SQLに対するバックエンドのアプローチ比較、そしてSafeQLの紹介
はじめに
こんにちは。calloc134 です。
バックエンド開発において、DB にデータを保存することはよくあることです。
DB と接続してデータのやり取りを行う必要がありますが、皆さんはどのようにしてデータを取得していますか?
ORM やクエリビルダを利用したり、逆に SQL を記述してコード生成を行ったりと、様々な方法があります。
今回はこれらのアプローチについて比較し、比較的斬新な方針を取っているものとして SafeQL を紹介します。
注意点
ここでは、TypeScript のバックエンド開発と、そこで利用されるライブラリを前提として話を進めます。
Go や Python など他の言語での利用方法については、別途調査が必要です。
SQL に対するアプローチ
まず、SQL に対するアプローチには大きく分けて 2 つの方法があります。
それぞれのライブラリの使い方を、簡単に見ていきましょう。
なお、それぞれの例については簡易的なものとなっています。
参照したドキュメントについてリンクを掲載しているため、詳細はそちらを参照してください。
コード →SQL のアプローチ
アプリケーションコードを記述して SQL を組み立てる方法です。SQL を覆い隠すような形となります。ORM やクエリビルダがこれに該当します。
有名どころのライブラリを提示します。
- ORM: Prisma, Drizzle ORM
- クエリビルダ: Kysely
これらのライブラリは、提供されるメソッドを呼び出すことで、SQL の記述をライブラリが担ってくれるため、SQL を直接記述する必要がありません。
使い方のフローとしては以下のとおりです。
- スキーマファイルを記述する
- メソッドを呼び出してクエリを実行する
では、それぞれのライブラリについて使い方を解説していきます。
Prisma
Prisma では、独自のスキーマファイルを記述します。
model User {
id Int @id @default(autoincrement())
email String @unique
name String
}
...
なお、Prisma は DB にアクセスしてスキーマファイルを生成する introspect 機能も提供しています。
スキーマファイルを記述したら、以下のようにクエリを実行します。
const user = await prisma.user.findUnique({
where: {
email: "elsa@prisma.io",
},
});
Drizzle ORM
Drizzle ORM では、TypeScript のオブジェクトとしてスキーマを記述します。
import { integer, pgTable, serial, text } from "drizzle-orm/pg-core";
export const user = pgTable("user", {
id: serial("id").primaryKey(),
name: text("name"),
});
なお、Drizzle ORM も introspect 機能を提供しています。
スキーマを記述したら、以下のようにクエリを実行します。
クエリの方法としては、Prisma 風にクエリを記述する方法と、SQL 風にクエリを記述する方法があります。
const result = await db.query.users.findMany({
with: {
posts: true,
},
});
const result = await db.select().from(users);
Kysely
Kysely では、スキーマ生成について特に記述はありません。
kysely の場合は自分で型を記述する必要があります。こちらも、型を生成するアプローチがいくつか存在しています。
kysely-introspect というライブラリを利用することで、スキーマから型を生成することができます。
スキーマを記述したら、以下のようにクエリを実行します。
const persons = await db
.selectFrom("person")
.select("id")
.where("first_name", "=", "Arnold")
.execute();
SQL→ コード のアプローチ
SQL を記述し、これに対してコード生成を行い、型やメタデータを付与してコードに取り込む方法です。コード生成アプローチともいいます。
有名どころのライブラリを提示します。
- sqlc
- TypedSQL
これらのライブラリでは、記述された SQL ファイルを外部・DB のクエリパーサで解析し、TypeScript の型定義を生成します。
使い方のフローとしては以下のとおりです。
- SQL ファイルを記述する
- 設定ファイルを記述する
- コード生成を行い、型定義を生成する
- 生成された型定義を利用してクエリを実行する
では、それぞれのライブラリについて使い方を解説していきます。
sqlc
まず、以下のような SQL ファイルを記述します。
schema.sql というファイルに、スキーマ定義を記述します。
CREATE TABLE authors (
id BIGSERIAL PRIMARY KEY,
name text NOT NULL,
bio text
);
また、query.sql というファイルに、アプリケーション内で呼び出すクエリを記述します。
-- name: GetAuthor :one
SELECT * FROM authors
WHERE id = $1 LIMIT 1;
次に、以下のような sqlc.yaml ファイルに設定を記述します。
version: "2"
plugins:
- name: ts
wasm:
url: (sqlcのwasmのURL)
sha256: (対応するハッシュ値)
sql:
- engine: "postgresql"
queries: "query.sql"
schema: "schema.sql"
database:
managed: true
codegen:
- out: db
plugin: ts
options:
runtime: node
driver: pg
設定ファイルを記述したら、以下のコマンドを実行してコード生成を行います。
sqlc generate
生成されたクエリは、以下のように利用します。
import postgres from "postgres";
import {
getAuthor,
} from "./db/query_sql";
...
// Get that author
const seal = await getAuthor(sql, { id: author.id });
if (seal === null) {
throw new Error("seal not found");
}
console.log(seal);
TypedSQL
