はじめに
最近のプロジェクトで GraphQL を積極的に採用しており、その設計思想として Fragment Colocation を取り入れています。
今回はFragment Colocationを取り入れた際のクライアントキャッシュ戦略についてまとめたので、その戦略について紹介したいと思います!
キャッシュ戦略については、Fragment Colocation を使っていなくても十分適用できると思うので、GraphQL を採用している方はぜひ参考にしてもらえればと思います!
今回の内容に関してスライドも公開しているので、そちらも興味のある方はご覧ください!
Fragment Colocation とは
Fragment Colocation とは、コンポーネントで使用するデータをFragmentとして定義し、コンポーネントとセットで管理するという考え方です。
各コンポーネントで使用したいデータを Fragment で定義して、親コンポーネントで子コンポーネントの Fragment をまとめあげた Query を定義します。あくまで、子コンポーネントで行っているのは Fragment によるデータの宣言のみで、実際にそれらのデータの取得の責務は親コンポーネントが担います。
これにより、責務が分離され、子コンポーネントは再利用が可能になります。ただし、複数のコンポーネントから利用する際は、子コンポーネントの Fragment をそれぞれの呼び出し元のコンポーネントの Query に含める必要があります。
また、個人的にかなり気に入っている点が、コンポーネントの修正の影響範囲が閉じることです。
子コンポーネントで表示データの変更がある場合に、そのコンポーネントと Fragment の修正のみで完結します。他のコンポーネントや呼び出し元のコンポーネントでさえも修正が必要ありません。修正に伴う影響範囲がそのコンポーネント内に閉じられるため、修正に必要な差分が少なくて済み、何より修正の際の心理的安全性が高いことから、かなり恩恵を感じています。
下記のスライドでユーザー画面における例を紹介しているので、そちらを見ていただければイメージしやすいと思います。
クライアントサイドキャッシュ戦略
自分は普段 Apollo Client を使っているのですが、Apollo Client にはキャッシュ機構が備わっています。これは Relay や urql などのライブラリも同様です。
これらのキャッシュ機構を最大限活用するために、大きく分けて2つの方針を決めました。その中で Fragment Colocation を採用しているが故に悩んだ部分もあるので、その辺りも交えて説明していきます。
ページ単位でのキャッシュの最適化
基本的にキャッシュはページ単位での最適化を考えます。
Fragment Colocation の考え方的に、子コンポーネントの Fragment を親コンポーネントの Query でまとめあげるので、自然とページ単位で Query が定義されるようになります。そのため、基本的に Query を複数のページで使い回すことはなく、そのページ内の Query をどのようにキャッシュするかを考えればよくなります。
また、ページを跨いだキャッシュの利用は考慮するべき点が多いことも挙げられます。
Apollo Client などクライアントライブラリの仕様として、取得しようとしているデータの内、一部のフィールドでもキャッシュにデータがない場合はネットワークリクエストを行います。
参考:Apollo Clientのキャッシュの仕組みとローカルの状態管理について
この仕様の元、アプリケーション全体にキャッシュを適用し、データの最初のリクエスト以外はキャッシュを利用する場合を考えます。各ページで利用するフィールドは異なるため、各ページで必要なフィールドの和集合となる Query を定義して、その Query をアプリケーション全体で使い回す必要があります。
これであれば、ページを跨いだキャッシュの利用は実現できますが、ページによっては必要ないフィールドまで取得しているので明らかにオーバーフェッチです。また、1つの Query をアプリケーション全体で使い回しているので、Query の変更に対する影響範囲が広くなってしまいます。
これらを踏まえた上で、キャッシュをアプリケーション全体で利用できるメリットよりも、デメリットの方が大きいと判断して、ページ単位での最適化を考えることにしました。
ただ、データによってはアプリケーション全体で利用したい場面も当然あるので、その場合は例外的に対応するようにしています。(データの分類の部分で詳しく説明します)
データを3種類に分類する
次にデータの分類について説明していきます。
キャッシュは通常、Query ごとに保存されるため、キャッシュしたいデータを分類し、それぞれに対応する Query を定義します
データの使用目的や、キャッシュの扱い方を考慮して、データを次の3種類に分類しました。
コンテンツデータ
コンテンツ表示用のデータです。検索結果一覧や詳細情報などが該当します。
ユーザーのアクションによってデータが動的に変わります。ユーザーのアクションに応じて Query 実行されますが、variables が同じ Query の場合はキャッシュを利用することが可能です。
ページに対応するコンポーネントとセットで Query を定義します。
マスタデータ
