すべてセカンダリインデックスと呼ばれます。InnoDB では、セカンダリインデックス内の各レコードに、行の主キーカラム、およびセカンダリインデックスに指定されたカラムが含まれます。InnoDB では、クラスタ化されたインデックス内で行を検索する際に、この主キー値が使用されます。
MySQL 8.0 リファレンスマニュアル; https://dev.mysql.com/doc/refman/8.0/ja/innodb-index-types.html
図で見ると分かりやすいです。「知って得するInnoDBセカンダリインデックス活用術!」 http://nippondanji.blogspot.com/2010/10/innodb.htmlより、わかりやすい2つの図を引用させて頂きます👶
これがクラスタインデックス。
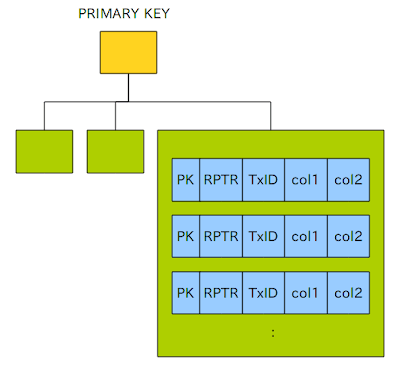
こっちがクラスタインデックスとセカンダリインデックスの関係性。
クラスタインデックス使用のメリット・デメリット
下記ブログにて全てを語ってくれています。
このような構造になっていることには利点と欠点があるが、大きな利点は主キーの値で検索をすると非常に高速だということだ。主キーのリーフノードにたどり着いたときには、既にデータのフェッチも完了している。データとインデックスが別々に格納されているタイプのストレージエンジンでは、インデックスからデータの位置を読み取って、その後データファイルからデータをフェッチする。このように二段階の操作が必要であると、キャッシュが効いていない場合には余分なディスクI/Oが生じてしまうだろう。
...
クラスタインデックスのデメリットとしては、インデックスのサイズが大きくなってしまうこと、セカンダリインデックスを用いた検索が遅くなってしまうことなどが挙げられる。
「知って得するInnoDBセカンダリインデックス活用術!」 http://nippondanji.blogspot.com/2010/10/innodb.html
データベースが実際にindexを使うタイミングと、indexを貼ることにより生じうるデメリット
公式ドキュメントを基に、データベースが実際にindexを使うタイミングやindexを貼ることにより生じうるデメリットを下記の図のようにまとめられると考えています👶(まいどお馴染みまさかの手書き)
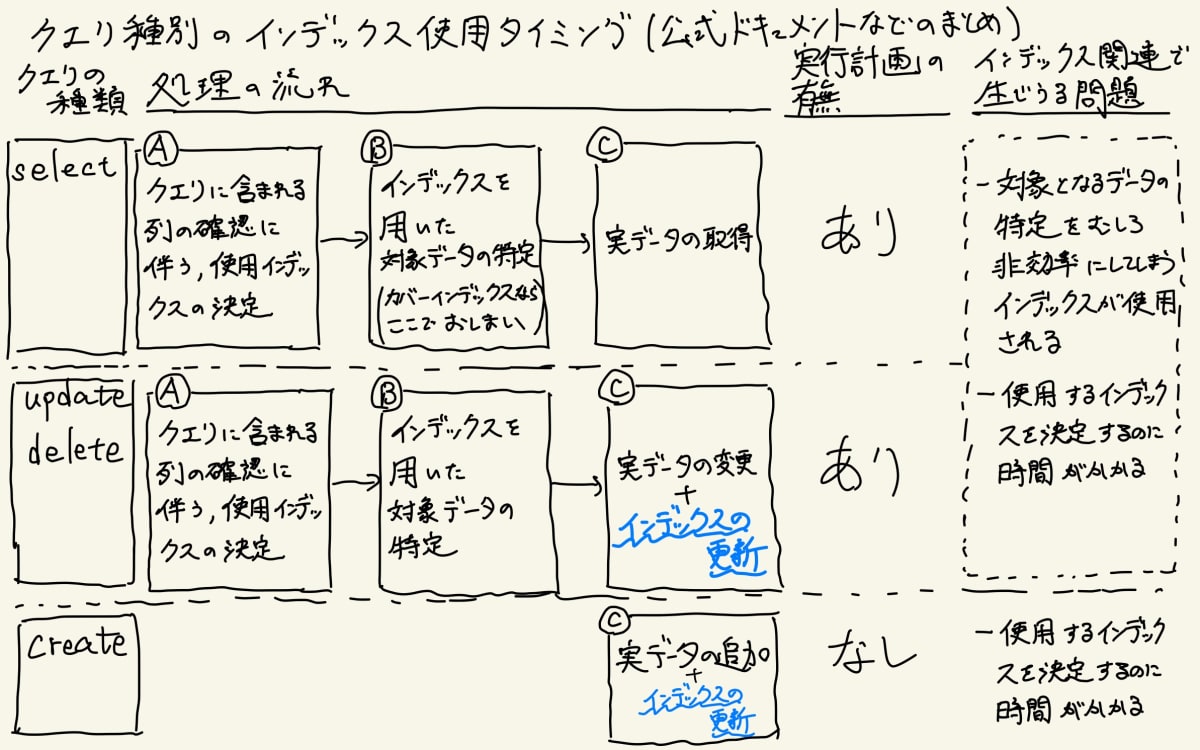
さて、下記に少し詳細。
A. 「クエリーに含まれる列の確認に伴う使用インデックスの決定」の詳細
A-1. 下記のサイトの通り、クエリーに含まれる列が順に確認される
https://qiita.com/ichi_zamurai/items/a8e5e4a37faecf9cd77a#sqlクエリselectの評価順序
A-2. 確認した列が下記条件を満たす時、その列が使用されているインデックスの存在を確認する
参考) MySQLのIndexをはるコツ; https://qiita.com/katsukii/items/3409e3c3c96580d37c2b#indexの使われるとき使われない時
インデックスの存在を確認される条件
- 定数と比較されている (WHERE name = "hogehoge" )
- JOINされている ( WHERE a.name = b.name )
- 範囲指定の対象となっている
- 前方一致のLIKEで指定されている
- MIN(), MAX()で指定されている
インデックスの存在を確認されない条件 - 前方一致でないLIKEで指定されている
- WHERE句の条件として使用されるが、列が式の一部になっている(where col1 * 2 = 2000など)
A-3. 使用インデックスの決定
Aで確認した順番でインデックスの存在を確かめていき、引っかかったインデックスを使う。