TypedSQL は、Prisma と連携して提供されるライブラリです。
スキーマは Prisma のスキーマを利用するため、クエリのみを記述します。
SELECT u.id, u.name, COUNT(p.id) as "postCount"
FROM "User" u
LEFT JOIN "Post" p ON u.id = p."authorId"
GROUP BY u.id, u.name
この SQL ファイルはprisma/sql/ディレクトリに配置します。
次に、設定ファイルを記述します。
TypedSQL の場合、ORM で紹介した Prisma と連携して提供されるため、Prisma に設定を記述します。
generator client {
provider = "prisma-client-js"
previewFeatures = ["typedSql"]
}
設定ファイルを記述したら、以下のコマンドを実行してコード生成を行います。
prisma generate --sql
生成されたクエリは、以下のように利用します。
import { PrismaClient } from "@prisma/client";
import { getUsersWithPosts } from "@prisma/client/sql";
const prisma = new PrismaClient();
const usersWithPostCounts = await prisma.$queryRawTyped(getUsersWithPosts());
console.log(usersWithPostCounts);
アプローチの比較
それぞれのアプローチには、メリットとデメリットがあります。
隠蔽は隠蔽でかゆいところに手が届かない
生成される SQL をグッと睨みながら ORM なりのご機嫌をうかがわないとならなかったりするので、生成するのが最右翼なら、逆サイドの左翼に「手で書いた SQL を解析してコードの方に合わさせる (sqlc とか)」のが来つつある
それぞれのアプローチには、メリットとデメリットがあります。
コード →SQL のアプローチ
特徴
- 提供されるメソッドで SQL を記述する
- コード内部にクエリしたい内容が表現される
メリット
- クエリしてくるデータをコード内部で表現できる
- メソッドで隠蔽されているため、型安全性やエラーチェックが行いやすい
デメリット
- SQL の記述をそのまま行えないため、発行されるクエリを確認するための手間がかかる
- ORM・クエリビルダの使い方自体を覚える必要があり、別言語・別環境への移行コストが高く、コードの使いまわしが難しい
SQL→ コード のアプローチ
特徴
- SQL ファイルを記述してコード生成する
- コード外部の SQL ファイルにクエリが記述される
メリット
- SQL をそのまま記述できるため、複雑なクエリも記述しやすい
- 呼び出されるクエリを確認するための手間がかからない
- 本番環境にライブラリが入りこまないことが多い
- SQL ファイルを利用するため、既存の SQL をそのまま利用できる
また余談ですが、ORM を記述している頃は生の SQL が書けないという後ろめたさがありました。このような感情への対処法として、SQL をそのまま記述する方法は有用であると考えられます。
デメリット
- コード生成や import の手間がかかる
- sql 記述時にはエラーが発生しないため、別の手段でエラーチェックを行う必要がある
- sql ファイルが分離されるため、命名が面倒
SafeQL とは
では、ここで SafeQL の紹介を行います。
SafeQL は、コード内部で SQL を記述し、これに対して型を付けることができるライブラリです。
分類的には、SQL→ コード のアプローチに近いと言えます。
しかし、ORM のような使い勝手を提供することができるため、コード →SQL の良さを持ち合わせていると言えます。
なお、対応している DB は PostgreSQL のみです。
また、SafeQL は eslint ルールとして実装されるため、eslint の導入が必須となっています。SQL の解析は実際に DB にアクセスして行っているため、テスト用の DB が必要です。
使ってみる
SafeQL は単に SQL クエリに型が付くだけなので、マイグレーション周りは別途のライブラリを利用する必要があります。
ここは、SQL ファイルを記述してコード生成する方法と同じです。
今回はマイグレーションの手間を省くため、そのまま SQL を実行します。
ローカルで Postgres を起動します。なお、接続 URL はpostgresql://localhost:5432/postgresです。
psql -h localhost -p 5432 -U postgres
CREATE DATABASE "safeql-test";
\c safeql-test
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL
);
ここから解説する内容は以下のリポジトリに記述されています。
次に、SafeQL をインストールします。今回は pnpm を利用しています。
pnpm install -D @ts-safeql/eslint-plugin libpg-query
次に、eslint.config.mjsを以下のように記述します。
import safeql from "@ts-safeql/eslint-plugin/config";
import tseslint from "typescript-eslint";
export default tseslint.config(
...tseslint.configs.recommended,
safeql.configs.connections({
databaseUrl:
"postgresql://postgres@localhost:5432/safeql-test?sslmode=disable", // 接続先の URL
targets: [{ tag: "sql", transform: "{type}[]" }],
})
);
最後に、src/index.tsに以下のように記述します。
import postgres from "postgres";
const main = async () => {
const sql = postgres(
"postgresql://postgres@localhost:5432/safeql-test?sslmode=disable"
);
const result = await sql`SELECT id, name FROM users WHERE id = ${1}`;
console.log(result);
};
main();
ここまで記述すると、SafeQL によって以下のように型の提案が行われます。

