leetcodeをRustでやっていき
Rustでやる感じ。
Rustだとテストも便利そう、あと個人的な勉強のため
leetcodeは標準入出力を経由せずに関数を実装すればいいだけなので便利だ・・・
- Palindrome Number
授業でやった右シフトと左シフトの考え方が活かせそう・・・?
コード
impl Solution {
pub fn is_palindrome(x: i32) -> bool {
// 当然マイナスは回文にならない
if x < 0 {
return false;
}
// いきなり最上位はわからない
// だるま落としみたいに
// 最下位を引っこ抜いて別の変数に詰めていき、ひっくり返した変数を作る
let mut reversed_memory = 0;
let mut source = x;
while (source > 0) {
// 逆メモリを10倍(左シフト)する
reversed_memory *= 10;
// ソースの最下位の数字を取り出す
let last_digit = source % 10;
// 逆メモリに最下位の数字を詰める
reversed_memory += last_digit;
// ソースを10で割り、右シフト
source = source / 10;
}
// 逆メモリとソースが一致していれば回文
return x == reversed_memory;
}
}

- add two numbers
これも授業でやった加算器を真似して作ってみる
参照として現在のノードを持っておく
コード
impl Solution {
pub fn add_two_numbers(
l1: Option<Box<ListNode>>,
l2: Option<Box<ListNode>>,
) -> Option<Box<ListNode>> {
// 多分、加算器の実装をすればいいと思う
// 桁上りに注意
let mut keta_agari = 0;
let mut l1 = l1;
let mut l2 = l2;
let mut result: Option<Box<ListNode>> = None;
let mut current_node = &mut result;
loop {
// それぞれのリストの最下位の桁を取り出す
let l1_val = match &l1 {
Some(node) => node.val,
None => 0,
};
let l2_val = match &l2 {
Some(node) => node.val,
None => 0,
};
// それぞれのリストの最下位の桁を足す
let sum_over10 = l1_val + l2_val + keta_agari;
// もしゼロなら終了
// TODO: ここの条件が微妙な気がする
if sum_over10 == 0 && l1.is_none() && l2.is_none() {
return result;
}
// 桁上りがあれば次の桁に持ち越す
let sum = sum_over10 % 10;
keta_agari = sum_over10 / 10;
// 結果のリストに足す
current_node = match current_node {
Some(node) => {
node.next = Some(Box::new(ListNode::new(sum)));
&mut node.next
}
None => {
result = Some(Box::new(ListNode::new(sum)));
&mut result
}
};
// それぞれのリストの次の桁があればそれを取り出す
l1 = match &l1 {
Some(node) => node.next.clone(),
None => None,
};
l2 = match &l2 {
Some(node) => node.next.clone(),
None => None,
};
}
}
}

うーむ
- Longest Substring Without Repeating Characters
シャクトリ法?というものを雰囲気で実装した
???これでいいのか・・・???
ハッシュマップでアルファベットが登場した回数をメモして二回以上のものがあるかで条件分岐しようとおもったが
そうすると必要ないとわかりきっているはずの処理をする必要がある
したがって途中で外側ループにcontinueで抜けるようなコーディングにした
これでいいのかはわからん・・・
コード
impl Solution {
pub fn length_of_longest_substring(s: String) -> i32 {
// 問題の意図まとめ
// 登場する文字に被りがないようにしないといけない
// これってシャクトリ法?というので解けるんじゃないか?
// Stringをcharに変換
let s: Vec<char> = s.chars().collect();
// ここから効率化のためにわかりきっている結果を返す部分
// もし空文字なら、0を返す
if s.len() == 0 {
return 0;
}
// もし一文字以下なら、1を返す
if s.len() == 1 {
return 1;
}
// ここまで
// まず、左端と右端のインデックスを格納する変数定義
let mut left = 0;
let mut right = 0;
// 最長の長さを格納する変数
// 最終的にこれが結果になりますやんか
let mut max_length = 0;
// 右のインデックスが最後を超えるまでループ
'outer: while right < s.len() {
// 含まれている文字の集合
// ハッシュマップじゃなくて、すでに含まれているかどうかを判定するため集合を使う
// この集合に存在していれば既知のアルファベットや!
let mut count_map = std::collections::HashSet::new();
// println!("left: {}, right: {}", left, right);
// 含まれている文字を追加、もしくはカウントを増やす
for c in s[left..=right].iter() {
// println!("c: {}", c);$
if count_map.contains(c) {
// 重複がある場合、左端を進める
// その後whileループの方でcontimue
left += 1;
continue 'outer;
// 汚いコードでごめんなさいの顔
} else {
count_map.insert(c);
}
}
// 重複がない場合
// もし最大長よりも長い場合、最大長を更新
if max_length < right - left + 1 {
max_length = right - left + 1;
}
// 右端を進める
right += 1;
}
return max_length as i32;
}
}

