Amazon Athenaのフェデレーテッドクエリを使ってDynamoDBのデータをReactからCSV出力する
業務システムなどの管理画面の開発をしていると、何らかのデータを CSV 出力するという機能がよくあると思います。たとえば、集計済みのデータを CSV 出力するであったり、なんらかのマスタデータを CSV 出力したいなど。従来の Web アプリケーションだと、データベースからデータを抽出しアプリケーションで CSV 形式に加工し出力する処理を実装する必要があります。こういったユースケースに対して Amazon Athena を使うことでこの CSV 出力の処理を比較的簡単に実現できました。最近 DynamoDB に格納されているマスタデータを Amazon Athena を用いて CSV 出力するという機能を実装したので、備忘録としてまとめようと思います。
結論
結論としては、Athena のクエリの実行結果を CSV で S3 に保存する特性を活かして、以下のような処理を実装し CSV 出力を実現しました。
- Athena のフェデレーテッドクエリを使って、DynamoDB のデータを SQL でクエリできるようにする
- CSV 出力に必要なデータを SQL でクエリする API を用意する
- 結果のステータスを定期的に問い合わせる API を用意する
- フロントエンドから CSV 出力のボタンを押して、2.の API を実行する
- 2.の API の実行結果を定期的にフロントエンドからポーリングする
- Athena の処理結果が
SUCCEEDになったら、S3 の PreSignedUrl が返却されるので、それをブラウザから直接呼び出す - CSV がダウンロードされる
