📊
【検証】GPTで長文の要約をするなら?(MapReduce・MapRerank・Refine)
今回は、長文をGPTで要約する方法として「MapReduce」「MapRerank」「Refine」の3つを見かけたので、それぞれの「精度」や「費用」、「応答スピード」を簡単に検証して調べてみたメモです。
(注: 今回の評価はChatGPTでしているので主観的な評価は含まれていません。また各プロンプトが細かく作れていなかったり、全体的にざっくりとした検証です。)
📝 検証内容
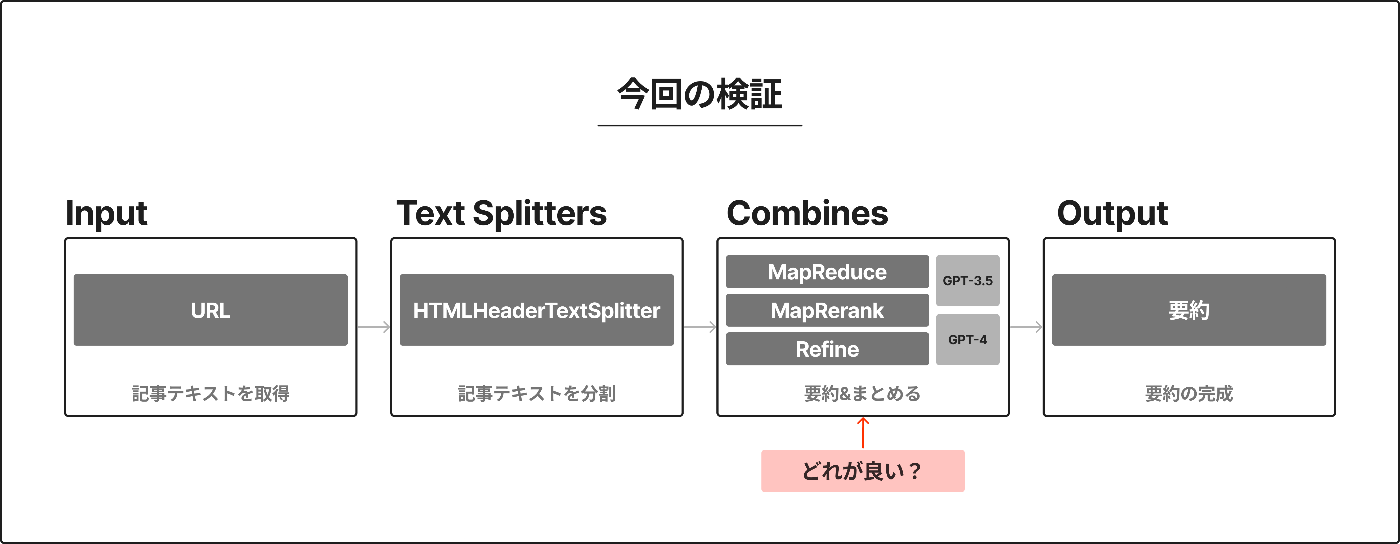
「URLから要約を作成する手法」でどれが優れているのかを検証します。
特に今回は、長文テキストを分割した後の要約&結合処理(Combine)部分の違いが気になったので、そこを中心に行います。
① Input: 検証対象のURL
今回の対象にしたURL
https://openai.com/research/instruction-following
② Text Splitters: 検証のためのテキスト処理
今回の対象テキスト
LangChainのHTMLHeaderTextSplitterで、URLからHTML取得をしテキストを分割しました。
# 今回のテキスト(加工処理後)
- 合計テキスト文字数: 18076
- 分割後のテキスト数: 7
- 分割後のテキストの文字数: [2746, 2006, 2527, 2603, 2806, 2760, 2628]
コード
URLからHTMLを取得して、それを指定チャンクサイズに分割しています。今回は3000を指定。
def split_by_html_header_url(url):
print("--- HTMLHeaderTextSplitter ---")
# --- 取得方法: 分割するタグ指定 ---
headers_to_split_on = [] # タグ指定なし
# --- 取得インスタンス: TextSplitter生成 ---
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# --- 出力 ---
html_header_splits = html_splitter.split_text_from_url(url)
# --- 取得インスタンス2: TextSplitter生成 ---
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""], # チャンクの区切り文字リスト
chunk_size=3000, # チャンクの最大文字数
chunk_overlap=300 # チャンク間の重複する文字数
)
# --- 出力2 ---
result = text_splitter.split_documents(html_header_splits)
return result
split_by_html_header_url("https://openai.com/research/instruction-following")
③ Combines: 検証する要約手法
今回検証する3つの手法
-
MapReduce
- 分割テキストごとに要約を作成して、各要約をまとめて再要約する
-
MapRerank
- 分割テキストごとに回答&自信度を生成して、自信度の高い回答を採用する
-
Refine
- 分割テキストの1つ目を要約し、2つ目以降は「前の要約+分割テキスト」で要約することで、最終的に洗練された要約を作る
🏁 検証結果
| 手法(モデル) | シチュエーション |
|---|---|
| MapReduce(GPT-4) | バランス重視 |
| MapReduce(GPT-3.5) | コスパ重視 |
| MapRerank(GPT-4) | - |
| MapRerank(GPT-3.5) | 低コスト、スピード重視 |
| Refine(GPT-4) | 精度重視 |
| Refine(GPT-3.5) | - |
| 手法(モデル) | 精度1(※) | 精度2(※) | コスト | 生成時間 | 出力文字数 |
|---|---|---|---|---|---|