Longest Substring Without Repeating Characters 効率化リベンジ。
既に登場した記号を管理するハッシュ集合をループ毎に作成していたが、すべてのループで使い回せることがわかった
またその場合、右インデックスは最大でも増えるのは一つであるため、過去にちゃんと要素を検証していれば、ループ一回につき一番右の要素のみを検証すれば良いっぽい
- 左のインデックスを進め、新たなアルファベットに遭遇するケースは存在しない
- 既知の範囲内になるので
- 右を進めて、右端の文字がアルファベット集合に含まれていない場合
- 重複がないのでアルファベット集合に加えて右インデックス++
- 右を進めて、右端の文字がすでにアルファベット集合に含まれている場合
- 左インデックスを++する&左インデックスを++するのでアルファベット集合から該当記号削除
- 左を進めて、右端の文字がすでにアルファベット集合に含まれている場合
- これはおそらく3の後に必ず実行されることになる
- 重複がないのでアルファベット集合に加えて右インデックス++(2と同じ)
より、以下のようにまとめてしまうことができる
- もし一番右の要素がアルファベット集合内に存在すれば
- アルファベット集合から該当要素を削除
- 左インデックス++
- 存在しなければ
- アルファベット集合に該当要素を追加
- (もし最大長変数より右-左+1が大きければ更新)
- 右インデックス++
コード
impl Solution {
pub fn length_of_longest_substring(s: String) -> i32 {
// 問題の意図まとめ
// 登場する文字に被りがないようにしないといけない
// これってシャクトリ法?というので解けるんじゃないか?
// Stringをcharに変換
let s: Vec<char> = s.chars().collect();
// ここから効率化のためにわかりきっている結果を返す部分
// もし空文字なら、0を返す
if s.len() == 0 {
return 0;
}
// もし一文字以下なら、1を返す
if s.len() == 1 {
return 1;
}
// ここまで
// まず、左端と右端のインデックスを格納する変数定義
let mut left = 0;
let mut right = 0;
// 最長の長さを格納する変数
// 最終的にこれが結果になりますやんか
let mut max_length = 0;
// 含まれている文字の集合
// ハッシュマップじゃなくて、すでに含まれているかどうかを判定するため集合を使う
// すべてのループで共有することができる
// この集合に存在していれば既知のアルファベットや!
let mut count_map = std::collections::HashSet::new();
// 右のインデックスが最後を超えるまでループ
while right < s.len() {
// もしcount_mapに含まれているなら
if count_map.contains(&s[right]) {
// 左端を進める
count_map.remove(&s[left]);
left += 1;
} else {
// もし含まれていないなら、右端を進める
count_map.insert(s[right]);
// 最長の長さを更新
max_length = std::cmp::max(max_length, right - left + 1);
right += 1;
}
}
return max_length as i32;
}
}
これが参考になる?
確かに今回は特定の要素の重複確認だったからループ全体で一つのデータを持って部分要素の検証でよかったっぽい
一方で範囲内の合計とかになれば範囲全体をすべて検証する感じになるんだろうか O(N^2)?

- Longest Palindromic Substring
すべての組み合わせをタプルで取得してから、それぞれについて回文になるかをチェック。
とりあえず解けたけども、これはもちろん効率的ではなさそうだ・・・
コード
impl Solution {
pub fn longest_palindrome(s: String) -> String {
// charのベクタに変換
let s: Vec<char> = s.chars().collect();
// もし空文字なら空文字を返す
if s.len() == 0 {
return "".to_string();
}
// もし一文字ならその文字を返す
if s.len() == 1 {
return s[0].to_string();
}
// 回文で最長の長さを保持する変数
struct Result {
max_length: usize,
string: String,
}
let mut result = Result {
max_length: 0,
string: "".to_string(),
};
// もしかしてシャクトリ法じゃなくて組み合わせでは?
// 数字の組み合わせのタプルを取得
let collaboration_tuple = (0..s.len())
.flat_map(|i| (i..s.len()).map(move |j| (i, j)))
.collect::<Vec<(usize, usize)>>();
// println!("{:?}", collaboration_tuple);
// 回文かどうかを判定する関数
fn is_palindrome(s: &Vec<char>, i: usize, j: usize) -> bool {
let mut i = i;
let mut j = j;
while i < j {
if s[i] != s[j] {
return false;
}
i += 1;
j -= 1;
}
return true;
}
// この組み合わせに沿って、回文になっているかをすべて調べる
for (i, j) in collaboration_tuple {
// もし回文になっているなら、最長の長さを更新する
if is_palindrome(&s, i, j) {
let length = j - i + 1;
if length > result.max_length {
result.max_length = length;
result.string = s[i..=j].iter().collect();
}
}
}
return result.string;
}
}

