DSPyのOptimizerの論文を読んでいく
DSPyはLLMを用いたエージェントやシステムを構築するためのPythonベースのフレームワークで、対象としている領域自体はLangChainやPydantic-aiなどと近い。しかし、DSPyのユニークなところは「プロンプトではなくプログラミング」という主題の元、テキストプロンプトを書くのではなく、Pythonで定義された入出力型とモジュールを組み合わせてシステムを作るところ。プロンプトをハードコードしないことの大きな利点として、システム内で実際にLLMに渡されるプロンプトを目的関数やLLMの設定に合わせて最適化することが可能になる。
例えばReActエージェントを定義して最適化する流れがこれ
import dspy
from dspy.datasets import HotPotQA
dspy.configure(lm=dspy.LM("openai/gpt-4o-mini"))
def search_wikipedia(query: str) -> list[str]:
results = dspy.ColBERTv2(url="http://20.102.90.50:2017/wiki17_abstracts")(query, k=3)
return [x["text"] for x in results]
trainset = [x.with_inputs('question') for x in HotPotQA(train_seed=2024, train_size=500).train]
react = dspy.ReAct("question -> answer", tools=[search_wikipedia])
tp = dspy.MIPROv2(metric=dspy.evaluate.answer_exact_match, auto="light", num_threads=24)
optimized_react = tp.compile(react, trainset=trainset)
dspy.ReActは高級クラスで実際には中でツールの実行やLLMを呼び出すモジュールが使われている。"question->answer"の部分はシグネチャと呼ばれ、モジュールの入出力形式を定義する大事な要素。
MIPROv2はDSPyに実装されている最適化アルゴリズムの1つで、tp.compileを呼ぶことで指定されたmetricを最大化するようにプロンプトを最適化してくれる。DSPyではteleprompterというフォルダ下にさまざまな最適化アルゴリズムが実装されており、今回はこれらを見ていく。
まずはMIPRO (Multiprompt Instruction PRoposal Optimizer): https://arxiv.org/pdf/2406.11695
2024年に主にStanfordのPhD生とDSPyの作者(現在UC Berkeley教授)らよって発表された論文。
MIPROではマルチステップのLLMシステム(複数のLLM呼び出しを含んだシステム)において、それぞれの呼び出しに対する評価指標やラベルがなくても、E2Eの入出力と評価指標のみを用いて内部のプロンプトを最適化することがゴール。
プロンプト最適化は基本的には指示文や例示などの変数の組み合わせを発見する探索問題である。マルチステージのプロンプト最適化ではこの探索について主に2つの問題がある。
- 提案問題: モジュールの数が増えるとともに、プロンプトの組み合わせ候補の数は膨大になる・
- クレジット配分問題: E2Eで複数のプロンプトを同時に最適化するため、それぞれの変数の最終的な結果への影響を効率的に見積もる必要がある。
MIPROでは、プロポーザーという役割のLLMを設けることでこの問題を解決しようとしている。
提案問題への対策:
- ブートストラッピング: 最初に正解を出せたいくつかのケースで、中間ステップの入出力(トレース)を記録し、他のケースを解く際の例示としてプロンプトに含める。
- グラウンディング: プロポーザーにデータセットの特徴やプログラムの制御フロー、いくつかの成功例などの情報を与えて指示文を生成させる。
- プロポーザーの学習: Temperatureやグラウンディングで渡す情報の取捨選択などのハイパーパラメータを、ベイズ最適化で決定する。
クレジット配分問題への対策
全体のスコアから各モジュールの貢献度を適切に割り当てる3つの手法を提案:
- 貪欲法: 各モジュールを順番に最適化する。効率性の問題があり、またあるモジュールの変更が他のモジュールの改善に依存している場合機能しない。
- サロゲートモデル: ベイズ学習で過去の評価から有望な組み合わせを予測し、効率的に探索する。
- 履歴ベース: 強力なLMに過去の評価履歴を与え、クレジット配分と新提案を同時実行させる。
実際のMIPROアルゴリズムではこれらの戦略を組み合わせる、複雑なマルチステッププログラムの効果的な最適化を実現する。
MIPROの論文では次の2つの既存手法をベースラインとして評価している。
- ブートストラップ+ランダムサーチ: 上手くいくケースを例示として与えるが、その選び方はランダムサーチで行う。
- モジュールレベルOPRO: 各モジュールに対して独立して、過去の指示文とスコア履歴をプロポーザーLMに提示し、新しいプロンプトを生成させる。
一方提案手法としては以下を実装する。
- 初期化: ブートストラッピングでFew-shot例を生成し、グラウンディングで指示文候補を準備
- ベイズ最適化: Tree-structured Parzen Estimatorで過去の評価から最適な組み合わせを学習・提案
- 効率的評価: ミニバッチ評価でノイズ耐性を確保し、定期的に全データセットで最終検証
実験結果はこんな感じ

素直な感想として、そもそもBootstrap RSが結構強い。これらのLesson Learnedでも触れられていて、HotPot QAのような単純なタスクでは複雑な多段階LLMシステムや指示文を必要としないので、もっと実用的で難しいタスクだと差が出てくるんだろう。この辺りはLLMの評価用ベンチマークがサチってきている傾向とも重なる。
ちなみにDSPy実装はこちら。
まず最初にTrainセットからFew-shot Exampleをブートストラップ。
# Step 1: Bootstrap few-shot examples
demo_candidates = self._bootstrap_fewshot_examples(program, trainset, seed, teacher)
これは内部でブートストラップ用の共通モジュールを呼んでいて、実際にTrainセットの各サンプルについてシステムを実行して、スコアが閾値以上のものを取るようになっている。
次に指示文の候補をいくつかプロポーザーに作成させる
# Step 2: Propose instruction candidates
instruction_candidates = self._propose_instructions(
program,
trainset,
...