マスタデータやメタデータなどのシステム的に必要なデータです。検索条件の選択肢や地域コードなどが該当します。
コンテンツデータとは異なり、ユーザーのアクションによってデータが動的に変化しません。そのため、初回のみリクエストが必要で、その後はユーザーのアクションによらずキャッシュを利用することができます。
こちらも、ページに対応するコンポーネントとセットで Query を定義します。
汎用マスタデータ
マスタデータの中でも、データ量が大きいかつアプリケーション全体で頻繁に使用されるデータです。従業員情報や商品カテゴリなどが該当します。
キャッシュはページ単位で考えると先述しました。コンテンツデータとマスタデータもその方針に従い、ページ単位で Query を定義します。しかし、マスタデータの中にはデータ量が大きく、複数のページで重複してリクエストされるものも存在します。そのようなデータが多数のページでリクエストされるとパフォーマンスにも影響が出てくるため、そのようなデータは例外的に汎用マスタデータに分類します。そして、コンポーネントとは別で汎用マスタデータごとに Query を定義して、アプリケーション全体でキャッシュを利用するようにします。
具体的な実装方針は下記になります。
- 各コンポーネントで汎用マスタデータ用の Fragment を定義
- それらの Fragment をまとめる Query をコンポーネントの外で定義
- 各コンポーネントでその Query を呼び出して利用
こうすることで、アプリケーション全体で同じ Qeury を使用する場合でも、Fragment Colocation を適用させることができ、コンポーネントの修正の影響範囲を閉じることができます。ただし、特定のデータの Fragment を全て含んだ Query を実行することになるので、オーバーフェッチになってしまうというデメリットは残っています。このデメリットは今の所は許容するしかないかなと考えています。
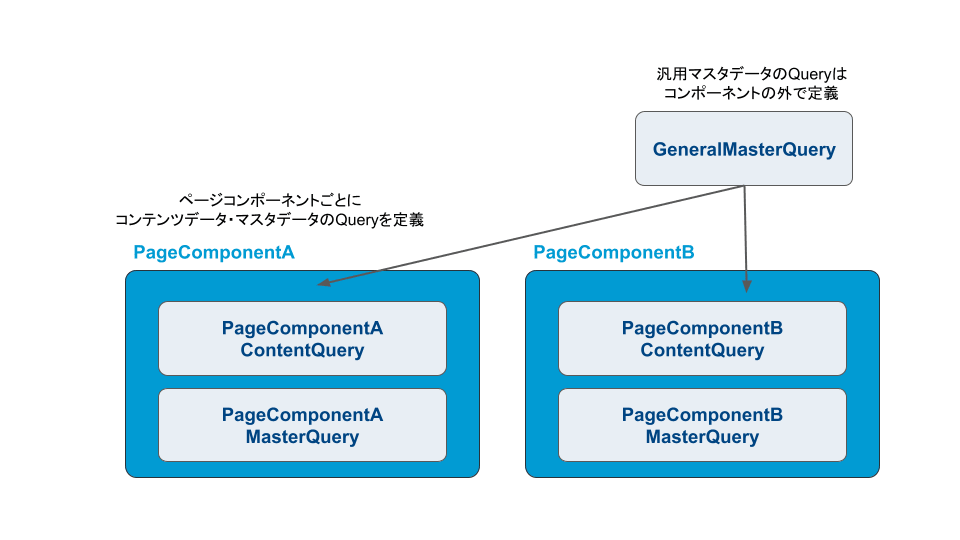
全体像
ここまで説明した内容を図で表すと下記のようになります。
ページコンポーネントでコンテンツデータ・マスタデータそれぞれの Query を定義し、必要に応じてコンポーネントの外で定義された汎用マスタデータの Query を呼び出します。(必ずしも全てのコンポーネントでコンテンツデータ・マスタデータの両方が存在するとは限りません)
実装例
下記のようなページを例に実装例を紹介します。(Query, Fragment の定義にフォーカスしているので、それ以外の箇所は省略しています)

コンポーネントのディレクトリ構成は下記のようになります。
src
├── components
│ ├── TaskList.tsx
│ └── TaskSearch.tsx
├── hooks
│ └── useUsers
│ └── index.ts
└── pages
└── index.tsx
タスクの検索フォームをTaskSearch、タスクの一覧をTaskListとしてコンポーネントを定義し、それらをまとめるページコンポーネントをpages/index.tsxに定義します。また、汎用マスタデータ用の hook をhooks/useUsersに定義します。
TaskSearch
TaskSearchでは、マスタデータと汎用マスタデータとして、検索フォームの選択肢のための Fragment を定義します。
// マスタデータ用のFragment
const TaskSearchMasterFragment = graphql(/* GraphQL */ `
fragment TaskSearchMasterFragment on query_root {
priorities {
id
name
}
labels {
id
name
}
}
`);
// 汎用マスタデータ用のFragment
const TaskSearchUsersFragment = graphql(/* GraphQL */ `
fragment TaskSearchUsersFragment on User {
id
name
}
`);
type TaskSearchProps = {
masterRef: FragmentType<typeof TaskSearchMasterFragment>;
usersRef: FragmentType<typeof TaskSearchUsersFragment>[];
};
export const TaskSearch: React.FC<TaskSearchProps> = ({
masterRef,
usersRef,
}) => {
const { priorities, labels } = useFragment(
TaskSearchMasterFragment,
masterRef,
);
const users = useFragment(TaskSearchUsersFragment, usersRef);
return (
{/* 省略 */}
);
};
TaskList
TaskListでは、コンテンツデータとして、タスク一覧の Fragment を定義します。
// コンテンツデータ用のFragment
const TaskListFragment = graphql(/* GraphQL */ `