| MapReduce(GPT-4) | 75 /100 | 85 /100 | 約14.1円($0.09424) | 73.48秒 | 1685文字 |
| MapReduce(GPT-3.5) | 80 /100 | 90 /100 | 約1.4円($0.0093335) | 13.33秒 | 767文字 |
| MapRerank(GPT-4) | 70 /100 | 75 /100 | 約12.6円($0.08393) | 80.34秒 | 673文字 |
| MapRerank(GPT-3.5) | 65 /100😢 | 70 /100😢 | 約1.3円($0.0088355) | 12.57秒 | 438文字 |
| Refine(GPT-4) | 85 /100👑 | 95 /100👑 | 約20.0円($0.13348) | 154.17秒 | 2375文字 |
| Refine(GPT-3.5) | 60 /100 | 80 /100 | 約1.6円($0.010415) | 16.96秒 | 759文字 |
※ChatGPTに評価してもらいました。(👑:トップ、😢:ワースト)
※2回評価を繰り返して、「精度1」は1回目、「精度2」は2回目です。
ChatGPTによる評価プロンプト
- まずは記事を読んでもらう。
あなたは要約の評価担当者です。あなたの仕事は、これから下記記事の要約を6つ提示するので、それらを点数評価することです。
まずは記事を確認することがタスクです。確認できたら「確認しました」とだけ出力してください。確認できたらこの記事の要約を6パターン提示します。
今回のあなたの仕事(評価の精度)は世界的に重要な影響を与えます。
# Title: Aligning language models to follow instructions
# Text:
...(記事の文章をコピペしました。)
- 評価してもらう。
下記6パターンをそれぞれ100点満点で評価してください。
また良い点と改善点・フィードバックを箇条書きで提示してください。
#要約A:
...
#要約B:
...
︙
#要約F:
...
1. MapReduce
コード
# ==================================================
# MapReduceDocumentsChain
# ==================================================
from langchain.chains import (
StuffDocumentsChain,
LLMChain,
ReduceDocumentsChain,
MapReduceDocumentsChain,
)
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI, ChatOpenAI
import requests
from bs4 import BeautifulSoup
from textsplitter import split_by_html_header_url
def map_reduce_documents(url):
# --- タイトル取得 ---
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
title = soup.title.text.strip()
# --- モデル指定 ---
chat_gpt3 = ChatOpenAI(model='gpt-3.5-turbo-0125')
chat_gpt4 = ChatOpenAI(model='gpt-4-0125-preview')
# --- チェーン生成: 要約するチェーン ---
prompt = PromptTemplate.from_template(
"The TEXT below is part of a page with the following title."
"I would like to extract and summarise the content parts of this article, extract and summarise the parts relevant to the title of the TEXT."
