自動運転AIチャレンジ LLMをファインチューニングして回帰モデルを構築編
背景
自動運転AIチャレンジ2023(シミュレーション)に参加しており、自作AIの構築とAutoware環境への組み込みにチャレンジしたいと考えております。まずは予測した経路に対して車両を制御するAIを目指していきます。前回の記事「自作AIモデルで車両を制御する(データ収集編)」ではAIの訓練に必要なデータを収集するノードの作成方法について記載しました。今回の記事では収集したデータを用いてAIモデルを構築する方法について記載します。
AIモデルの選定について
今回はAIモデルとして、LLM(Large Language Model)の一つのBERT(Bidirectional Encoder Representations from Transformers)を使用します。BERTを選定した理由は、単に使ってみたかったということが一番大きいのですが、「Planning-oriented Autonomous Driving」という論文で提案されている手法など、Transformerベースのモデルを用いて物体検出から経路計画までをエンドツーエンドで実現する手法が多く研究されています。このような論文を参考にし、私も将来的にはエンドツーエンドのモデル構築にチャレンジしたいと考えたため、Transformerベースのモデルを使用することにしました。また、「PlanT: Explainable Planning Transformers via Object-Level Representations」では事前訓練済みのBERTモデルをファインチューニングして経路計画を行う手法が提案されており、このような論文を参考にし、今回のタスクにおいてもBERTが使えるのではないかと考えました。
BERT について
今回使用するBERTはGoogleによって提案された大規模言語モデル(LLM:Large Language Models)の一種になり、大量のテキストデータを使って訓練された自然言語処理の深層学習モデルになります。多くの場合は、文章を入力として、文章分類や文章校正などのタスクに用いられます。
