pypipe: コマンドの出力をPythonにパイプでつないで処理する
コマンドの出力をpythonにパイプで渡して処理するためのツールを公開しました
なぜこのようなツールを作ったのかを語って良いでしょうか。是非お願いします!(幻聴)
awkなどの使い方が覚えらない
普通に生きていると、これまでにbashやzshなどで作業している時にコマンドの出力をパイプでPythonにつないで処理したいなと思ったことが一度はあるはずです。例えば以下のようなcsvを扱う場合を考えてみます(ChatGPTに作成してもらいました)。
ghibli.csv
タイトル,監督,公開年,ジャンル
となりのトトロ,宮崎駿,1988,ファンタジー
千と千尋の神隠し,宮崎駿,2001,ファンタジー
ハウルの動く城,宮崎駿,2004,ファンタジー
風の谷のナウシカ,宮崎駿,1984,ファンタジー
もののけ姫,宮崎駿,1997,ファンタジー
紅の豚,宮崎駿,1992,アドベンチャー
借りぐらしのアリエッティ,米林宏昌,2010,ファンタジー
耳をすませば,近藤喜文,1995,ドラマ
思い出のマーニー,山形雄,2014,ドラマ
かぐや姫の物語,高畑勲,2013,ファンタジー
あなたはこのcsvデータからジャンルが「ファンタジー」の行のみ抜き出す必要があります。grepを使って簡単にできます。
$ grep 'ファンタジー$' ghibli.csv
となりのトトロ,宮崎駿,1988,ファンタジー
千と千尋の神隠し,宮崎駿,2001,ファンタジー
ハウルの動く城,宮崎駿,2004,ファンタジー
風の谷のナウシカ,宮崎駿,1984,ファンタジー
もののけ姫,宮崎駿,1997,ファンタジー
借りぐらしのアリエッティ,米林宏昌,2010,ファンタジー
かぐや姫の物語,高畑勲,2013,ファンタジー
さらにこの結果から監督、タイトル、公開年の列をこの順番通りに抜き出さなければなりません。cutコマンドを使えば3項目のみ抜き出すのは簡単です。
$ grep 'ファンタジー$' ghibli.csv |cut -d , -f 2,1,3
となりのトトロ,宮崎駿,1988
千と千尋の神隠し,宮崎駿,2001
ハウルの動く城,宮崎駿,2004
風の谷のナウシカ,宮崎駿,1984
もののけ姫,宮崎駿,1997
借りぐらしのアリエッティ,米林宏昌,2010
かぐや姫の物語,高畑勲,2013
しかしタイトル、監督、公開年の順で出力されており順序が変わっていません。cutコマンドでは列を前後させることはできませんので、こういった場合はawkを使いましょう。
...ここで問題が発生します。awkの使い方が分からないのです。何度か同じような作業でawkを使ったことがあるはずですが、あの独特の構文を覚えられず、使うたびに使い方を調べている自分がいます。頑張って調べて以下の通り実行します。
grep 'ファンタジー$' ghibli.csv | awk -F ',' 'OFS="," {print $2,$1,$3}'
宮崎駿,となりのトトロ,1988
宮崎駿,千と千尋の神隠し,2001
宮崎駿,ハウルの動く城,2004
宮崎駿,風の谷のナウシカ,1984
宮崎駿,もののけ姫,1997
米林宏昌,借りぐらしのアリエッティ,2010
高畑勲,かぐや姫の物語,2013
使い方が分かれば大したことないと思うのですが、次の機会にはまた忘れているわけです。
pythonのワンライナーも厳しい
awkのような素晴らしいコマンドがたくさんあるのですが、コマンドの使い方が身に付かず調べるのが大変なので、じゃあPythonで処理しようとなるわけです。しかしpythonのワンライナーにはfor文の利用に制約があるため、簡単には書けません。上記を無理やり書こうとすると以下のような感じになります。
cat ghibli.csv |python -c 'import sys; [print(line[:-1].split(",")[1],line[:-1].split(",")[0],line[:-1].split(",")[2],sep=","
) for line in sys.stdin]'