"If there is 'no content associated with the title' or 'no specific detail or content exists for the summary', only the Title is output.\n\n"
"Title: " + title + "\n"
"Text:\n{context}\n\n"
"Summary:\n"
)
llm_chain = LLMChain(llm=chat_gpt3, prompt=prompt)
# --- チェーン生成: 結合するチェーン ---
reduce_prompt = PromptTemplate.from_template(
"Summarise the entire summary list of the following titles in plain language.\n\n"
"Title: " + title + "\n"
"Context:\n"
"{context}"
)
reduce_llm_chain = LLMChain(llm=chat_gpt3, prompt=reduce_prompt) # LLMチェーン(LLM+プロンプト)
document_prompt = PromptTemplate(
input_variables=["page_content"],
template="{page_content}"
)
# ドキュメントを結合するためのチェーン
combine_documents_chain = StuffDocumentsChain(
llm_chain=reduce_llm_chain,
document_prompt=document_prompt,
document_variable_name="context"
)
# 結合するチェーン
reduce_documents_chain = ReduceDocumentsChain(
combine_documents_chain=combine_documents_chain,
)
# --- チェーン生成: MapReduce ---
# ドキュメントを分割するためのチェーン
chain = MapReduceDocumentsChain(
llm_chain=llm_chain, # 要約するチェーン
reduce_documents_chain=reduce_documents_chain, # 結合するチェーン
)
result_documents = split_by_html_header_url(url) # ドキュメントを分割する
result_map_reduce = chain.invoke(result_documents) # チェーンを実行する
return result_map_reduce
result = map_reduce_documents("https://openai.com/research/instruction-following")
print(result)
print(result['output_text'])
出力結果: gpt-4-0125-preview
This collection of articles talks about how a new version of AI, called InstructGPT, has been developed to follow instructions better than its predecessor, GPT-3. The key to InstructGPT’s success is that it has been trained with input from people to be more accurate, less likely to make stuff up, and less likely to say harmful things. It does a better job of understanding and doing what users ask, from simple tasks to explaining complex ideas in simple ways. Even though InstructGPT is less complex than GPT-3 in terms of its inner workings, people generally prefer its responses. It has been tested and shown to be safer and more in line with what people want, using techniques that involve learning from human feedback.
The articles also touch on the tricky balance of making these AI models do what users want without losing their ability to perform well on standardized tests for language understanding. A method that mixes in some of the original training data during a fine-tuning process is suggested to keep the AI performing well across the board while still keeping it safe and aligned with human preferences.
Despite these advancements, there are still challenges. The newer models sometimes produce content that's not appropriate, and the articles stress that how these AI tools are put into use also matters for keeping them safe. There's ongoing work to make sure the AI doesn't just cater to the majority but also respects the values and preferences of diverse groups of people. This effort represents the start of applying research to make AI tools that better understand and align with what humans want, underscoring a team effort in addressing these complex issues.
(日本語訳)
この記事集では、InstructGPTと呼ばれる新バージョンのAIが、その前身であるGPT-3よりも優れた指示に従うように開発されたことを語っている。InstructGPTの成功の鍵は、より正確で、作り話をする可能性が低く、有害なことを言う可能性が低いように、人々からのインプットで訓練されたことである。InstructGPTは、単純なタスクから複雑なアイデアをシンプルな方法で説明することまで、ユーザーが求めることをよりよく理解し、実行します。InstructGPTはGPT-3よりも内部構造が複雑でないにもかかわらず、一般的にその反応を好む人が多い。人間のフィードバックから学習するテクニックを使って、より安全で、より人々が望むものに沿っていることがテストされ、示されている。
これらの記事はまた、言語理解に関する標準化されたテストで好成績を収める能力を失うことなく、これらのAIモデルにユーザーの望むことをさせるというトリッキーなバランスについても触れている。AIを安全かつ人間の嗜好に沿った状態に保ちつつ、全体的に良好なパフォーマンスを維持するために、微調整の過程で元の学習データを一部混ぜる方法が提案されている。
こうした進歩にもかかわらず、課題はまだある。新しいモデルは時に適切でないコンテンツを生成することがあり、これらの記事は、これらのAIツールがどのように使用されるかも、安全性を維持するために重要であると強調している。AIが多数派に迎合するだけでなく、多様な人々の価値観や嗜好を尊重するようにするための取り組みが進行中だ。この取り組みは、人間が何を望んでいるのかをよりよく理解し、それに沿ったAIツールを作るための研究を応用することの始まりであり、このような複雑な問題に取り組むためのチームワークを強調するものである。
出力結果: gpt-3.5-turbo-0125
The article discusses the development and implementation of InstructGPT models, which are trained to follow user instructions, be more truthful, and less toxic than previous models like GPT-3. These models have shown superior performance in following English instructions and generating preferred outputs, leading to their deployment as the default language models on their API. The alignment research aims to improve safety, reliability, and overall helpfulness of language models, with a focus on mitigating biases and harms. The text also highlights the importance of aligning language models to prevent misuse and ensure safe outputs, emphasizing the need to consider the values of specific populations and continue developing alignment techniques for AI systems.