1 つ 1 つ手順を見ていきます。
DynamoDB テーブルにサンプルデータを用意する
まずは、サンプルデータを DynamoDB に作成します。以下のリポジトリの CloudFormation テンプレートとサンプル CSV ファイルを使って、DynamoDB にサンプルデータを保存します。
上記のリポジトリから CloudFormation テンプレートをアップロードし、スタック作成画面で以下のように入力しスタックを作成します。
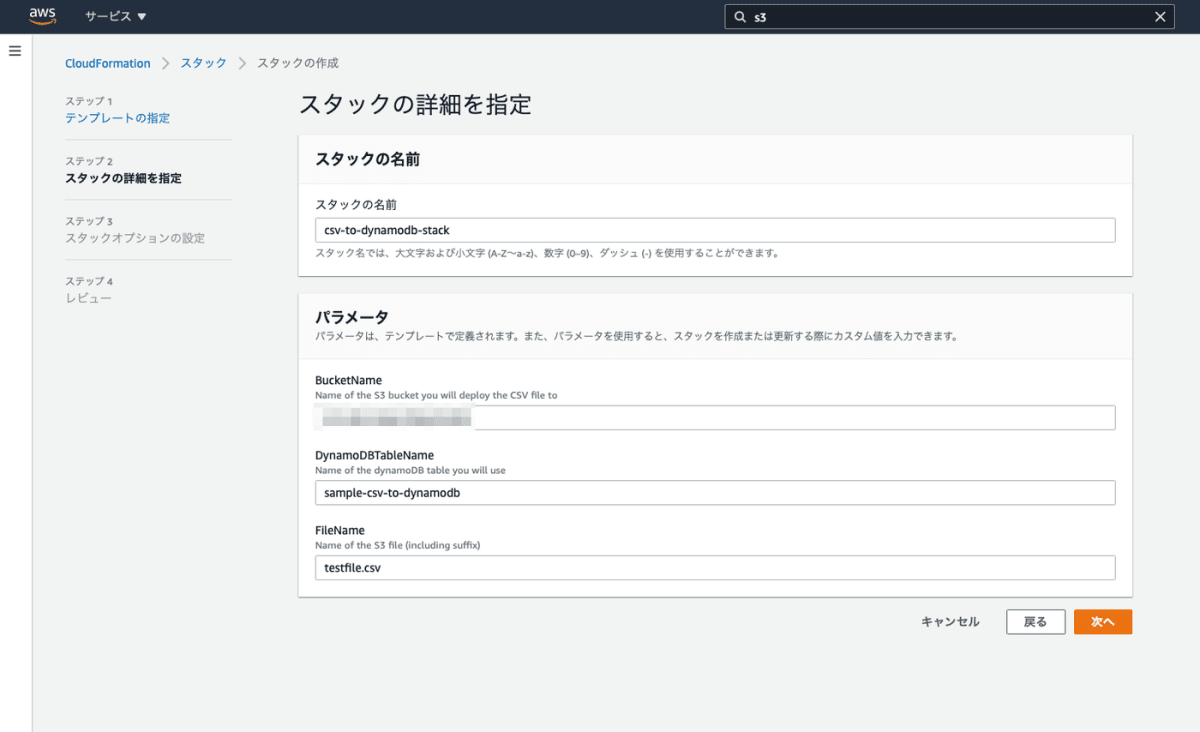
スタックを作成したら、スタック作成画面で指定したバケットのリポジトリにあるサンプル CSV をアップロードします。以下のように DynamoDB にサンプルデータが 10 万件登録されます。
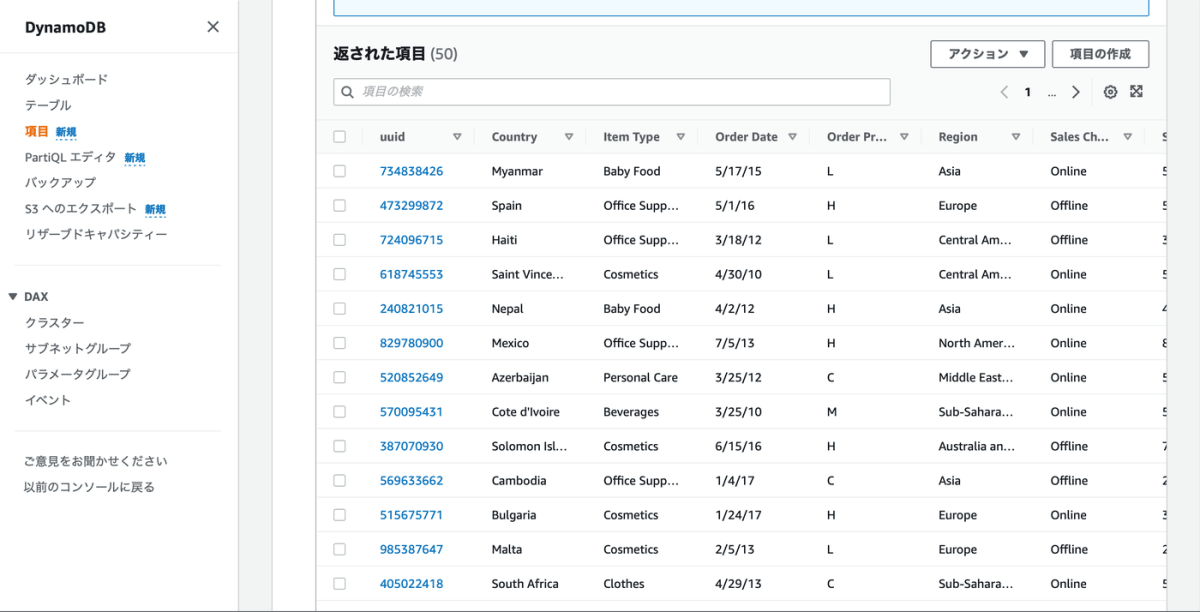
このデータを Athena のフェデレーテッドクエリを使って、クエリしてみます。
Athena のフェデレーテッドクエリを使って、DynamoDB のデータをクエリする
フェデレーテッドクエリという機能を使うことで、RDS や DynamoDB、CloudWatch Logs を SQL でクエリすることが可能となります。この機能を使って今回は DynamoDB のデータをクエリしてみたいと思います。
Athena のフェデレーテッドクエリを設定する
フェデレーテッドクエリを設定します。Athena コンソールのデータソースメニューに遷移します。データソースに接続をクリックし、DynamoDB を選択します。データソース名は任意のものを入力します。