Longest Palindromic Substringの解き方を改善してみる
コード
impl Solution {
pub fn longest_palindrome(s: String) -> String {
// まずは前処理を行う
// 先頭と末尾、文字の間に区切り文字 '#' を挿入する
// これにより奇数長と偶数長の回文を同様に扱えるようになる
let mut processed_string: Vec<char> = Vec::with_capacity(s.len() * 2 + 1);
// まずは先頭に '#' を挿入
processed_string.push('#');
// 文字列 's' の各文字の間に '#' を挿入
for c in s.chars() {
processed_string.push(c);
processed_string.push('#');
}
// 前処理後の文字列の長さ
let length = processed_string.len();
// 各文字位置での回文の半径を格納する配列
let mut palindrome_radii = vec![0; length];
// 現在の回文の右端
// この右端はループにしたがって更新されていく
let mut right = 0;
// 文章を一文字ずつ処理していく
for i in 0..length {
// 回文を左右に拡張していく処理
// 中心を 'i' とする
// 3つの条件
// 1. 現在のインデックス+回文の半径+1が文字列の長さを超えない(回文の右端が文字列の右端を超えない)
// 2. 現在のインデックスが回文の半径より大きい(回文の左端が文字列の左端を超えない)
// 3. 回文の左端と右端が等しい
// これらの条件を満たす限り、回文の半径を拡張していく
// nを半径とし、i+n+1文字目とi-n-1文字目が等しい場合、回文の半径をn+1に更新する繰り返し
while i + palindrome_radii[i] + 1 < length
&& i >= palindrome_radii[i] + 1
&& processed_string[i + palindrome_radii[i] + 1]
== processed_string[i - palindrome_radii[i] - 1]
{
palindrome_radii[i] += 1;
}
// 回文が右端を超えた場合、右端を更新
if i + palindrome_radii[i] > right {
right = i + palindrome_radii[i];
}
}
// 得られた最長回文長のベクタをもとに、該当する文字列を求める処理
// まず最大の回文長を持つ中心を求める
let max_center = palindrome_radii.iter().enumerate().fold(0, |max, (i, &x)| {
if x > palindrome_radii[max] {
i
} else {
max
}
});
// 長さも求める
let max_len = palindrome_radii[max_center];
// 回文の開始位置と終了位置を計算
// 中心については分かっているので
let start = max_center - max_len;
let end = max_center + max_len;
// 回文部分文字列を構築(区切り文字 '#' を除去)
let palindrome = processed_string[start..=end]
.iter()
.filter(|&&c| c != '#')
.collect();
// 最長回文部分文字列を返す
palindrome
}
}
最長の回文文字列問題というのは有名っぽい。このアルゴリズムとしてO(N)で解答できるのがManacher Algorithmらしい
今回は少しこれを簡易化した感じでプログラムしてみた。といっても、gptの力を借りたため、自分もまだ完全には理解できていない・・・

コード
impl Solution {
pub fn convert(s: String, num_rows: i32) -> String {
// もしnum_rowsが1以下の場合はそのまま返す
if num_rows <= 1 {
return s;
}
// modを行う数字について求める
let mod_number = (num_rows - 1) * 2;
// 与えられた文字列について
// enumerateを使ってインデックスを含んだタプルにしながらcharベクタに変換
let s_char_with_index = s.chars().enumerate().collect::<Vec<(usize, char)>>();
// 行数分のベクタを用意
let mut rows = vec![String::new(); num_rows as usize];
// 与えられた文字列についてループ
for (i, c) in s_char_with_index {
// mod_numberで割った余りを求める
let remainder = i % mod_number as usize;
// まずあまりが中央より小さい場合
if remainder < num_rows as usize {
// そのまま行に追加
rows[remainder].push(c);
} else {
// あまりが中央より大きい場合
// 中央からの差分を求める
let diff = remainder - num_rows as usize;
// 中央からの差分を引いた行に追加
rows[num_rows as usize - 2 - diff].push(c);
}
}
// 行数分の文字列を結合して返す
rows.join("")
}
}
- Zigzag Conversion
数列を思い出しながら法則を見出して実装していったらいけた

こうなってたほうが解放わかりやすいかも?