(日本語訳)
この記事では、InstructGPTモデルの開発と実装について論じている。InstructGPTモデルは、GPT-3のような以前のモデルよりもユーザーの指示に従うように訓練されており、より真実味があり、毒性が少ない。これらのモデルは、英語の指示に従うことと、好ましい出力を生成することにおいて優れた性能を示し、APIのデフォルト言語モデルとして展開するに至った。アライメント研究は、バイアスや害を軽減することに重点を置き、言語モデルの安全性、信頼性、全体的な有用性を向上させることを目的としている。また、誤用を防ぎ、安全な出力を保証するために言語モデルをアライメントすることの重要性を強調し、特定の集団の価値観を考慮し、AIシステムのためのアライメント技術を開発し続ける必要性を強調している。
2. MapRerank
コード
# ==================================================
# MapRerankDocumentsChain
# ==================================================
from langchain_openai import OpenAI, ChatOpenAI
from langchain.chains import LLMChain, MapRerankDocumentsChain
from langchain_core.prompts import PromptTemplate
from langchain.output_parsers.regex import RegexParser
import requests
from bs4 import BeautifulSoup
from textsplitter import split_by_html_header_url
def map_rerank_documents(url):
# --- タイトル取得 ---
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
title = soup.title.text.strip()
# --- モデル指定 ---
chat_gpt3 = ChatOpenAI(model='gpt-3.5-turbo-0125')
chat_gpt4 = ChatOpenAI(model='gpt-4-0125-preview')
# --- チェーン生成: 要約するチェーン ---
# プロンプト: 各ドキュメントの処理時
prompt_template = (
"The TEXT below is part of a page with the following title."
"I would like to extract and summarise the content part of this article. If the text part of the article exists, please extract and summarise its content."
"For the summary, please identify its main points and express your level of confidence in the summary as a Score."
"If there is 'No content to match the title' or 'No specific details or content present', output `Answer: None\n"
"Score: 0`.\n\n"
"# Output Format:\n"
"Answer: xxx(str)\n"
"Score: xxx(num: 0-100)\n\n"
"# Title: " + title + "\n"
"# Text:\n"
"{context}\n\n"
"# Summary:\n"
)
# 出力のパース: 回答とスコアを取得するための正規表現
output_parser = RegexParser(
regex=r"(.*?)\nScore: (.*)",
output_keys=["answer", "score"],
)
# プロンプト: 各ドキュメントの処理時
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context"],
output_parser=output_parser,
)
llm_chain = LLMChain(llm=chat_gpt3, prompt=prompt)
# --- チェーン生成: MapRerank ---
chain = MapRerankDocumentsChain(
llm_chain=llm_chain,
document_variable_name="context",
rank_key="score",
answer_key="answer",
)
result_documents = split_by_html_header_url(url) # ドキュメントを分割する
result_map_rerank = chain.invoke(result_documents) # チェーンを実行する
return result_map_rerank
result = map_rerank_documents("https://openai.com/research/instruction-following")
print(result)
print(result['output_text'])
出力結果: gpt-4-0125-preview
Answer: The article discusses the development of InstructGPT, an improvement over GPT-3, highlighting its enhanced ability to follow user instructions more accurately. This advancement was achieved through alignment research, incorporating human feedback into the training process, resulting in models that are not only better at understanding and executing tasks as per user intentions but also exhibit increased truthfulness and reduced toxicity. InstructGPT models are now the default on the API. The text includes examples comparing responses of GPT-3 and InstructGPT to various prompts, demonstrating InstructGPT's superior comprehension and execution of instructions.
(日本語訳)
回答 この論文では、GPT-3を改良したInstructGPTの開発について論じており、より正確にユーザーの指示に従う能力が強化されたことを強調している。この進歩は、人間のフィードバックを訓練プロセスに取り入れたアラインメント研究によって達成され、その結果、ユーザーの意図通りにタスクを理解し実行する能力が向上しただけでなく、真実性が高まり、毒性が減少したモデルを実現しました。InstructGPTモデルは現在APIのデフォルトとなっている。本文には、様々なプロンプトに対するGPT-3とInstructGPTの応答を比較した例が含まれており、InstructGPTの優れた命令の理解と実行が実証されています。
出力結果: gpt-3.5-turbo-0125
The article discusses the development of InstructGPT models, which are trained to better follow user intentions compared to GPT-3. These models are also designed to be more truthful and less toxic. The InstructGPT models are trained with humans in the loop and have been deployed as the default language models on their API. The examples provided show that InstructGPT performs better at following English instructions compared to GPT-3.