フェデレーテッドクエリでは、Athena のクエリ実行後に Lambda を並列で起動しますので、フェデレーテッドクエリ専用の Lambda を作成する必要があります。Create New Lambda function をクリックします。Lambda コンソールに移動し AthenaDynamoDBConnector — バージョン 2021.42.1 の作成画面に遷移します。この AthenaDynamoDBConnector は AWS がオープンソースで公開しています。
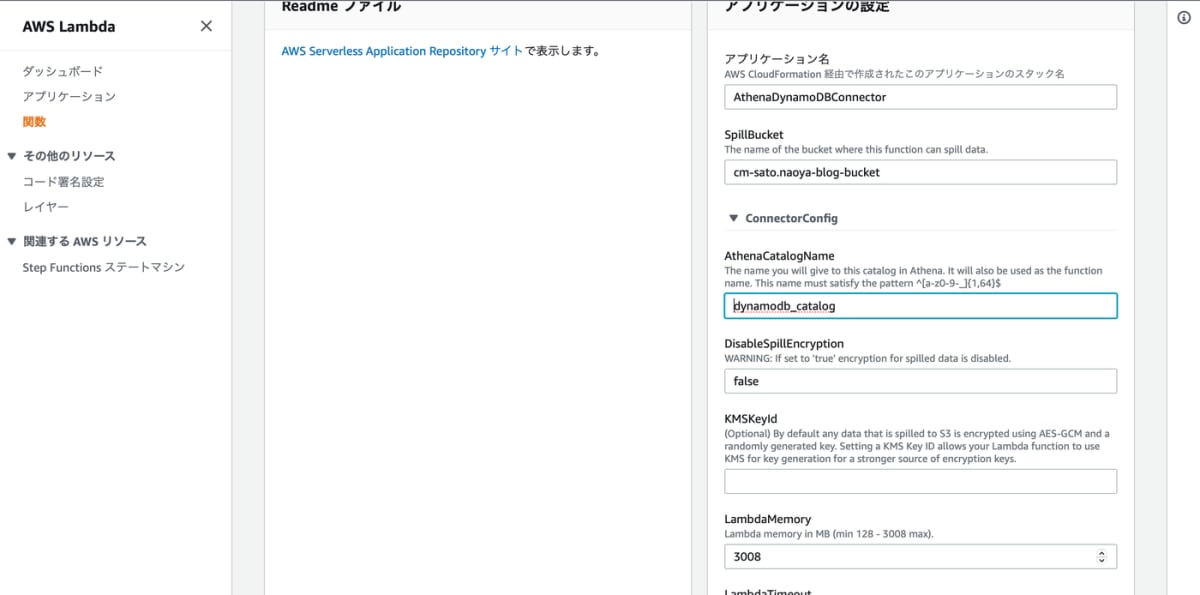
アプリケーション名、SpillBucket、AthenaCatalogName を入力します。SpillBucket というのはフェデレーテッドクエリで内部的に実行している Lambda で処理しきれなかったデータを一時的に格納しておくバケットのことです。
入力したらデプロイします。
デプロイできたら Athena のコンソールに戻り、さきほど作成した Lambda Function を選択し、データソースを作成します。作成できたら、DynamoDB のデータを Athena でクエリできるかを確認します。Athena のクエリエディターに移動し、以下のように SQL を実行します。
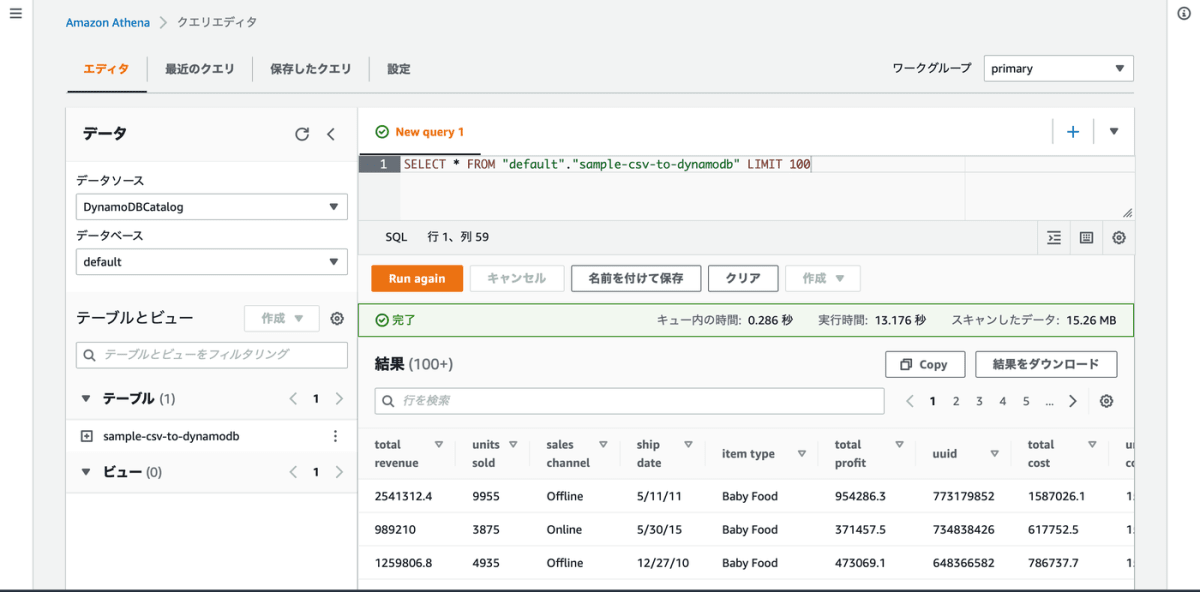
SELECT * FROM "default"."sample-csv-to-dynamodb" LIMIT 100
さきほどサンプルデータとして登録したデータを SQL でクエリできることが確認できました。また、Where で検索できます。ここまでで、DynamoDB のデータを Athena でクエリできることを確認できました。
Athena のデータをクエリし S3 からデータを取得する Web API を作成する
