DP室の @uncle__ko です
日々進化する開発環境において、必要な情報へ迅速にアクセスできることは生産性向上に不可欠です。特に、大規模なプロジェクトや複数のツールを扱う際には、公式ドキュメントの参照が頻繁に発生します。
この度、PipeCDとBucketeerにおいて、それぞれローカル環境で動作するMCP (Model Context Protocol) Document Serverを構築しました。これにより、各ツールのドキュメントをローカル環境で簡単に検索・参照できるようになり、開発効率の向上が期待できます。
本記事では、それぞれの取り組みについてご紹介します。
MCP (Model Context Protocol) Document Serverとは?
まず、「MCP Document Server」とは何かについてご説明します。
MCP (Model Context Protocol) は、AIアシスタントや大規模言語モデル(LLM)が、外部の知識やツールを効率的に利用するための標準化されたオープンプロトコルです。AIアプリケーションのための「共通言語」や「USB-Cポート」と表現されることが多いように、さまざまなデータソース(ファイルシステム、データベース、APIなど)とAIモデルをシームレスに接続します。
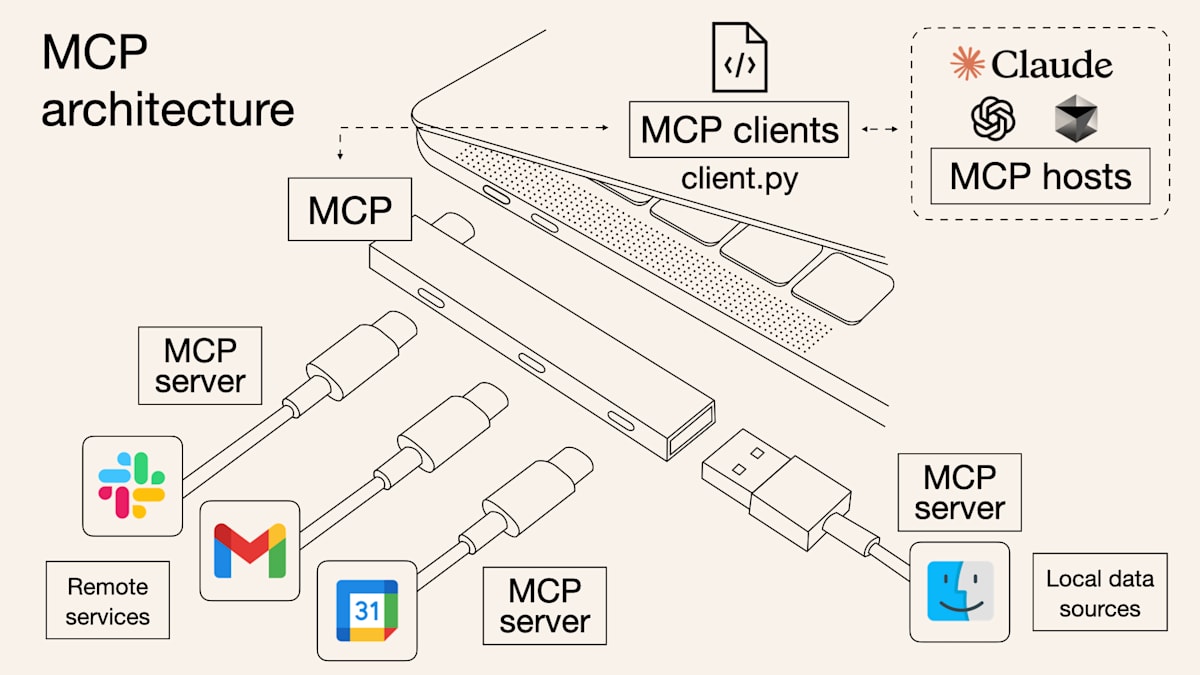
※ 引用: https://norahsakal.com/blog/mcp-vs-api-model-context-protocol-explained/
MCPを利用することで、AIアシスタントは以下のようなことが可能になります。
- 必要な情報への直接アクセス:
- ドキュメントサーバー内の情報を参照し、ユーザーの質問に対してより正確で最新の情報に基づいた回答を生成する。
- 外部ツールの実行:
- 特定のタスクを実行するための外部アプリケーションやサービスを呼び出す。
つまり、MCP Document Serverとは、このMCPプロトコルに対応したドキュメントサーバーのことです。ドキュメントをMCP経由で提供することで、AIアシスタントがその内容を理解し、活用できるようになります。これにより、開発者は自然言語でAIに質問するだけで、ドキュメント内の情報を引き出したり、関連情報を効率的に収集したりすることが可能になります。
なぜローカル環境なのか? Remote vs. Local
ドキュメントサーバーを構築する際、リモートサーバー(クラウド上など)に置くか、ローカル環境(開発者の手元マシン)に置くかという選択肢があります。今回、私たちがPipeCDとBucketeerで採用したのはローカル環境での構築です。その主な理由は以下の通りです。
| 特性 | ローカルサーバー | リモートサーバー (クラウドなど) |
|---|---|---|
| アクセス速度 | ◎ 高速(ネットワーク遅延なし) | △〜○ ネットワーク環境に依存 |
| オフライン | ◎ 利用可能 | × 利用不可 |
| セキュリティ | ○ 機密情報を内部に留めやすい | △ 設定や環境次第 |
| リソース | △ ローカルマシンのリソースを消費 | ◎ サーバーリソースを利用 |
| 導入・運用 | ○〜△ 個別セットアップ、ドキュメント同期が必要 | ◎ 一元管理のメリット、セットアップの容易さ |
| AI連携 | ◎ AIアシスタントがローカル情報に直接アクセス可能 | △ AIがアクセスするための追加設定やセキュリティ考慮が必要 |
私たちのユースケースでは、特に以下の点がローカル環境のメリットとして際立ちました。
- 即応性と開発効率の向上:
- 開発者が日々参照するドキュメントへのアクセスが高速であることは非常に重要です。ローカルサーバーであれば、ネットワークの状況に左右されず、瞬時に情報へアクセスできます。
- AIアシスタントとの親和性:
- CursorやClaude Desktopのようなローカルで動作するAIアシスタントと連携する場合、ドキュメントもローカルにある方がシームレスかつセキュアに連携できます。
もちろん、ドキュメントの一元管理や大規模なチームでの共有といった点ではリモートサーバーに分があります。
しかし、PipeCD、BucketeerはOSSという特性があるため、無理にリモートにしなくても良いという判断となりました。
構築するうえで工夫した点
PipeCDとBucketeer、それぞれのMCP Document Server構築にあたり、工夫した点がいくつかあるので共有していきます。
ドキュメントの取得と最新のDocumentを参照させる:
- ドキュメント同期
- ドキュメントが更新されたかどうかをチェックするために、SHAベースの変更検出を取り入れています。これにより、本当に変更があったファイルだけを更新対象とし、無駄な処理を減らしています。さらに、キャッシング戦略も併用することで、同期の効率をより高めてます。
- GitHub APIレートリミットへの配慮
- 大量のドキュメントを一度に取得しようとすると、GitHub APIの利用制限(レートリミット)に引っかかってしまうことがあります。これを避けるために、以下のような対策を講じています。
- スマートバッチ処理: リクエストを小さなグループにまとめ、各グループの処理の間に適切な遅延を入れることで、APIへの負荷を分散。
- 指数関数的バックオフ: もしリクエストが失敗してしまっても、すぐに再試行するのではなく、少しずつ間隔を空けながら再試行するようにしてます。
- 大量のドキュメントを一度に取得しようとすると、GitHub APIの利用制限(レートリミット)に引っかかってしまうことがあります。これを避けるために、以下のような対策を講じています。
検索性の向上:
- Bucketeerにおいては、固有の用語を優先し、重み付けスコアリングを使用する多層検索アルゴリズムを実装。下記のようにスコアリングしています
- タイトルの完全一致キーワード(3x weight): 検索語がタイトルに含まれる文書を優先する。通常、これらの文書は最も関連性が高いため。
- コンテンツ内のキーワード一致(1x weight):包括的なカバレッジのためにドキュメントコンテンツ内で見つかった一致を含める
- 全文検索: キーワードマッチングで十分な結果が得られない場合に全文検索にフォールバックし、ユーザーが常に役立つ回答を得られるようにしてる
補足:MCP Inspector
MCPサーバーの開発をしていると、サーバーとクライアント間の通信内容を詳細に把握したくなってきます。この目的のために、MCP Inspector というツールが提供されており、私たちの開発作業においてもとても助けになってくれました。