(日本語訳)
この記事では、GPT-3と比較してよりユーザーの意図に沿うように訓練されたInstructGPTモデルの開発について論じている。これらのモデルはまた、より真実味があり、毒性が少ないように設計されている。InstructGPTモデルは、ループ内で人間を使って訓練され、APIのデフォルト言語モデルとしてデプロイされている。提供された例は、InstructGPTがGPT-3と比較して、英語の指示に従うことで、より優れた性能を発揮することを示しています。
3. Refine
コード
# ==================================================
# RefineDocumentsChain
# ==================================================
from langchain_openai import OpenAI, ChatOpenAI
from langchain.chains import RefineDocumentsChain, LLMChain
from langchain_core.prompts import PromptTemplate
import requests
from bs4 import BeautifulSoup
from textsplitter import split_by_html_header_url
def refine_documents(url):
# --- タイトル取得 ---
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
title = soup.title.text.strip()
# --- モデル指定 ---
chat_gpt3 = ChatOpenAI(model='gpt-3.5-turbo-0125')
chat_gpt4 = ChatOpenAI(model='gpt-4-0125-preview')
# --- チェーン生成: 1番目に要約するチェーン ---
document_prompt = PromptTemplate(
input_variables=["page_content"],
template="{page_content}"
)
prompt = PromptTemplate.from_template(
"The TEXT below is part of a page with the following title."
"I would like to extract and summarise the content parts of this article, extract and summarise the parts relevant to the title of the TEXT."
"If there is 'no content associated with the title' or 'no specific detail or content exists for the summary', output Title.\n"
"# Title: " + title + "\n"
"# Text:\n"
"{context}\n\n"
"# Summary:\n"
)
initial_llm_chain = LLMChain(llm=chat_gpt3, prompt=prompt)
# --- チェーン生成: 2番目以降に要約するチェーン ---
prompt_refine = PromptTemplate.from_template(
"The TEXT below is part of a page with the following title."
"The Previous Summary also summarises the context immediately preceding this TEXT."
"Build on the Previous Summary and refine it with additional insights and details found in the TEXT."
"Focus on strengthening the summary by integrating relevant information that supplements or clarifies the initial main points."
"Try to maintain consistency and add value to the initial summary without repeating information already mentioned.\n\n"
"# Title: " + title + "\n"
"# Previous Summary:\n{prev_summary}\n\n"
"# Text:\n{context}\n\n"
"# Summary:\n"
)
refine_llm_chain = LLMChain(llm=chat_gpt3, prompt=prompt_refine)
# --- チェーン生成: Refine ---
chain = RefineDocumentsChain(
initial_llm_chain=initial_llm_chain,
refine_llm_chain=refine_llm_chain,
document_prompt=document_prompt,
document_variable_name="context",
initial_response_name="prev_summary",
)
result_documents = split_by_html_header_url(url) # ドキュメントを分割する
result_refine = chain.invoke(result_documents) # チェーンを実行する
return result_refine
result = refine_documents("https://openai.com/research/instruction-following")
print(result)
print(result['output_text'])
出力結果: gpt-4-0125-preview
Building upon the initial summary, the additional insights from the text highlight OpenAI's commitment to addressing the complex challenge of ensuring that InstructGPT models refuse to execute potentially harmful instructions. This highlights the ongoing struggle to balance user instruction compliance with the imperative to prevent misuse. Furthermore, the text reveals an awareness of the model's current limitations in representing diverse cultural values, particularly those of non-English speaking communities. This underscores a broader challenge in AI alignment: the ethical and societal implications of whose values are prioritized in model outputs. OpenAI acknowledges the necessity of developing more inclusive, responsible processes for determining how models should align with the diverse values of global users.
Moreover, the text reiterates the effectiveness of the strategies employed to mitigate the alignment tax, ensuring models remain useful for a broad range of academic and practical applications. It also emphasizes the initial success in generalizing the model to align with a wider array of human preferences beyond the training labelers, an essential step towards creating universally acceptable AI systems.
However, these advancements come with the acknowledgment of the ongoing challenges in completely safeguarding against the generation of toxic, biased, or otherwise harmful content. This necessitates continuous efforts in refining content filters, monitoring for misuse, and exploring more nuanced approaches to model training that consider the varied societal impacts of AI-generated content.
OpenAI positions these efforts as just the beginning of a long-term commitment to enhance the safety, utility, and alignment of AI with human values. The call for collaboration and further research in this area indicates an open acknowledgment of the complexities involved in AI alignment and the need for a collective effort to tackle these challenges.