コード
impl Solution {
pub fn reverse(x: i32) -> i32 {
if x == 0 {
return 0;
}
if (x == -2147483648) {
return 0;
}
let is_negative = x < 0;
let mut tmp = x.abs();
let mut num_stack = Vec::new();
while tmp > 0 {
num_stack.push(tmp % 10);
tmp /= 10;
}
// i32からオーバーフローしていたら0を返す
if num_stack.len() > 10 {
return 0;
}
if num_stack.len() == 10 {
if num_stack[0] > 2 {
return 0;
}
if num_stack[0] == 2 && num_stack[1] > 1 {
return 0;
}
if num_stack[0] == 2 && num_stack[1] == 1 && num_stack[2] > 4 {
return 0;
}
if num_stack[0] == 2 && num_stack[1] == 1 && num_stack[2] == 4 && num_stack[3] > 7 {
return 0;
}
if num_stack[0] == 2
&& num_stack[1] == 1
&& num_stack[2] == 4
&& num_stack[3] == 7
&& num_stack[4] > 4
{
return 0;
}
if num_stack[0] == 2
&& num_stack[1] == 1
&& num_stack[2] == 4
&& num_stack[3] == 7
&& num_stack[4] == 4
&& num_stack[5] > 8
{
return 0;
}
if num_stack[0] == 2
&& num_stack[1] == 1
&& num_stack[2] == 4
&& num_stack[3] == 7
&& num_stack[4] == 4
&& num_stack[5] == 8
&& num_stack[6] > 3
{
return 0;
}
if num_stack[0] == 2
&& num_stack[1] == 1
&& num_stack[2] == 4
&& num_stack[3] == 7
&& num_stack[4] == 4
&& num_stack[5] == 8
&& num_stack[6] == 3
&& num_stack[7] > 6
{
return 0;
}
if num_stack[0] == 2
&& num_stack[1] == 1
&& num_stack[2] == 4
&& num_stack[3] == 7
&& num_stack[4] == 4
&& num_stack[5] == 8
&& num_stack[6] == 3
&& num_stack[7] == 6
&& num_stack[8] > 4
{
return 0;
}
if is_negative {
if num_stack[0] == 2
&& num_stack[1] == 1
&& num_stack[2] == 4
&& num_stack[3] == 7
&& num_stack[4] == 4
&& num_stack[5] == 8
&& num_stack[6] == 3
&& num_stack[7] == 6
&& num_stack[8] == 4
&& num_stack[9] > 8
{
return 0;
}
} else {
if num_stack[0] == 2
&& num_stack[1] == 1
&& num_stack[2] == 4
&& num_stack[3] == 7
&& num_stack[4] == 4
&& num_stack[5] == 8
&& num_stack[6] == 3
&& num_stack[7] == 6
&& num_stack[8] == 4
&& num_stack[9] > 7
{
return 0;
}
}
}
for i in 0..num_stack.len() {
let add_num = num_stack[i] * 10_i32.pow((num_stack.len() - i - 1) as u32);
tmp += add_num;
}
if is_negative {
tmp *= -1;
}
if tmp > i32::MAX || tmp < i32::MIN {
return 0;
}
return tmp;
}
}
- Reverse Integer
ふざけました・・・
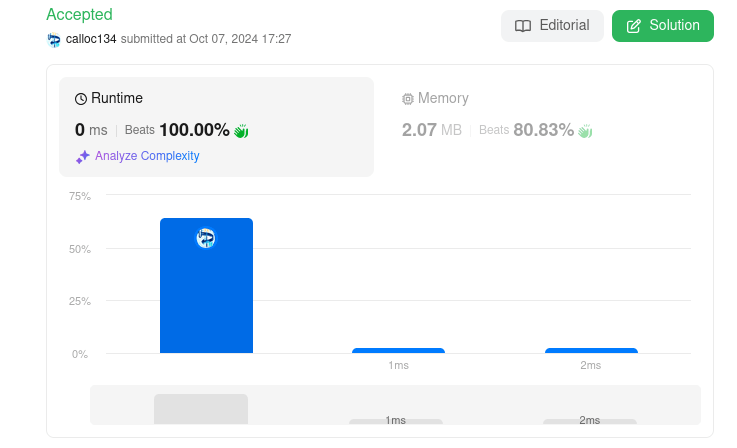
評価は良いらしいです
- String to integer
コード
impl Solution {
fn does_overflow(s_char: &Vec<i32>, is_negative: bool) -> bool {
if s_char.len() > 10 {
return true;
}
if s_char.len() < 10 {
return false;
}
let max = if is_negative {
vec![2, 1, 4, 7, 4, 8, 3, 6, 4, 8]
} else {
vec![2, 1, 4, 7, 4, 8, 3, 6, 4, 7]
};
for i in 0..s_char.len() {
if s_char[i] > max[i] {
return true;
} else if s_char[i] < max[i] {
return false;
}
}
return false;
}
pub fn my_atoi(s: String) -> i32 {
if s.len() == 0 {
return 0;
}
// 先頭と末尾の空白を削除
let mut s_char_without_space = s.trim().chars().collect::<Vec<char>>();
if s_char_without_space.len() == 0 {
return 0;
}
// マイナスになるかどうか
let is_negative: Option<bool> = match s_char_without_space[0] {
'+' => Some(false),
'-' => Some(true),
_ => None,
};
// 符号の場合は削除
if is_negative.is_some() {
s_char_without_space.remove(0);
}
// 数字の入るキュー
let mut result_queue: Vec<i32> = Vec::new();
// 文字の終わりを判定したいためwhileで
for i in 0..s_char_without_space.len() {
let result = s_char_without_space[i].to_digit(10);
if result.is_none() {
break;
}
if result.unwrap() != 0 || result_queue.len() != 0 {
result_queue.push(result.unwrap() as i32);
}
}
// オーバーフロー判定
if Solution::does_overflow(&result_queue, is_negative.unwrap_or(false)) {
return if is_negative.unwrap_or(false) {
i32::MIN
} else {
i32::MAX
};
}
// キューの内容を数値に復元
let mut result_num = 0;
for i in 0..result_queue.len() {
result_num = result_num * 10 + result_queue[i];
}
// フラグからマイナスをつけて返す
return result_num * if is_negative.unwrap_or(false) { -1 } else { 1 };
}
}
やるだけ
しかしテストケースで引っかかることが多かった
オーバーフロー判定部分は関数に切り出して使いやすくするのが良さそう
パフォーマンスはそれほど良くない