BERTは以下のような構造になり、Transformerと呼ばれるニューラルネットワークモデルで提案された機構を取り入れること文章内のどの単語に注意を払うべきかを訓練・推論します。
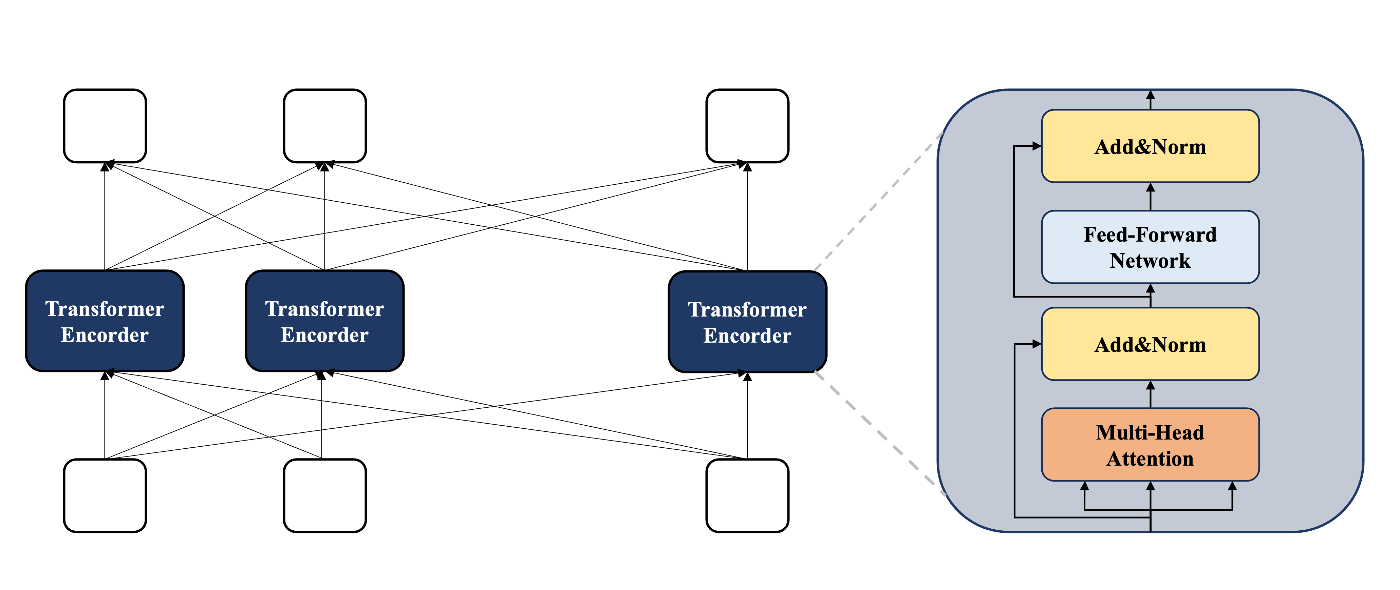
BERT
BERTの詳細については本記事の内容から外れるため割愛させていただきます。もう少し知りたい方はこちらの記事やこちらの書籍などが参考になります。
入力データについて
BERTなどの自然言語ではまず入力の文章をトークンと呼ばれる語彙の単位に分割します。
例えば、以下の例では「明日の天気は晴れだ。」という文章を「'[CLS]' ’明日' 'の' '天気' 'は' '晴れ' 'だ' '。' '[SEP]'」のようなトークンに分割しています。ここで、[CLS]と[SEP]は特殊なトークンになり、[CLS]は入力の先頭に付与され、[SEP]は文章の末尾に付与されます。
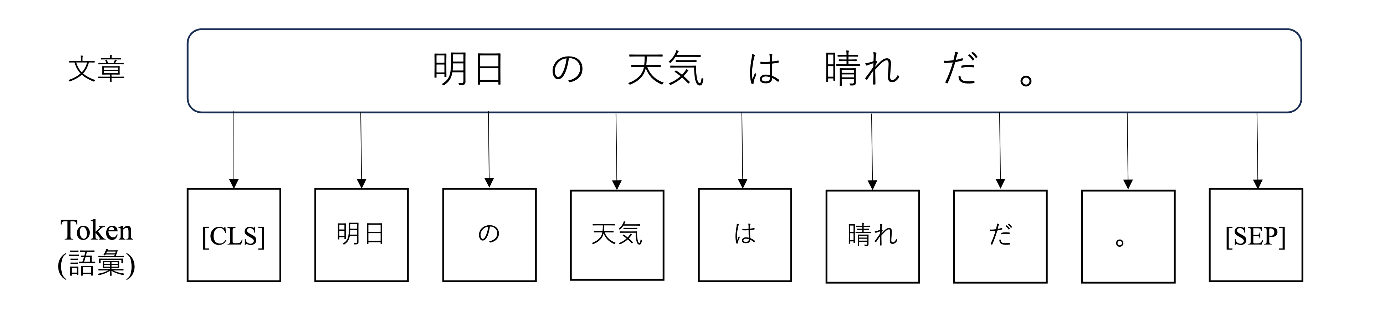
文章のToken化