This refined summary not only elaborates on the strategies and challenges in aligning InstructGPT with human instructions and ethical standards but also underscores the broader societal implications of these efforts. It highlights the importance of ongoing research, inclusivity, and responsible decision-making in the development of AI models that are aligned with a diverse range of human values.
(日本語訳)
最初の要約に基づき、本文からの追加的な洞察は、InstructGPTモデルが潜在的に有害な命令の実行を拒否することを保証するという複雑な課題に取り組むOpenAIのコミットメントを強調しています。これは、ユーザー指示の遵守と誤用を防止する必要性とのバランスを取るための継続的な闘いを浮き彫りにしています。さらに、この文章は、多様な文化的価値観、特に非英語圏のコミュニティの価値観を表現する上でのモデルの現在の限界を認識していることを明らかにしている。このことは、AI連携におけるより広範な課題、すなわち、モデルの出力において誰の価値観が優先されるかという倫理的・社会的な意味を強調している。OpenAIは、グローバルユーザーの多様な価値観にモデルがどのように合致すべきかを決定するために、より包括的で責任あるプロセスを開発する必要性を認めています。
さらに、この文章では、アライメント税を軽減するために採用された戦略の有効性を再確認し、モデルが広範な学術的・実用的用途に有用であり続けることを保証している。また、学習用ラベラーだけでなく、より幅広い人間の嗜好に合致するようモデルを一般化することに最初に成功したことも強調している。
しかし、これらの進歩は、有害な、偏った、またはその他の有害なコンテンツの生成から完全に保護するための継続的な課題を認識することを伴う。そのため、コンテンツフィルターを改良し、悪用を監視し、AIが生成するコンテンツの様々な社会的影響を考慮した、より微妙なモデルトレーニングのアプローチを探求する継続的な取り組みが必要です。
OpenAIは、これらの取り組みを、AIの安全性、有用性、人間の価値観との整合性を高めるための長期的な取り組みの始まりに過ぎないと位置づけています。この分野での協力とさらなる研究の呼びかけは、AIのアライメントに関わる複雑さと、これらの課題に取り組むための集団的努力の必要性を率直に認めていることを示している。
この洗練された要約は、InstructGPTを人間の指示や倫理基準と整合させるための戦略や課題について詳しく述べているだけでなく、これらの取り組みがより広範な社会的意味を持つことも強調している。多様な人間の価値観に沿ったAIモデルの開発における、継続的な研究、包括性、責任ある意思決定の重要性を強調している。
出力結果: gpt-3.5-turbo-0125
The InstructGPT models, designed to enhance adherence to user instructions, face challenges in aligning with diverse user groups and avoiding misuse. To address this, models need to be trained to refuse unsafe instructions, prioritize the preferences of specific populations, and align outputs with diverse cultural values. Research is ongoing to understand and address differences in user preferences and ensure responsible decision-making in aligning model outputs. The application of alignment techniques has shown promise in improving the alignment of AI systems with human intentions, but further advancements are needed to create safe and beneficial language tools. Efforts are underway to refine these techniques and enhance alignment with user values.
(日本語訳)
InstructGPTモデルは、利用者の指示の遵守を高めるように設計されているが、多様な利用者グループと連携し、誤用を避けるという課題に直面している。これに対処するためには、危険な指示を拒否し、特定の集団の嗜好を優先し、多様な文化的価値観に沿った出力を行うよう、モデルを訓練する必要がある。ユーザーの嗜好の違いを理解し、それに対処し、モデルの出力を整合させる際の責任ある意思決定を確実にするための研究が進行中である。アライメント技術の応用は、AIシステムと人間の意図とのアライメントを改善する上で有望であるが、安全で有益な言語ツールを作成するためにはさらなる進歩が必要である。これらの技術を改良し、ユーザーの価値観との整合性を強化するための取り組みが進行中である。
まとめ
ざっくりとMapReduce・MapRerank・Refineを使った要約の違いを検証してみました。
結果だけ見ると、精度を求めるなら「Refine(GPT-4)」、コスパなら「MapReduce(GPT-3.5)」、という感じ。GPT-3.5でもある程度の精度が出せそうなのが意外でした。
今回はそれぞれ簡単に作成したプロンプトで試したため、プロンプトを変えると結果が大きく変わるかもしれません。
今後は、最終的な要約が長くなりすぎないようにしたり、日本語での出力をしたり、いろいろと試してみようと思います。
Discussion