では、Fix this @ts-safeql/check-sql problemを選択します。
すると、自動的にジェネリクスに対して型が付与されます。
import postgres from "postgres";
const main = async () => {
const sql = postgres(
"postgresql://postgres@localhost:5432/safeql-test?sslmode=disable"
);
const result = await sql<
{ id: number; name: string }[]
>`SELECT id, name FROM users WHERE id = ${1}`;
console.log(result);
};
main();
色々なクエリを試してみる
色々なクエリを試してみます。
基本的なクエリ
select * を試してみると、すべてのカラムのフィールドが提案されます。

存在しないカラムを指定すると、エラーが発生します。

型とキャストについて
TypeScript における number 型に対して、PostgreSQL の integer 型が対応します。
また、TypeScript における string 型に対して、PostgreSQL の text 型が対応します。

PostgreSQL においては uuid 型が存在しますが、TypeScript には存在しないため、where 句で uuid 型の指定を string 型で行うとエラーが発生します。
試してみましょう。
CREATE TABLE users2 (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name TEXT NOT NULL
);
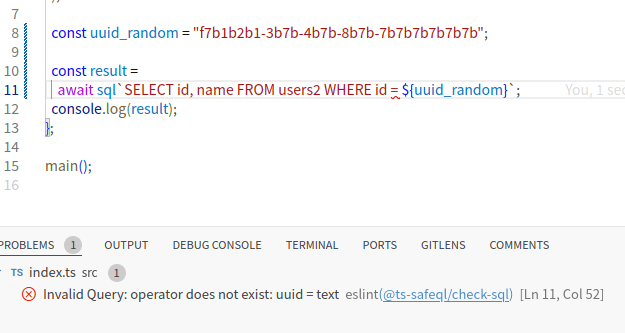
では、::uuidを指定してキャストしてみます。

エラーが発生しなくなりました。
また、レスポンスについてもキャストが可能です。
この場合は、キャストされた型が提案されます。

INSERT/UPDATE/DELETE
INSERT/UPDATE/DELETE についても型が提案されます。
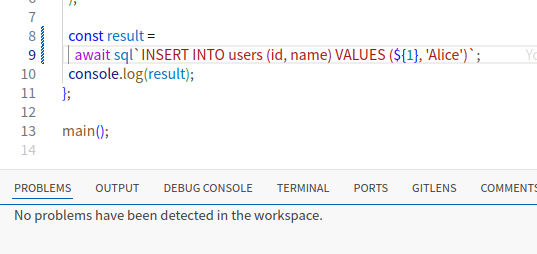

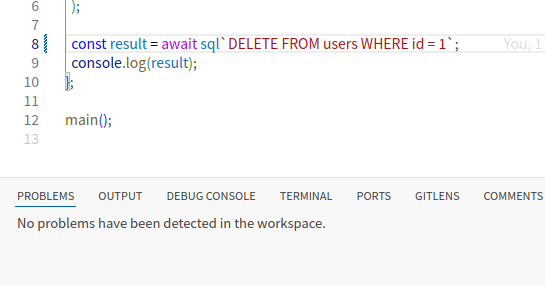
PostgreSQL においては、RETURNING 句を利用することで、更新後のレコードを取得することができます。