)
その中ではGroundedProposerというモジュールが使われていて、論文中にもあったようにデータセットの特徴やFew~shot Sampleを基にLLMに指示分を生成させている。面白いのは、このプロポーザー自体もDSPyを用いて書かれている(https://github.com/stanfordnlp/dspy/blob/main/dspy/propose/grounded_proposer.py#L128)
最後にFew-shot Examplesと指示分の最適な組み合わせを探索する。
# Step 3: Find optimal prompt parameters
best_program = self._optimize_prompt_parameters(
program,
instruction_candidates,
...
)
ここは論文にもあるようにOptunaを用いてベイズ最適化をおこなっている。これはクレジット配分問題のところで提案されているサロゲートモデルに対応している。
つまりMIPROを端的に表すと、
- Few Shot Examplesをブートストラップする。具体的には、学習データセットの中で最適化前のシステムでも既にスコアの高いものを選んで、その推論過程をFew-shot Exampleとして用いる。
- ブートストラップした例やデータセットの要約のようなさまざまな情報をLLM(プロポーザー)に渡して指示文を複数生成する。
- Few-shot Examplesと指示文の最適な組み合わせをベイズ最適化で決定する。
というアルゴリズムになっている。
次はSIMBAかGEPAの論文を読みたい。
もう少し調べてみると、系列的にはMIPRO→GEPA→SIMBAの順番みたいなので、その通りに読んでみよう。
GEPAはBerkleyのPhD生を筆頭著者に、MIPRO同様にMIT・Stanford・Databricksなどから成るDSPyの研究グループから出た論文。GEPAはGenetic-Paretoの略で、プロンプトの進化的探索と、改善候補の生成に自然言語によるフィードバックを採用することで、少ないサンプルでより高い性能を達成することができる。一般にLLMやAgentの推論はコストが高く、限られた試行回数で効率的に最適化することが実用面では重要になる。
また最近ではGRPOのように強化学習ベースで個別のタスクに最適化する手法が盛り上がっているが、論文ではスパースな数値のRewardから求めた勾配よりも、直接解釈可能な自然言語での指示の方が情報伝達媒体として優れていると主張しており、実際GEPAはGRPOより遥かに少ないサンプル数(35分の1)で平均して10%以上高い性能を示している。

GEPAによる最適化の工夫点は、
- プロンプトの改善に自然言語によるフィードバックを利用する。評価セットの生成結果と評価指標、そして生成のトラジェクトリー(トレース)を用いて、自然言語による「Reflection(反省)」を生成する。