- Two Sum
放置していたので消化
コード
impl Solution {
pub fn two_sum(nums: Vec<i32>, target: i32) -> Vec<i32> {
// 二重ループを行う
// 組み合わせなので、内側のループは外側のループの次の要素から始める
for i in 0..nums.len() {
for j in i + 1..nums.len() {
if nums[i] + nums[j] == target {
return vec![i as i32, j as i32];
}
}
}
return vec![];
}
}
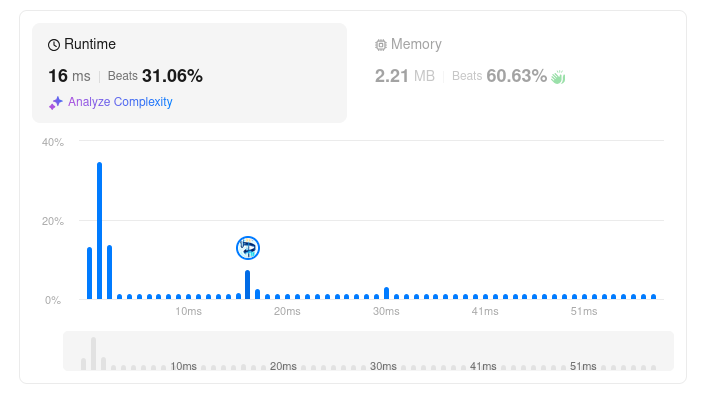
これでもちょっと遅かったのでハッシュマップを使う方法を調べる
コード
impl Solution {
pub fn two_sum(nums: Vec<i32>, target: i32) -> Vec<i32> {
// ハッシュマップを作成
// キー→数値、値→インデックス
let mut hash_map: std::collections::HashMap<i32, i32> = std::collections::HashMap::new();
for (i, num) in nums.iter().enumerate() {
// ターゲットから数値を引いた値がハッシュマップに存在するか
let diff = target - num;
if let Some(&index) = hash_map.get(&diff) {
return vec![index, i as i32];
}
// 存在しない場合はハッシュマップに数値とインデックスを追加
hash_map.insert(num.clone(), i as i32);
}
vec![]
}
}
ハッシュマップ
- キー: 数値(検索に必要なもの)
- 値: インデックス番号(戻り値で必要なもの)
これを用いて出てきた数値の保存と検索をO(N)で出来るようにしている