このようなトークン分割を行った後、IDと呼ばれる語彙ごとに割り振られるユニークな数値に変換されます。例えば、以下の例では「'[CLS]' ’明日' 'の' '天気' 'は' '晴れ' 'だ' '。' '[SEP]'」のようなトークンでは[2 11475 5 11385 9 16577 758 3]というidの列に変換されています。
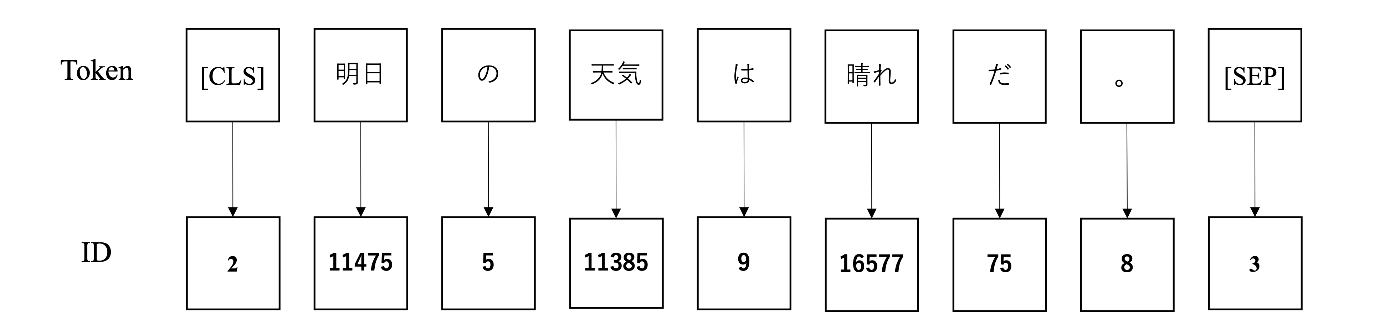
語彙のID化
このように、自然言語処理のモデルでは文章を整数型のベクトルに変換して、モデルに入力します。
ファインチューニングについて
BERTを文章分類や文章校正などの特定のタスクに使用する場合は多くの場合、事前に大量のデータで訓練されたモデル(事前学習モデル)を特定タスク向けにファインチューニングします。また、解きたいタスクが分類問題や回帰問題の場合では以下のようにBERTからの出力を全結合層(linear層)に入力し、タスクに合った要素数のベクトルを出力します。
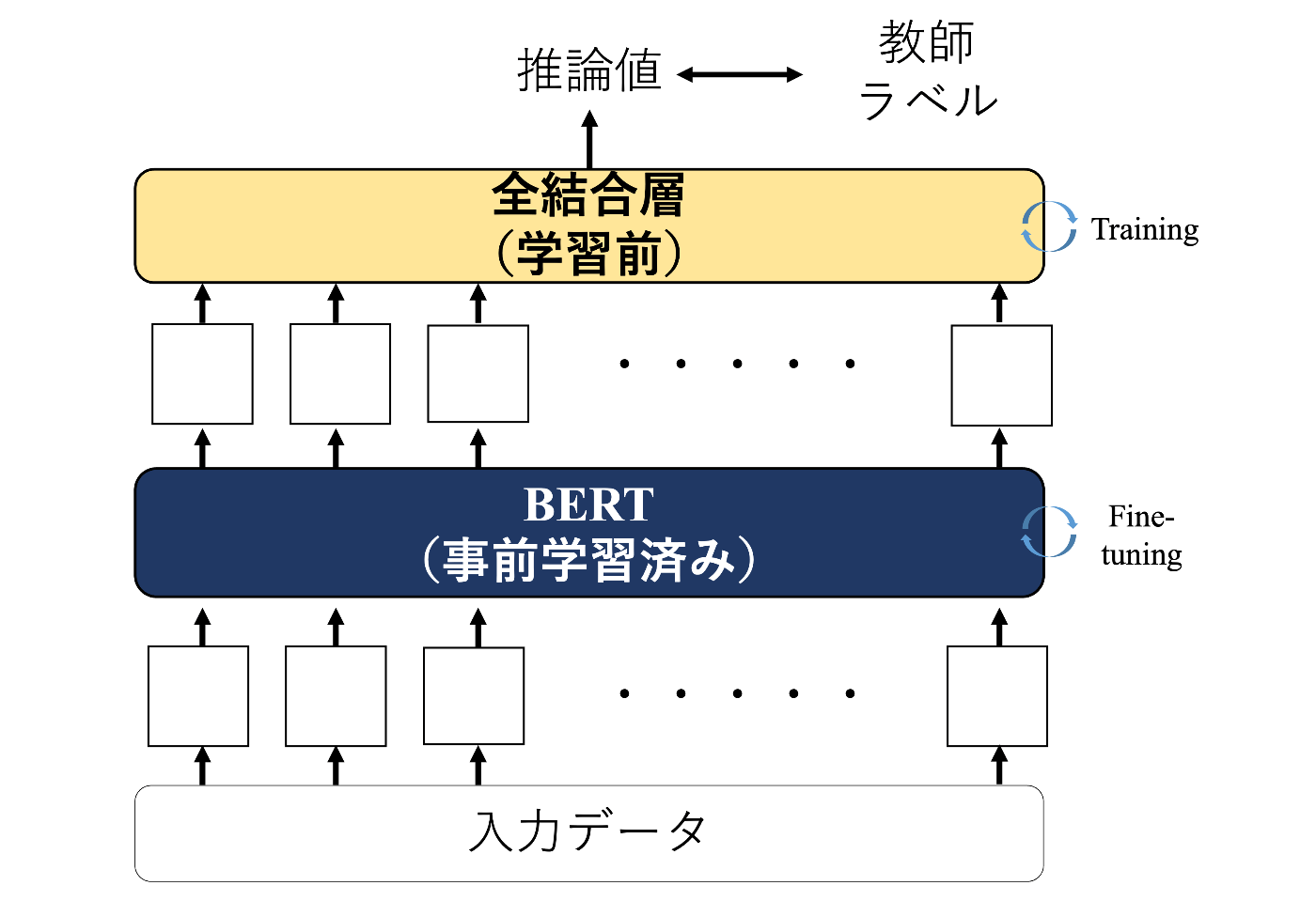
BERTのファインチューニング
図のように訓練時は推論値とタスクごとに準備した教師ラベルを比較し、その値が出力されるようにモデルを最適化します。