- 公式ドキュメント
- GitHubリポジトリ
MCP Inspectorは、MCPサーバーとクライアント(例:AIアシスタント)間で送受信されるメッセージをリアルタイムで監視し、その内容を可視化するツールです。主な機能として、以下の点が挙げられます。
- リクエストおよびレスポンスの検証
- AIアシスタントからMCPサーバーへ送信されるリクエスト(search_docs、read_docsなどのコマンド)と、それに対するサーバーからのレスポンス(JSON形式データ)を詳細に確認。
- プロトコル準拠性の確認
- 開発中のMCPサーバーが、Model Context Protocolの仕様に準拠して適切に応答しているか、期待されるデータ構造で情報を返却しているかを検証。
- 問題発生時の原因切り分け
- AIアシスタントがドキュメントを正常に処理できない等の問題が発生した際、MCP Inspectorを通じて通信シーケンスとデータ内容を分析することで、問題がサーバー側に起因するのか、クライアント側の設定や実装に起因するのか、あるいはその両方か、といった原因究明。
具体的には、PipeCDおよびBucketeerのローカルMCPサーバー開発過程において、MCP Inspectorを用いることで、AIクライアントからの検索クエリの内容や、サーバーが返却するドキュメントチャンクの形式などを明確に把握できました。これにより、実装の妥当性確認や不具合修正の効率が大幅に向上しました。
MCPサーバーの開発に取り組む、あるいは既存サーバーの挙動を詳細に理解する必要がある技術者にとって、MCP Inspectorはデバッグおよび検証作業を支援する強力なツールとなりそうです。
それぞれのMCP Document Serverの使い方
ではそれぞれのMCP Document Serverの使い方を紹介していきます。
PipeCD