なお、複合インデックスは上記の条件に引っかかった列が「複合インデックスのキーの未確認の部分のprefix(左端)を構成する限り」において使用候補となる。ややこしいと思うが、公式ドキュメントの説明がわかりやすい。
テーブルが次のような仕様であるとします。
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
nameインデックスは、last_nameカラムとfirst_nameカラムに対するインデックスです。 このインデックスは、last_name値とfirst_name値の組み合わせに既知の範囲の値を指定するクエリーで、ルックアップに使用できます。 そのカラムはインデックスの左端のプリフィクスであるため、last_name値だけを指定するクエリーにも使用できます (このセクションで後述するように)。
-- nameインデックスは、次のクエリーでのルックアップに使用されます。
SELECT * FROM test WHERE last_name='Jones';
SELECT * FROM test
WHERE last_name='Jones' AND first_name='John';
SELECT * FROM test
WHERE last_name='Jones'
AND (first_name='John' OR first_name='Jon');
SELECT * FROM test
WHERE last_name='Jones'
AND first_name >='M' AND first_name < 'N';
-- nameインデックスは、次のクエリーでのルックアップには使用されません。
SELECT * FROM test WHERE first_name='John';
SELECT * FROM test
WHERE last_name='Jones' OR first_name='John';
MySQL 8.0 Reference Manual; https://dev.mysql.com/doc/refman/8.0/ja/multiple-column-indexes.html
ってわけ。
さて当然の疑問として複数のインデックスが残った場合どうなるんだよという話がある。
この場合はインデックスマージ(複数のインデックスで得られた複数のクエリ実行結果に対して集合演算するようなもの、らしい……)するか、カーディナリティで選択をしていそう。正直この辺りはあまり分かっていない😭
col1 および col2 に対して個別の単一カラムのインデックスが存在する場合、オプティマイザは、インデックスマージ最適化 (セクション8.2.1.3「インデックスマージの最適化」を参照してください) の使用を試みるか、またはより多くの行を除外するインデックスを判断して、そのインデックスを使用して行をフェッチすることで、もっとも制限の厳しいインデックスを見つけようとします
MySQL 8.0 Reference Manual; https://dev.mysql.com/doc/refman/8.0/ja/multiple-column-indexes.html
B. 「カバーインデックス」の詳細
カバーインデックスってなに!?って話ですよねえ。
indexがクエリで使用されている列をもれなくカバーしているとき、それをカバーインデックスと呼びます。カバーインデックスが存在するとき、テーブルへのアクセスは行われないし、実行速度ももちろん上がっちゃいます。
インデックスのみのスキャンは、あらゆるチューニング法の中でも最強の方法の1つと言えるでしょう。where句の評価のために テーブルにアクセスする必要がないだけでなく、インデックス自体にお目当ての列があるなら、テーブルに全くアクセスしなくてもよいのです。
クエリ全体をカバーするためには、SQL文に出てくる全ての 列をインデックスに含めなくてはなりません。次の例のように、select句に含まれる列も例外ではありません。