自動運転AIチャレンジ用モデルの構築
今回のタスクではBERTモデルのうちより軽量なBERT-tinyを用いて、自動運転走行の制御値を推論します。BERT-Tinyは、自然言語処理モデルの中でも比較的軽量なモデルになり、自動運転タスクに適していると考えました。
今回作成するモデルの概要は以下になります。
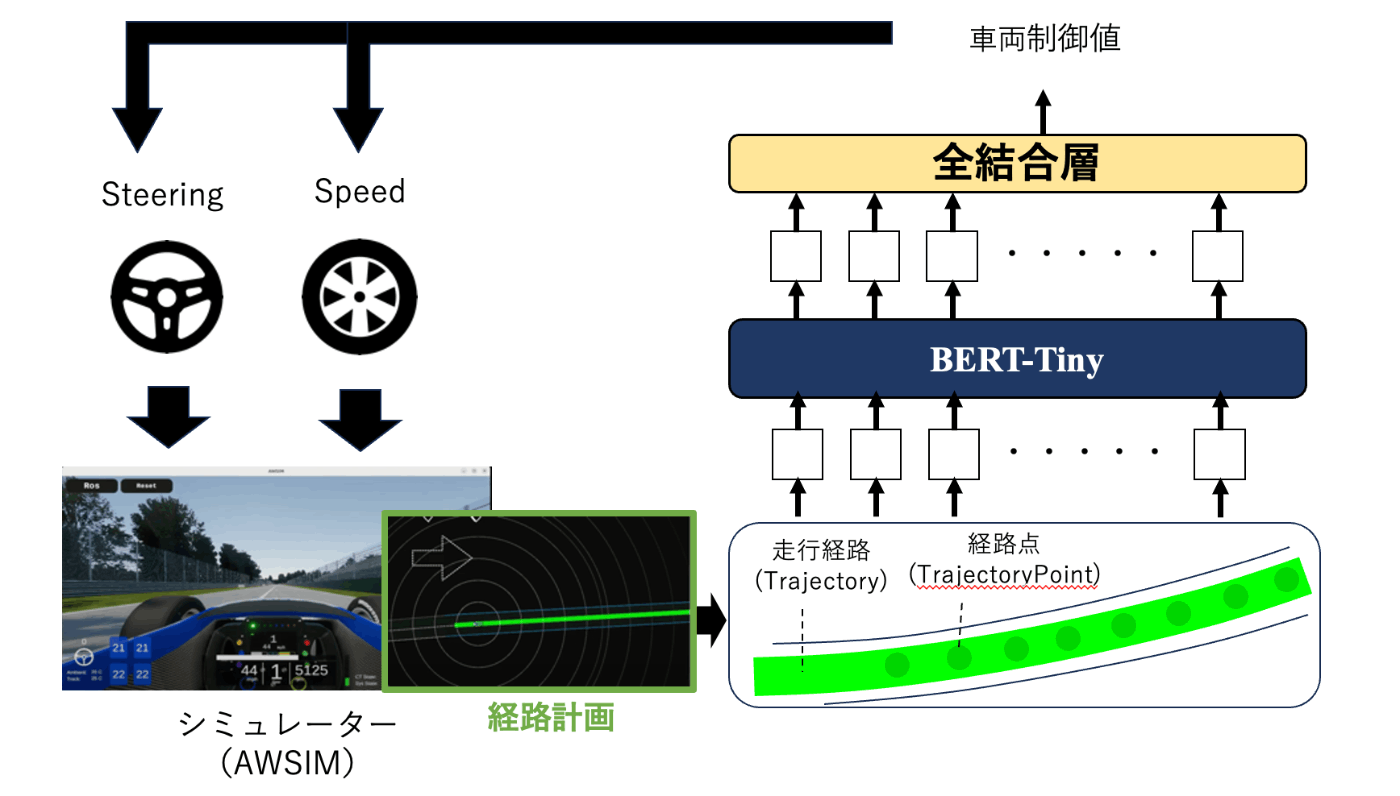
自作AIの全体像
本モデルでは経路計画時に生成された走行経路データ(Trajectory)を入力として使用し、その経路を走行するための車両制御値を出力します。 つまり、経路データからその経路を走行するために最適な制御値を推定する回帰モデルとして訓練します。
訓練/テストデータセット
今回のタスクでは訓練時の教師データが存在しないため、模倣学習によって経路に合わせた制御値を出力するようにモデルを訓練します。模倣学習では対象タスクのエキスパートが取る行動をデータとして保存しておき、モデルの訓練時に教師ラベルとして用いることにより、エキスパートの行動を模倣した行動をとるモデルを構築する方法になります。