フロントエンドから扱いやすくするためバックエンドで Athena をクエリする Web API を作成します。API Gateway と Lambda で作ります。まずは、Lambda 関数を Node.js で作成します。
React から呼び出す用の Web API を作成します。
Athena のクエリを実行する Lambda を作成する
関数の作成をクリックし、以下のように入力し作成します。
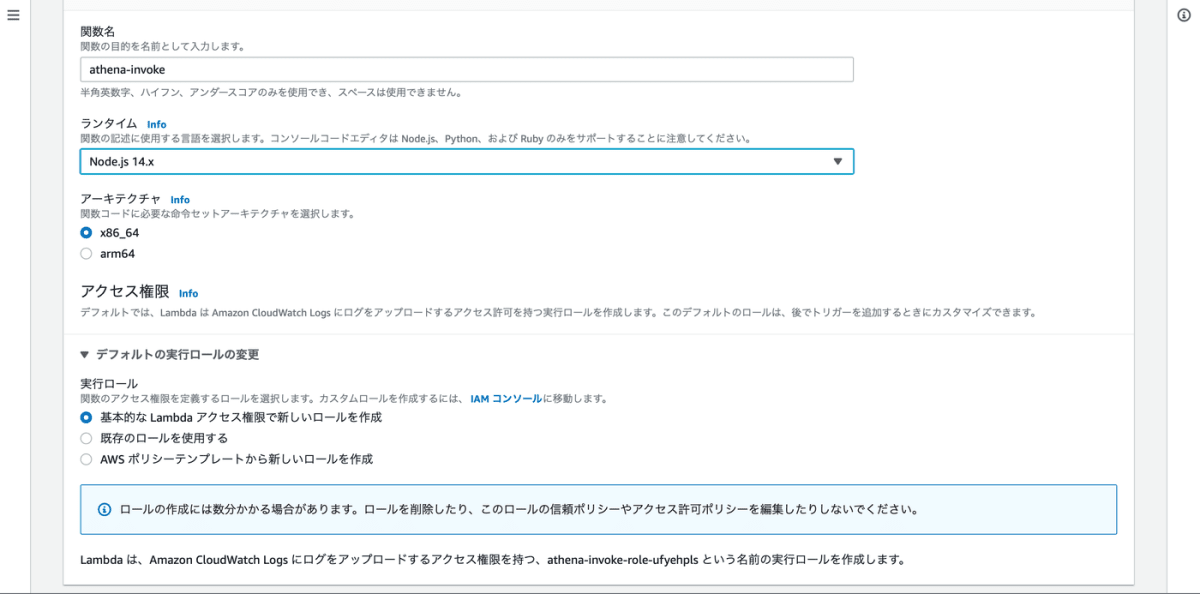
作成できたら、以下のコードを Lambda にデプロイします。Lambda から Athena 経由で DynamoDB のデータを全件クエリする SQL を実行するコードです。
const AWS = require("aws-sdk");
const athena = new AWS.Athena();
const AthenaOutputBucketName = process.env.ATHENA_OUTPUT_BUCKET_NAME;
exports.handler = async (event) => {
// DynamoDBテーブル全件取得
const sql = 'SELECT * FROM "default"."sample-csv-to-dynamodb"';
const startQueryExecutionInput = {
QueryString: sql,
ResultConfiguration: {
OutputLocation: `s3://${AthenaOutputBucketName}/result`,
},
QueryExecutionContext: {