かなり無理がありますね。結局普通にpythonスクリプトを書いて処理することになります。
hoge.py
import sys
import csv
for rec in csv.reader(sys.stdin):
if rec[-1] != 'ファンタジー':
continue
print(rec[1], rec[0], rec[2], sep=',')
$ cat ghibli.csv |python hoge.py
宮崎駿,となりのトトロ,1988
宮崎駿,千と千尋の神隠し,2001
宮崎駿,ハウルの動く城,2004
宮崎駿,風の谷のナウシカ,1984
宮崎駿,もののけ姫,1997
米林宏昌,借りぐらしのアリエッティ,2010
高畑勲,かぐや姫の物語,2013
xonsh
こういった感じでshellの中でpythonが簡単に使えたら良いのになと夢見ていたところ、xonshというpythonを統合したシェルがあることに気が付きました。これはと思い試したのですが、シェル自体を置き換えるのに抵抗があり、個人的にはshellとpythonがそこまで密接に連携する必要は無いと感じて使うのをやめました。パイプでpythonにつないで処理できれば自分にとっては十分なので、そういったツールを自作することになったというわけです。
pypipeで簡単pythonパイプ処理
pypipeを使って先の例を処理するとこうなります。
$ cat ghibli.csv |ppp csv -l4 -f 'f4 == "ファンタジー"' f2,f1,f3
宮崎駿,となりのトトロ,1988
宮崎駿,千と千尋の神隠し,2001
宮崎駿,ハウルの動く城,2004
宮崎駿,風の谷のナウシカ,1984
宮崎駿,もののけ姫,1997
米林宏昌,借りぐらしのアリエッティ,2010
高畑勲,かぐや姫の物語,2013
なんかオプションがいっぱいあって、結局pypipeの使い方を覚えなければいけないと思うかもしれませんが、上記の例はpypipeの機能をフル活用した場合であり、もっと愚直にpythonのコードを書くことができます。
$ cat ghibli.csv |ppp -n 'rec = line.split(",")' 'if rec[3] == "ファンタジー": print(rec[1], rec[0], rec[2], sep=",")'
宮崎駿,となりのトトロ,1988
宮崎駿,千と千尋の神隠し,2001
宮崎駿,ハウルの動く城,2004
宮崎駿,風の谷のナウシカ,1984
宮崎駿,もののけ姫,1997
米林宏昌,借りぐらしのアリエッティ,2010
高畑勲,かぐや姫の物語,2013
pypipeを使うとこんなこともできます。
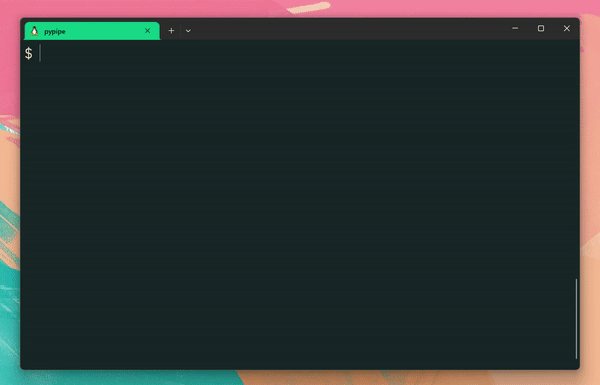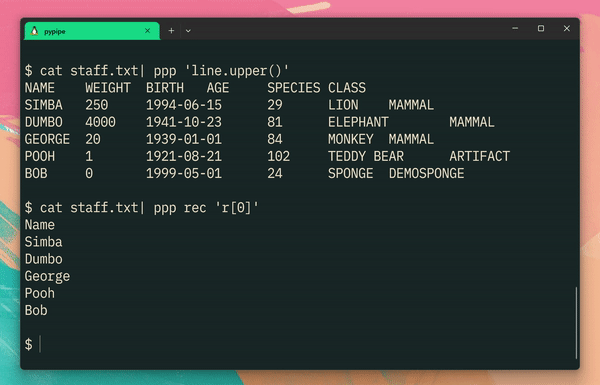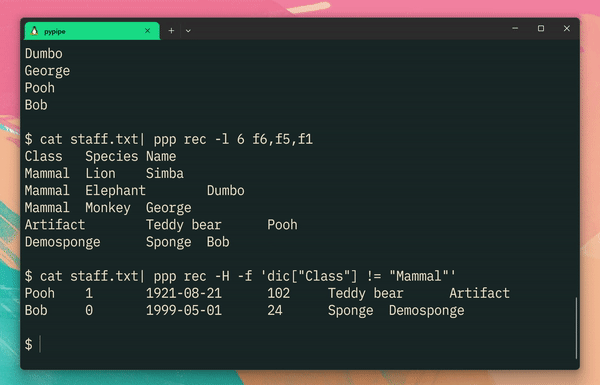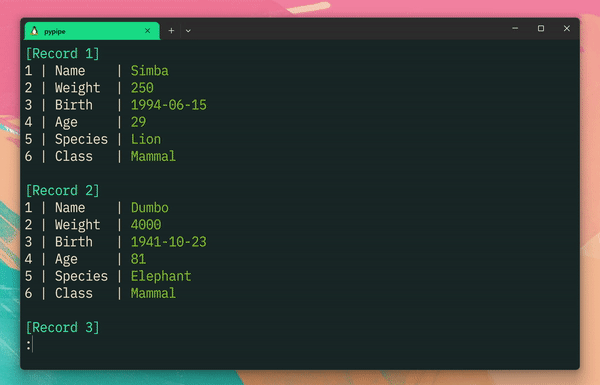
$ head -n 3 ghibli.csv |ppp csv -vH
[Record 1]
1 | タイトル | となりのトトロ
2 | 監督 | 宮崎駿
3 | 公開年 | 1988
4 | ジャンル | ファンタジー
[Record 2]
1 | タイトル | 千と千尋の神隠し
2 | 監督 | 宮崎駿
3 | 公開年 | 2001
4 | ジャンル | ファンタジー
興味があれば是非お試しください。
他の素晴らしいコマンドたち
csvならxsv、jsonならjqなどすでに素晴らしいコマンドが沢山あります。これらを組み合わせて使いこなせるならばpypipeは不要かもしれませんが、pypipeのpythonで処理を書ける利点は他には代えられません。pythonの豊富なライブラリを利用して様々な利用方法が考えられると思います。
私がpypipeを開発した時は知らなかったのですが、pypipeにも偉大な先輩がいます(知ってたらpypipeを作ってなかったと思う)。
似たようなツールなのでお好きなのをどうぞ。
Discussion