今回はシミュレーション上で何度かコントローラーで車両を制御し走行させました。コントローラーの制御にある程度慣れてきたら、走行時に生成された経路と入力した制御値を保存しておき、それぞれを訓練時の入力と教師ラベルとして用いました。
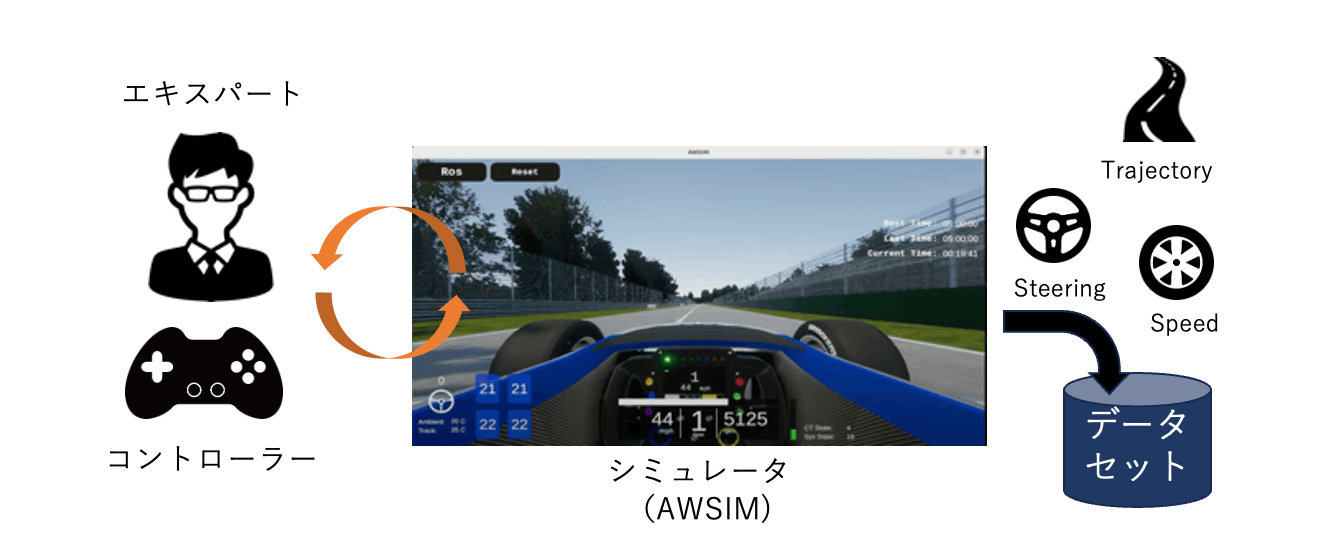
模倣学習
AWSIMの車両をコントローラーで制御する方法についてはこちらの記事に記載しましたので、よろしければご覧ください。
前処理
今回使用する経路(Trajectory)データでは時系列の経路点(TrajectoryPoint)データが含まれるためこれらのデータをBERTへの入力とすることを考えました。具体的には、以下の図のように、前処理によりTrajectoryPointを自然言語処理モデルへ入力できるTokenとして扱うことにしました。
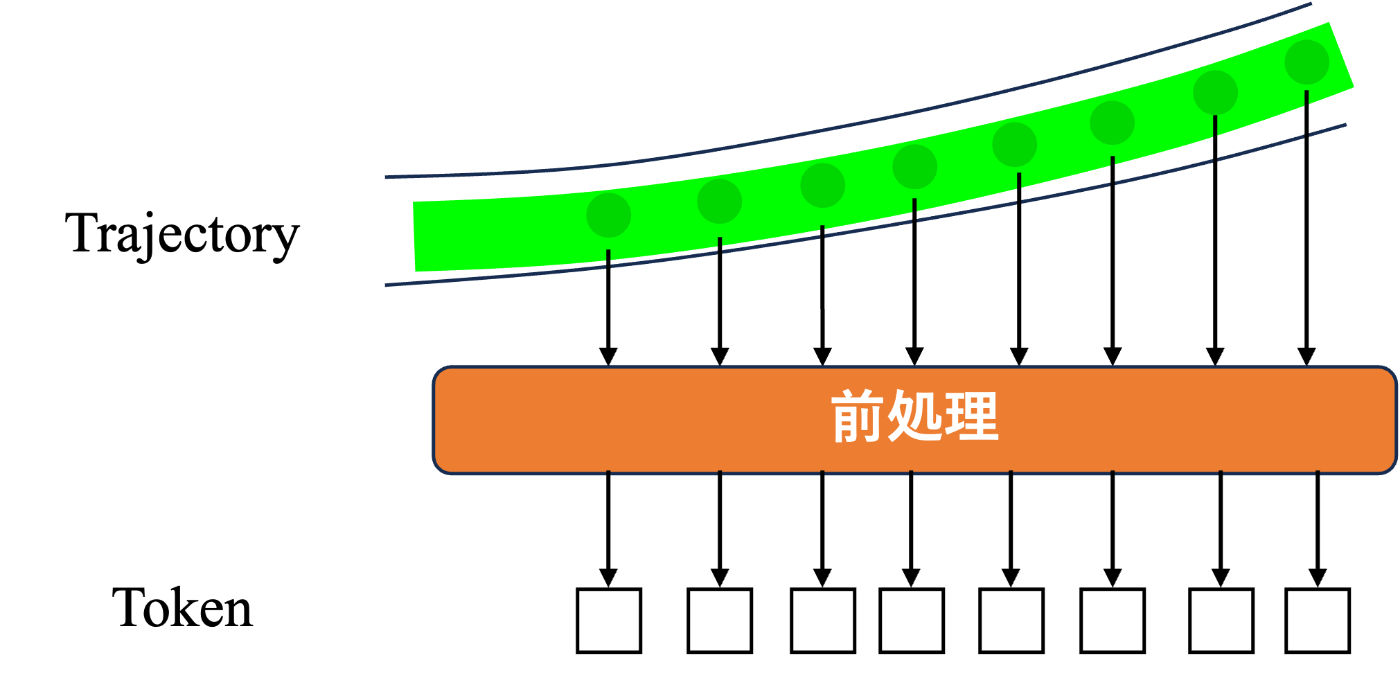
TrajectoryのToken化