- Container With Most Water
普通に書いたもの
TLEが出た!
コード
impl Solution {
pub fn max_area(height: Vec<i32>) -> i32 {
let mut result = 0;
// 真面目に全ての組み合わせを試してみる?
for outside_index in 0..height.len() {
for inside_index in outside_index + 1..height.len() {
let h = if height[outside_index] < height[inside_index] {
height[outside_index]
} else {
height[inside_index]
};
let w = (inside_index - outside_index) as i32;
let area = h * w;
if area > result {
result = area;
}
}
}
return result;
}
}
シャクトリ法は使えなさそうだしな・・・
ただ、離れている部分から攻めていくやり方が好ましそう?
→| | |←
シャクトリではなく、両端から攻める的な
- Container With Most Water 続き
以下のような手順で実装
- 左端と右端のインデックスポインタを定義
- それぞれの端のバーの高さを求める
- 低い方が長方形の高さとなる
- インデックスの差から幅を求める
- 面積を求め、メモリより大きいなら代入
- 両端のバーの高さを比較して、低い側のインデックスを中心に向けて1進める
- 繰り返し
コード
impl Solution {
pub fn max_area(height: Vec<i32>) -> i32 {
let mut result = 0;
let mut left_pointer = 0;
let mut right_pointer = height.len() - 1;
while left_pointer < right_pointer {
let left_bar = height[left_pointer];
let right_bar = height[right_pointer];
let hight = if left_bar < right_bar {
left_bar
} else {
right_bar
};
let width = right_pointer - left_pointer;
let square = hight * width as i32;
if square > result {
result = square;
}
if left_bar < right_bar {
left_pointer += 1;
} else {
right_pointer -= 1;
}
}
return result;
}
}

でもなぜこれで上手くいくかわからないのでgptの手を借りる
- Integer to Roman
単に実装するだけっぽさ
コード
impl Solution {
pub fn int_to_roman(num: i32) -> String {
// 制約が1~3999なので4000以降は考えなくて良い
struct RomanSource {
thousand: usize,
hundred: usize,
ten: usize,
one: usize,
}
// まずは1000, 100, 10, 1の位を取得
let roman_source = RomanSource {
thousand: (num / 1000) as usize,
hundred: ((num % 1000) / 100) as usize,
ten: ((num % 100) / 10) as usize,
one: (num % 10) as usize,
};
// マッチ式で処理
fn roman_num(
num: usize,
alphabet_one: char,
alphabet_five: char,
alphabet_ten: char,
) -> String {
match num {
0 => "".to_string(),
1..=3 => alphabet_one.to_string().repeat(num),
4 => format!("{}{}", alphabet_one, alphabet_five),
5 => alphabet_five.to_string(),
6..=8 => format!(
"{}{}",
alphabet_five,
alphabet_one.to_string().repeat(num - 5)
),
9 => format!("{}{}", alphabet_one, alphabet_ten),
_ => "".to_string(),
}
}
// それぞれの位をローマ数字に変換
let thousand = roman_num(roman_source.thousand, 'M', ' ', ' ');
let hundred = roman_num(roman_source.hundred, 'C', 'D', 'M');
let ten = roman_num(roman_source.ten, 'X', 'L', 'C');
let one = roman_num(roman_source.one, 'I', 'V', 'X');
// 連結して返す
format!("{}{}{}{}", thousand, hundred, ten, one)
}
}