JOIN
JOIN についても試してみます。
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
user_id INTEGER REFERENCES users(id),
title TEXT NOT NULL
);
以下のクエリを記述します。
SELECT users.id AS user_id, users.name, posts.id AS post_id, posts.title FROM users JOIN posts ON users.id = posts.user_id;

しっかりと型が提案されました。
次に、LEFT JOIN を試してみます。
SELECT users.id AS user_id, users.name, posts.id AS post_id, posts.title FROM users LEFT JOIN posts ON users.id = posts.user_id;

LEFT JOIN の場合は、post_id と title に null が許容されることが提案されました。
このように、JOIN についてもしっかりと型が提案されます。
注意点
まだ少し不安定な部分があり、型に null が含まれて出力されることがあります。
この場合、VSCode を再起動することで正確な型が生成されるようになる場合が多いです。
テーブルのスキーマ定義を変更した後は、VSCode を再起動することをおすすめします。
考えられる SafeQL の良さ
筆者が考える SafeQL の良さは以下のとおりです。
- 型安全性が担保される
- コード内部にクエリを記述でき、コロケーションを保つことができる
- コード生成・import の手間がかからない
- 本番環境に入りこまない
- SQL をそのまま記述でき、見通しが良い
ここで、前半 3 つについては コード →SQL のアプローチのメリット、後半 2 つについては SQL→ コードのアプローチのメリットに近いと考えられます。
では、解説していきます。
型安全性が担保される
SafeQL は、SQL を記述する際に型を付けることができます。
これにより、実行時エラーを減らすことができ、安全に SQL を記述することができます。
コード内部にクエリを記述でき、コロケーションを保つことができる
コード生成アプローチを利用する場合、SQL ファイルを分離することが多いです。
この考え方について、前述の通り賛否両論が存在します。
しかし、筆者の考えでは、コロケーションの考えを重視することが重要であると考えます。
コロケーションとは、フロントエンドの開発でよく用いられる概念であり、以下の原則で説明されます。
Place code as close to where it's relevant as possible.(コードをできるだけ関連する場所に配置しなさい。)
この原則は、バックエンドの開発においても有効であると考えられます。
クエリというものはアプリケーションのロジックと密結合であり、コード内部に記述することで、コードの可読性が向上すると考えます。
SafeQL を利用することで、コード内部にクエリを記述できるというのは、メリットであると思います。
コード生成・import の手間がかからない
コード生成アプローチを利用する場合、コマンドの実行の手間がかかります。また、生成されたコードを import する必要があります。
SafeQL ではコード内に SQL を記述するため、コード生成の手間がかかりません。
本番環境に入りこまない
SafeQL は、単なる eslint ルールとして実装されています。
Postgres.js を利用する際にジェネリクス内に型を提案するだけなので、本番環境に余計なライブラリが入りこまないというメリットがあります。
本番環境にライブラリが入りこまないというのは、セキュリティやパフォーマンスの観点からも望ましいです。
参考に、Postgres.js を利用した場合の依存関係は以下の通りです。
...
"devDependencies": {
"@ts-safeql/eslint-plugin": "^3.4.1",
"libpg-query": "15.2.0-rc.deparse.3",
"tsx": "^4.19.0",
"typescript-eslint": "^8.3.0"
},
"dependencies": {
"postgres": "^3.4.4",
"typescript": "^5.5.4"
}
...
なお、特性としてマイグレーション周りは別途のライブラリを利用する形となります。
筆者の環境では dbmate を利用しています。
SQL をそのまま記述でき、見通しが良い
sql タグとして記述された SQL は、そのまま実行されます。
したがって、ORM などのライブラリで提供されるメソッドを覚える必要がありません。
また、ORM を利用する際は発行されるクエリを確認するための手間がかかりますが、SafeQL ではそのような手間がかかりません。実行計画の確認なども容易です。
これはコード生成アプローチの場合と同様のメリットであると考えられます。
まとめ
バックエンド開発において、DB へのクエリは必須です。
クエリの方法については様々なアプローチがあり、年々新しい技術が登場し、実装も豊かになってきています。
今回はこれらのアプローチを比較し、面白いと思われるアプローチの一つである SafeQL を紹介しました。
この機会に是非知っていただけたら嬉しいです。
最後まで読んでいただきありがとうございました。
Discussion