しかし、TrajectoryPointは(x,y)の2次元座標に対して、BERTではIDの列を表すベクトルを入力とします。そのため、今回は各TrajectoryPointの2点間の角度を計算し、計算した角度の値をIDとして使用することを考えました。
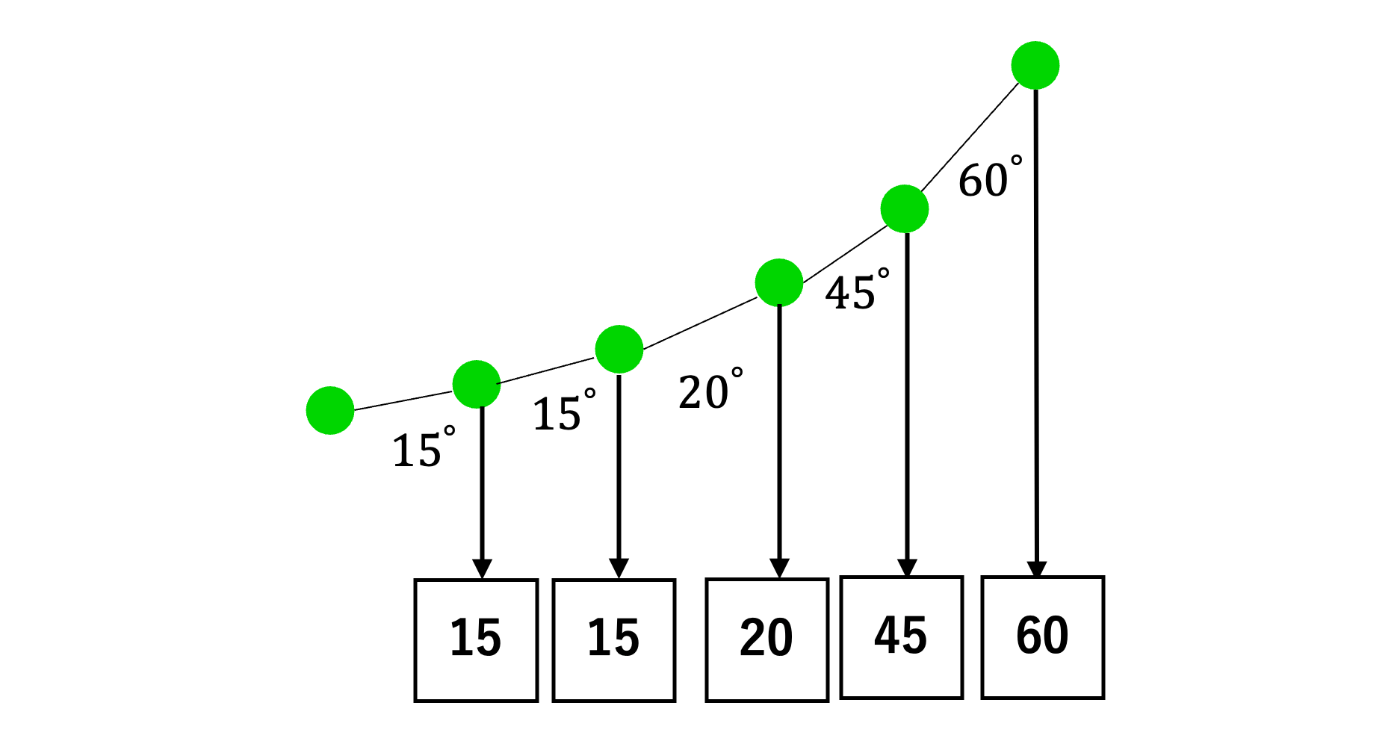
TrajectoryPointのID化
まとめると、本モデルでは Trajectory = 文章、TrajectoryPoint = トークン、角度 = ID として扱い、BERTへの入力データとします。
データ拡張
訓練モデルの汎化性能を上げて今回のタスク以外でも使用できるようにしたかったため、収集したデータだけで学習するのではなく、データ拡張を実施しました。具体的には、以下の図のように入力データの経路の向きをランダムに変更しました。その際、教師ラベルの速度は据え置きとし、ステアリングは経路の向きに応じて変更しました。
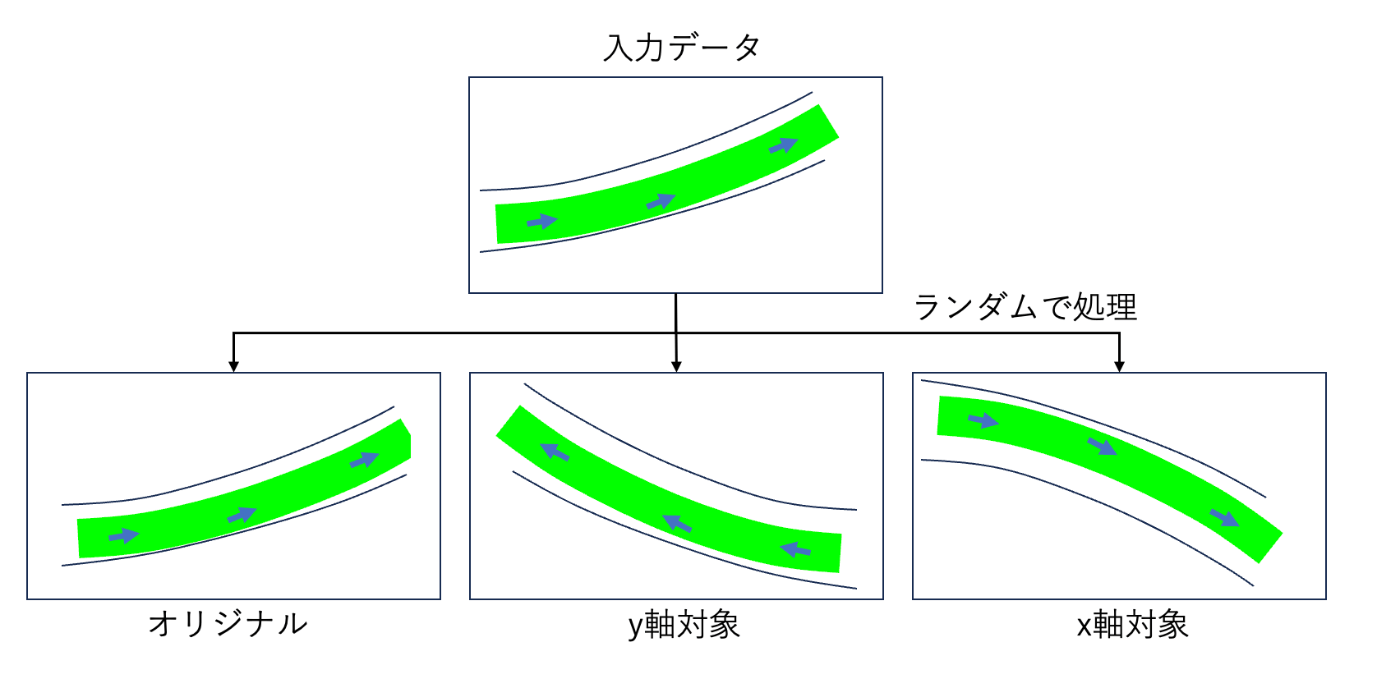
データ拡張
実装
今回実装したコードは以下のリポジトリで公開しました。不十分な点が多々ありますが、ご参考にしていただければ幸いです。
まとめ
本記事では自動運転AIチャレンジ2023に向けて構築した車両制御値の推定用LLMについて紹介しました。今回開発したモデルは走行経路を入力として、その経路を走行する制御値を出力する回帰モデルになります。今後は制御値だけでなく経路値そのものを推定させるモデルの構築などにもチャレンジしていきたいです。
参考
こちらの記事は以下の文献を参考にさせていただいております。
[1]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2]Planning-oriented Autonomous Driving
[3]PlanT: Explainable Planning Transformers via Object-Level Representations
[4]自然言語処理の王様「BERT」の論文を徹底解説
[5]BERTによる自然言語処理入門: Transformersを使った実践プログラミング
[6]【ChatGPT】ファインチューニングをわかりやすく解説
Discussion
AI要素をわかりやすく解説いただきすごいです!