- Roman to Integer
これは全然書き方が思いつかなかったのでヒントを見たりした。不覚・・・
後ろからローマ字を見ていき(n文字目, n-1文字目, n-2文字目...)
n文字目よりn-1文字目の方が小さい場合は結果に減算、そうでなければ結果に加算をしていくと、値が求まるらしい
コード
use std::collections::HashMap;
impl Solution {
pub fn roman_to_int(s: String) -> i32 {
let s_char = s.chars().collect::<Vec<char>>();
// ローマ字の対応表のハッシュマップを作成
let roman_map: HashMap<char, i32> = [
('I', 1),
('V', 5),
('X', 10),
('L', 50),
('C', 100),
('D', 500),
('M', 1000),
]
.iter()
.cloned()
.collect();
let s_roman = s_char
.iter()
.map(|&c| roman_map.get(&c).unwrap())
.collect::<Vec<&i32>>();
let mut result = 0;
// 末尾から見ていく
for count in (0..s_roman.len()).rev() {
// もし最初でなく、現在の数字が次の数字より小さい場合は、引く
// if s_roman[count] < s_roman[count + 1] {
if count < s_roman.len() - 1 && s_roman[count] < s_roman[count + 1] {
result -= s_roman[count];
} else {
result += s_roman[count];
}
}
result
}
}
これで通るのか・・・
実装が思いつかなくて悔しい
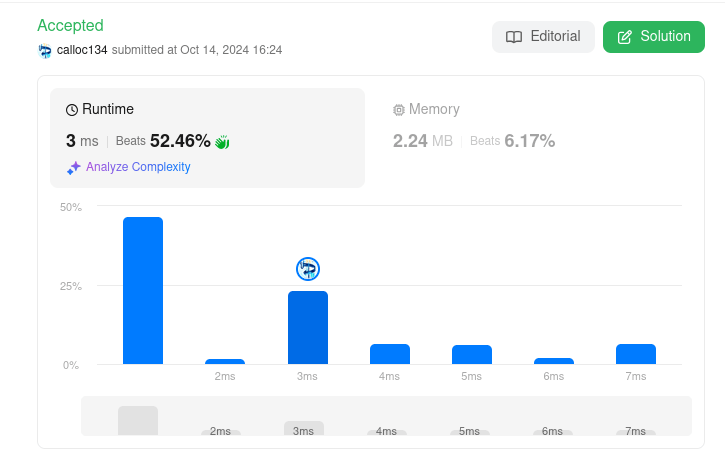
- First Unique Character in a String
二重ループで無理やりやるのは良くない、ハッシュマップを使おうという発想で実装
コード
impl Solution {
pub fn first_uniq_char(s: String) -> i32 {
// 出現したインデックスと回数を保存するためのハッシュマップ
// キー→記号、値→(インデックス, 回数)のタプル
let mut index_map = std::collections::HashMap::new();
for (i, c) in s.chars().enumerate() {
// キーが存在しない場合は、(i, 0)を挿入
if !index_map.contains_key(&c) {
index_map.insert(c, (i, 1));
}
// キーが存在する場合は、回数をインクリメント
else {
let (_, count) = index_map.get_mut(&c).unwrap();
*count += 1;
}
}
// 回数が1のものを洗い出して、最小のインデックスを返す
let mut min_index = s.len();
for (_, (i, count)) in index_map.iter() {
if *count == 1 && *i < min_index {
min_index = *i;
}
}
// 回数が1のものがない場合は-1を返す
if min_index == s.len() {
return -1;
}
min_index as i32
}
}
通ったっぽい