Database: "default",
Catalog: "DynamoDBCatalog",
},
};
const startQuery = await athena
.startQueryExecution(startQueryExecutionInput)
.promise();
return {
statusCode: 202,
body: JSON.stringify({
queryExecutionId: startQuery.QueryExecutionId,
}),
};
};
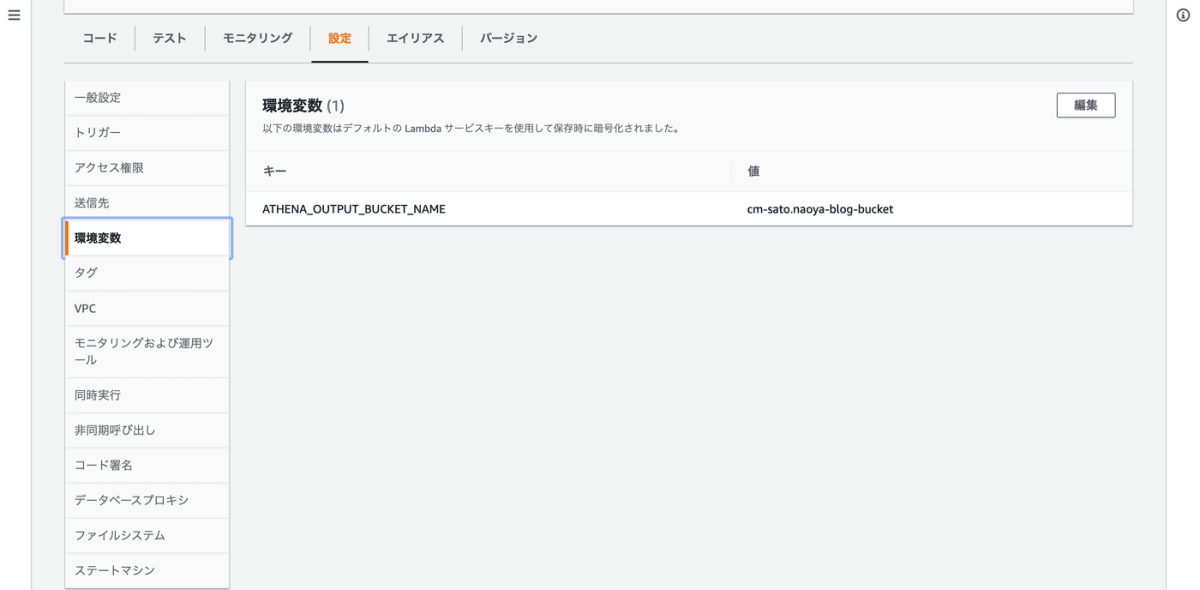
デプロイできたら、上記のコードでは環境変数を設定しているので、Lambda の環境変数に値を設定します。Lambda のコンソールの設定タブの環境変数に Athena の出力先バケット名を指定します。
Athena のクエリを実行するための Lambda に紐付いている IAM ロールに権限を付与する必要があります。Athena の実行権限、S3 の ReadWriete 権限、DynamoDB の Read 権限が必要ですが今回は Administartor 権限で実行します。実際には必要最小限の権限を付与する必要があります。Lambda の設定タブのアクセス権限から IAM コンソールを開き AdministartorAccess ポリシーをアタッチします。これで Lambda から Athena を実行する準備が整いました。実際にテスト実行して Athena のクエリを実行できるかを確認してみます。
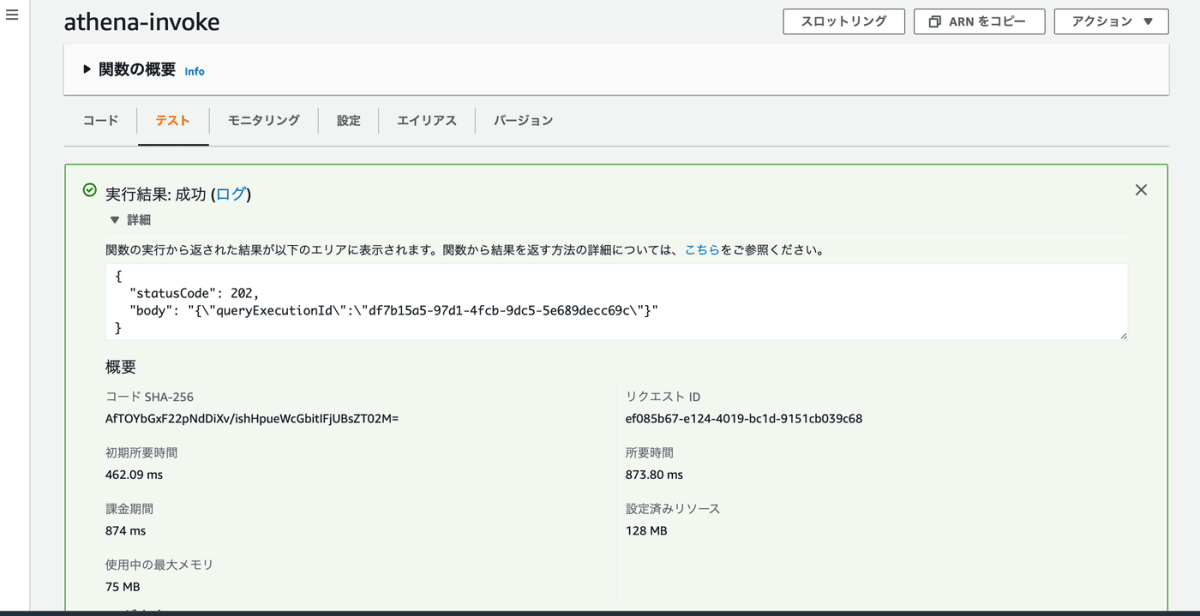
成功して、クエリ実行 ID がレスポンスで返ってくることが確認できました。良さそうです。