特徴
PipeCDのGitHubリポジトリからドキュメントを自動で取得・同期。
MCPプロトコルに対応し、search_docs (全文検索) と read_docs (ページ内容取得) のAPIを提供。
CursorなどのAIアシスタントと連携可能。
Install
npx @pipe-cd/docs-mcp-server@latest
Configure your AI Assistant
{
"mcpServers": {
"pipe-cd.docs-mcp-server": {
"type": "stdio",
"command": "npx",
"args": [
"@pipe-cd/docs-mcp-server@latest"
]
}
}
}
Start Using
サーバーは、AI アシスタントを通じて PipeCD のドキュメントに即座にアクセスできるようになります。

関連リンク
- PipeCDブログ記事
- リポジトリ
Bucketeer

特徴
Bucketeerのドキュメントリポジトリからドキュメントを取得し、ローカルにインデックスを構築。
AIアシスタント (Claude, Cursorなど) がドキュメント内容を直接参照可能に。
ドキュメントの鮮度を保つためのインデックス更新機能。
Install
npx @bucketeer/docs-local-mcp-server build-index
Configure your AI Assistant
{
"mcpServers": {
"bucketeer-docs": {
"type": "stdio",
"command": "npx",
"args": ["@bucketeer/docs-local-mcp-server"]
}
}
}
Start Using
サーバーは、AI アシスタントを通じて Bucketeer のドキュメントに即座にアクセスできるようになります。

関連リンク
- Bucketeerブログ記事
- リポジトリ
今後の展望
PipeCDとBucketeerにおけるローカルMCP Document Serverの導入は、単にドキュメント検索が速くなるというだけでなく、開発者体験 (DX) を向上させ、より本質的な業務に集中できる環境づくりへの一歩です。
これにより、以下のような効果が期待できると考えてます。
- 学習コストの削減とオンボーディングの迅速化
- 問題解決のスピードアップ
- AIによる開発支援の質の向上
しかし、MCPサーバーが提供する「AIが理解できる形で情報にアクセスできる経路」というのは、実はもっと大きな可能性を秘めていると考えています。現状は主にドキュメントの参照や検索といった「情報取得」が中心ですが、将来的にはAIエージェントがより能動的に開発ワークフローに関与してくる世界があるかもしれません。
たとえば、開発者がAIアシスタントに対して、「PipeCDを使って、サービスAの最新バージョンをステージング環境にデプロイして」と指示するだけで、AIエージェントがMCPサーバーを通じてPipeCDの状態を理解し、適切なデプロイコマンドを組み立て、実行してくれるようになるかもしれません。デプロイ状況の確認や、問題発生時のロールバック指示なども、自然言語で行えるようになるかもしれないです。
同様にBucketeerでも、AIアシスタントに「新しいフィーチャーフラグ『X機能』を有効にして、まずは社内ユーザーだけに公開して。その後、A/Bテストとして一般ユーザーの10%にも展開して、効果測定を開始して」といった複雑な操作を依頼できるようになる可能性があります。AIエージェントがMCPサーバーから現在のフラグ設定やセグメント情報を取得し、的確にBucketeerを操作してくれるようになれば、フィーチャーフラグの運用やA/Bテストの実施が、より迅速かつ柔軟に行えるようになるでしょう。
もちろん、これらはまだぱっと思いついたアイデアですが、MCPというプロトコルとAI技術の組み合わせによって、私達の開発スタイルが変化していくことは充分に考えられます。今後も、このような新しい技術の可能性を追求し、開発者体験を向上していくための取り組みを進めていきたいと考えています。
おわりに
今回は、PipeCDとBucketeerにおけるローカルMCP Document Serverの構築について、その技術的な背景から具体的な利用方法までをご紹介しました。
この取り組みが、皆様のプロジェクトにおけるドキュメント活用の新たなヒントとなり、日々の開発業務の効率化に少しでも貢献できれば幸いです。ローカルMCP Document Serverという新しいアプローチで、ドキュメントとの付き合い方を見直してみませんか?
ご質問や、「うちではこんな工夫をしているよ!」といった情報共有など、ぜひお気軽にお寄せくださ

Discussion