- Is Subsequence
単純に左からどんどんやっていくようにしたら通った・・・
しかも効率良いらしい
TLEになるかと思ったら普通に上手く行ってしまった
コード
impl Solution {
pub fn is_subsequence(s: String, t: String) -> bool {
let s_char = s.chars().collect::<Vec<char>>();
let t_char = t.chars().collect::<Vec<char>>();
// まず左と右のポインタを用意
// 左
let mut s_left_cursor = 0;
// let mut s_right_cursor = s.len() - 1;
let mut t_left_cursor = 0;
// let mut t_right_cursor = t.len() - 1;
if s_char.len() == 0 {
return true;
}
// それぞれの文字列の左から順に比較していく
while s_left_cursor < s_char.len() && t_left_cursor < t_char.len() {
if s_char[s_left_cursor] == t_char[t_left_cursor] {
s_left_cursor += 1;
}
t_left_cursor += 1;
}
if s_left_cursor == s_char.len() {
return true;
} else {
return false;
}
}
}
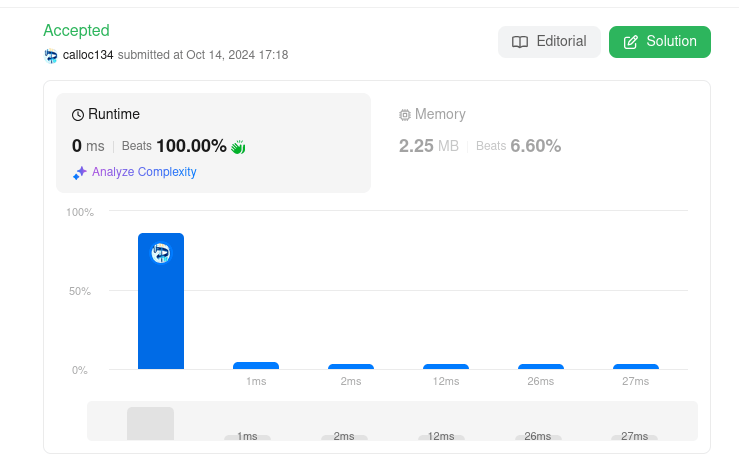
- Word Break
思いつきでコードを書いてみたけどもTLE
めちゃくちゃループしてるからしゃーないか・・・
コード
impl Solution {
pub fn word_break(s: String, word_dict: Vec<String>) -> bool {
// stack
let mut stack = vec![0];
// スタックがなくなるまで繰り返す
while stack.len() > 0 {
// 一つ取り出す
let index = stack.pop().unwrap();
// インデックス以後の文字列
let current_string = &s[index..];
for word in &word_dict {
// wordから開始するかどうか
if current_string.starts_with(word) {
// wordの長さ
let word_len = word.len();
// wordの長さがcurrent_stringの長さと同じ場合
if word_len == current_string.len() {
return true;
}
// スタックに追加
stack.push(index + word_len);
// break;
}
}
}
return false;
}
}
139 続き
かなり模範解答などを参考にした
部分文字列 = 単語だけで構成されていると保証される文字列 + 単語 とすることができる
- インデックスに対して「0~indexまでが単語だけで構成されているか」を格納するboolのリストを定義
- 1~(index+1)に対して以下の検証(ループ番号をIとする)
a. 0~Iが単語だけで構成されているかをチェック
b. boolのリストに格納
ここで、2aのチェック内容は以下の通り
- 右からインデックスを小さくしていく(Jとする)
- J~Iを切り出した文字列と単語が一致 && boolリストのJの箇所においてtrueなら 単語だけで構成されていると解釈→boolリストのIの箇所をtrueに設定
言語化難しい・・・
時間があったら図示する
ちなみに、"右からインデックスを小さくしていく"は左からやることも一応可能だけども、ちょっとパフォーマンスが劣化する
100%
コード
impl Solution {
pub fn word_break(s: String, word_dict: Vec<String>) -> bool {
let mut dp = vec![false; s.len() + 1];
dp[0] = true;
for i in 1..=s.len() {
for j in 0..i {
if dp[j] && word_dict.contains(&s[j..i].to_string()) {
dp[i] = true;
break;
}
}
}
dp[s.len()]
}
}

20 valid parentheses
とりあえず実装してみたけど、いきなり閉じ括弧が来たときに失敗する
コード
impl Solution {
pub fn is_valid(s: String) -> bool {
let bracket_hashset = std::collections::HashSet::from(['(', ')', '[', ']', '{', '}']);
let bracket_start_hashset = std::collections::HashSet::from(['(', '[', '{']);
let bracket_end_hashset = std::collections::HashSet::from([')', ']', '}']);
let bracket_pair_hashmap =
std::collections::HashMap::from([('(', ')'), ('[', ']'), ('{', '}')]);
let mut stack: Vec<char> = Vec::new();
let s_char = s.chars().collect::<Vec<char>>();
for char in s_char {
if !bracket_hashset.contains(&char) {
continue;
}
if bracket_end_hashset.contains(&char) {
if let Some(last) = stack.pop() {
if last != char {
return false;
}
}
}
if bracket_start_hashset.contains(&char) {
stack.push(*bracket_pair_hashmap.get(&char).unwrap());
}
}
return stack.is_empty();
}
}
popしたときにNoneの場合はfalseにするようにした
コード
impl Solution {
pub fn is_valid(s: String) -> bool {
let bracket_hashset = std::collections::HashSet::from(['(', ')', '[', ']', '{', '}']);
let bracket_start_hashset = std::collections::HashSet::from(['(', '[', '{']);
let bracket_end_hashset = std::collections::HashSet::from([')', ']', '}']);
let bracket_pair_hashmap =
std::collections::HashMap::from([('(', ')'), ('[', ']'), ('{', '}')]);
let mut stack: Vec<char> = Vec::new();
let s_char = s.chars().collect::<Vec<char>>();
for char in s_char {
if !bracket_hashset.contains(&char) {
continue;
}
if bracket_end_hashset.contains(&char) {
if let Some(last) = stack.pop() {
if last != char {
return false;
}
} else {
return false;
}
}
if bracket_start_hashset.contains(&char) {
stack.push(*bracket_pair_hashmap.get(&char).unwrap());
}
}
return stack.is_empty();
}
}

意外と効率が悪い・・・?