fragment TaskListFragment on Task {
id
title
priority {
id
name
}
labelings {
label {
id
name
}
}
user {
id
name
}
}
`);
type TaskListProps = {
taskListRef: FragmentType<typeof TaskListFragment>[];
};
export const TaskList: React.FC<TaskListProps> = ({ taskListRef }) => {
const tasks = useFragment(TaskListFragment, taskListRef);
return (
{/* 省略 */}
);
};
useUsers
汎用マスタデータ用の Query を定義し、hook として export します。
// 汎用マスタデータ用のQuery
const UsersQuery = graphql(/* GraphQL */ `
query UsersQuery {
users {
...TaskSearchUsersFragment
}
}
`);
export const useUsers = () => useQuery(UsersQuery);
汎用マスタデータは複数のページから利用されます。その際はコンポーネントで定義した Fragment をこの Query に追加していく形になります。
// タスク編集画面で使用するコンポーネントを想定
const TaskEditUsersFragment = graphql(/* GraphQL */ `
fragment TaskEditUsersFragment on User {
id
name
tel
}
`);
// 省略
// 汎用マスタデータ用のQuery
const UsersQuery = graphql(/* GraphQL */ `
query UsersQuery {
users {
...TaskSearchUsersFragment
...TaskEditUsersFragment # 追加する
}
}
`);
export const useUsers = () => useQuery(UsersQuery);
pages/index.tsx
pages/index.tsxではTaskSearchとTaskListの Fragment をまとめて、コンテンツデータとマスタデータの Query の定義をします。また、useUsersの呼び出しも行います。
// コンテンツデータのQuery
const TaskQuery = graphql(/* GraphQL */ `
query TaskQuery {
tasks {
...TaskListFragment
}
}
`);
// マスタデータのQuery
const TaskMasterQuery = graphql(/* GraphQL */ `
query TaskMasterQuery {
...TaskSearchMasterFragment
}
`);
const IndexPage = () => {
const [_, { data: contentData }] = useLazyQuery(TaskQuery);
const { data: masterData } = useQuery(TaskMasterQuery);
const { data: usersDate } = useUsers();
return (
<Container>
<h1>タスク検索</h1>
<TaskSearch masterRef={masterData} usersRef={usersDate.users} />
<TaskList taskListRef={contentData.tasks} />
</Container>
);
};
export default IndexPage;
処理の流れ
上記の実装で想定する処理の流れは下記になります。
- 初回レンダリング時にマスタデータ(
TaskMasterQuery)と汎用マスタデータ(UsersQuery)がリクエストされる - ユーザーが検索ボタンを押下するとコンテンツデータ(
TaskQuery)がリクエストされる
a. 検索条件が同じ(= variables が同じ)であればキャッシュが利用される - 検索ボタンを押下する度に再レンダリングが走る
a. マスタデータ(TaskMasterQuery)と汎用マスタデータ(UsersQuery)はキャッシュが利用されるので、初回レンダリング以降はこれらの Query はリクエストされない
まとめ
GraphQL におけるキャッシュ戦略について、ページ単位でのキャッシュの最適化とデータを3種類に分類する方針について紹介しました。これにより、Fragment Colocation のメリットを生かしつつキャッシュを活用することができます!
ただし、汎用マスターデータが増えるとオーバーフェッチの問題が大きくなり、また管理が複雑になります。現時点では、ほとんどがコンテンツデータとマスタデータで運用できているため問題はありませんが、汎用マスタデータが増えてきた場合には再度その問題について検討する必要があるかなと思っています。

Discussion