- プロンプトの改善は進化的に行われる。新しいプロンプトの候補は、前の世代のプロンプトに対して新しいフィードバックに基づく変更を加えることで作成される。
- Pareto側面に基づいて行うことで、局所最適化を防ぎながら効率的な探索を行う。具体的には、全体のスコアが高いプロンプトを探索するだけでなく、各サンプルについて良い結果を出したものを確立的に探索に含める。
GEPAの最適化フローを表した図がこちら。分かり易くて助かる。。。
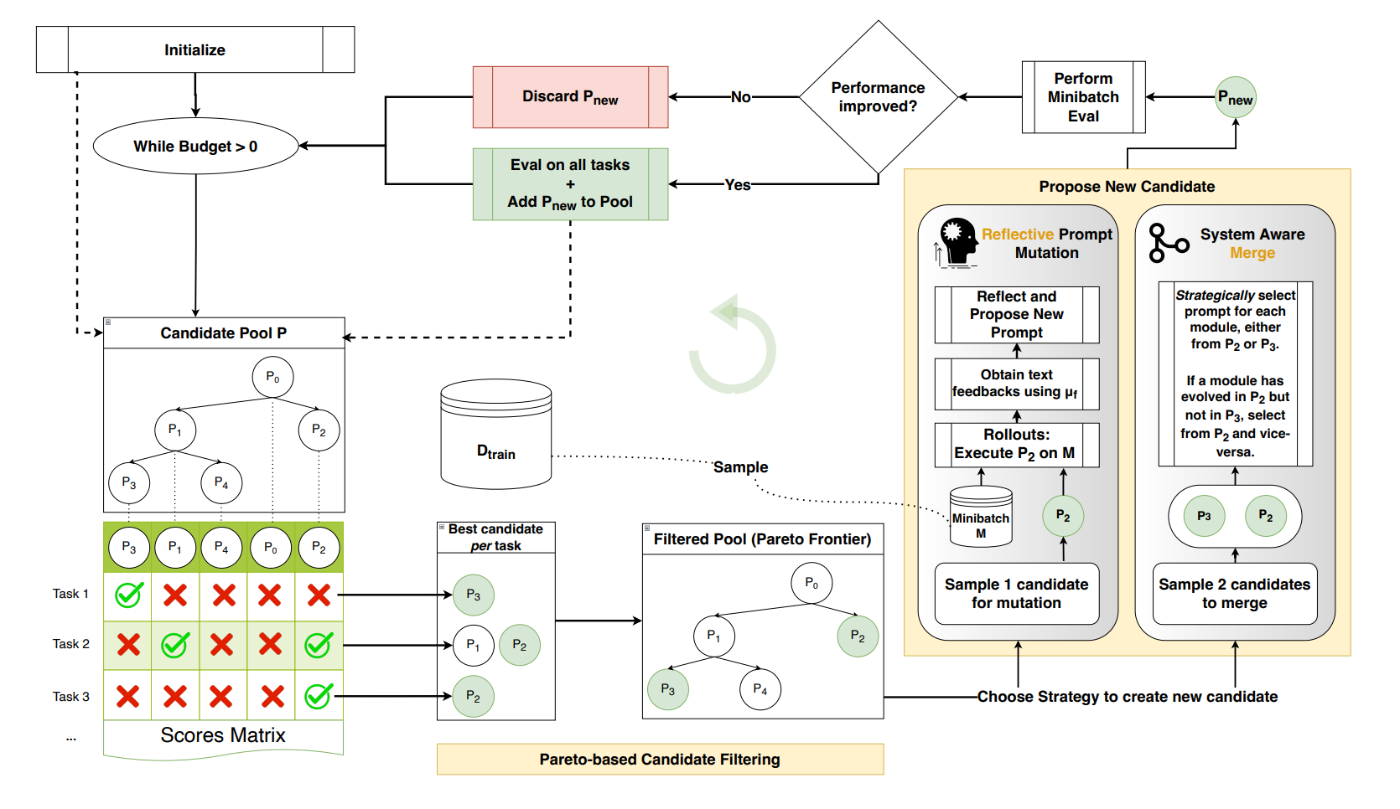
- はじめに適当なプロンプトをプロンプト候補集合
{P} - 学習データ
D_{train} D_{feedback} D_{pareto} -
D_{pareto} {P} - 評価結果を元に後述の探索アルゴリズムを用いてk個の候補を選択する。
- 今度は
D_{feedback} - プロンプトを次のうちいずれかの方法で更新する。(1)フィードバックを用いたプロンプトの変更・(2)2つのプロンプト候補のマージ。
- 更新したプロンプトを
D_{feedback} {P} - 全体の計算バジェットが尽きていなければ、3に戻る。
- バジェットが尽きたところで更新を終了し、
D_{pareto}
ステップ4の探索アルゴリズムでは、Mouret & Clune, 2015で提案されているParetoベースの手法を応用することで、局所最適化を防止している。例えば、最も単純な探索方法は、候補の中でデータセット全体に推し並べて最も性能の良いものを選んでいくというGreedyな方法だが、これでは局所最適化に陥りやすい。そこで、Paretoベースの探索では全体の平均的な性能が良いものではなく、各サンプルについてスコアの高いものを候補に選んでいく。
- まず各サンプルで最もスコアの高いプロンプトを選ぶ。上の図で言うと、
Task_1 P_3 Task_2 P_1 P_2 Task_3 P_2 - 選ばれた候補の中で、上位互換が存在するものを取り除く。例えば、
P_1 Task_2 P_2 P_2 Task_3 P_1 P_1 P_1 - 残った候補の中からさらに確率的に選択する。このとき、多くのタスクでベストスコアを出している候補には重み付けをして選ばれ易くする。
ステップ6のプロンプト更新は以下のように行われる。
- 最初に修正したい部分(モジュール)を1つ選ぶ。ラウンドロビン方式で満遍なく更新対象のモジュールが選ばれるようにする。
- その部分のプロンプト(指示文)をもとに推論を行って、成功/失敗の記録をとる。
- 実行のトレースを元に、更新対象のモジュールの入出力と思考内容を特定する。
- それらの情報に基づいて、LLMに新しいプロンプトを生成させる。
また、推論のトレースだけでなく、評価プロセスの詳細もプロンプトの改善に役立つとしている。例えば、コード生成の評価なら「コンパイル→実行→結果確認」といった段階ごとの結果が細かいフィードバックとして利用できる。そこで、GEPAでは評価指標の実装に一手間加えて、こうした評価の詳細をfeedback_textとして返すようにしている。