CREATE INDEX sales_sub_eur
ON sales
( subsidiary_id, eur_value )
-- 上記indexは下記クエリのカバーインデックスとして機能する
SELECT SUM(eur_value)
FROM sales
WHERE subsidiary_id = ?
use the index, luke!; https://use-the-index-luke.com/ja/sql/where-clause/the-equals-operator/concatenated-keys
インデックス・クエリの良い悪いの具体的な方針
ここまで踏まえて考えられる、インデックスやクエリを考える際の具体的な指針が下記のようになる。1つのインデックスに良い面も悪い面も両方含まれることが多く、最終的には個別に計測を行わないと分からないだろうが一般論として。
こんなインデックスは嫌だ😭
-
よく値が変更される列で作る(もちろんクエリでの使用頻度とは相談)
インデックスの更新に時間がかかってしまうため、クエリが多少速くなっても全体的なパフォーマンスの低下につながりうる -
よく値が削除される列で作る(もちろんクエリでの使用頻度とは相談)
削除が増えるにつれてインデックスが虫食いになってしまい、クエリ効率が下がっていく
https://atmarkit.itmedia.co.jp/ait/articles/0409/10/news095_4.html
https://dev.mysql.com/doc/refman/5.6/ja/innodb-file-defragmenting.html -
WHERE句やJOINで使われない列で作る
明らかに意味がない -
規模が小さいテーブルで作る
そもそも全件走査にかかるコストが低いので、インデックスの管理コストが上回ってしまう -
(InnoDB限定で)プライマリーキーの値が長い
InnoDBはプライマリーキーを全てのインデックスの葉ノードに持つため、プライマリーキーが長いとインデックス容量が大きくなっていく主キーが長くなると、セカンダリインデックスで使用される領域も多くなるため、主キーは短い方が利点があります。
MySQL 8.0 Reference Manual; https://dev.mysql.com/doc/refman/8.0/ja/innodb-index-types.html -
実質的に重複してしまっている
下記のような場合、単一のインデックスの方は要らないはず補足) InnoDBにおいてはセカンダリインデックスの葉ノードにプライマリーキーが含まれることをふまえると、下記の2インデックスが全く同等となることに注意create index id_index on user(id); create index id_index on user(id, name, age);-- PRIMARY KEYがid列であるという前提のもとで下記の2インデックスは同等 create index name_id_index on user(name, id); create index name_index on user(name);
こんなインデックスが良いかもね👶
- WHERE句やJOINの条件としてよく使う列で作る
よく使うクエリが速くなるね -
よく使うクエリーのカバーインデックスとなるような複合インデックス
最高! -
NULLが多い列でのインデックス
インデックスはNULL値を除いて作成されるため、NULLが多い列からNULLではない値を取り出す処理が速くなる
こんなクエリが良いね😊
-
評価される順番を考慮したときに、複合インデックスにうまくハマるクエリ
素晴らしい!
おわりに
MySQLのインデックスの奥の深さを調べていてすごく感じた。知らないこともまだまだありそうです。ひしひしと感じる。
データベースの勉強をもう少しがんばっていきます👶
Discussion