Athena の実行ステータスと S3 の PreSignedUrl を取得する Lambda を作成する
次に、Athena の実行結果と出力された S3 のデータの PreSignedUrl を取得する Lambda を作成します。Athena は実行が非同期で行われるため、フロントエンドなどから処理結果を確認したい場合などは実行結果を定期的に問い合わせるポーリング処理が必要になります。さきほどと同じように Lambda 関数を作成し、以下のコードを入力します。また、IAM ロールに適切な権限を付与します。
const AWS = require("aws-sdk");
const athena = new AWS.Athena();
const s3 = new AWS.S3({
signatureVersion: "v4",
});
exports.handler = async (event) => {
const getQueryExecutionInput = {
QueryExecutionId: event.queryExecutionId,
};
const getQueryExecution = await athena
.getQueryExecution(getQueryExecutionInput)
.promise();
const result = {
queryExecutionId: event.queryExecutionId,
status: getQueryExecution.QueryExecution.Status.State || "QUEUED",
};
if (
getQueryExecution.QueryExecution.Status.State === "SUCCEEDED" &&
getQueryExecution.QueryExecution.ResultConfiguration.OutputLocation
) {
// Athenaの実行が終わっていれば、S3のPreSignedUrlを取得する
const location =
getQueryExecution.QueryExecution.ResultConfiguration.OutputLocation.replace(
"s3://",
""
).split("/");
const signedUrl = await s3.getSignedUrlPromise("getObject", {
Bucket: location[0],
Key: location.slice(1, location.length).join("/"),
});
return {
...result,
signedUrl,
};
}
return {
statusCode: 200,
body: JSON.stringify(result),
};
};
テスト実行してみます。Lambda の event に queryExecutionId を指定します。以下のように Athena のステータスと Athena の実行結果が格納されている S3 の PreSignedUrl がレスポンスとして返されています。
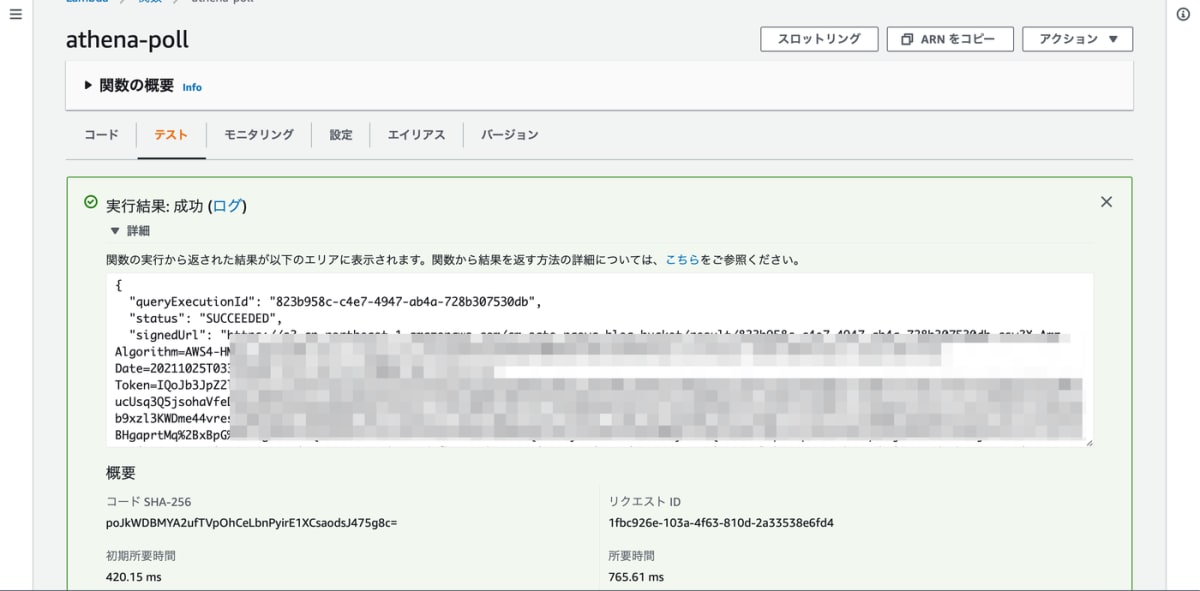
これで Lambda 関数が作成できましたので、API Gateway と紐付けてフロントエンドから呼び出せるようにします。
API Gateway の HTTP API と Lambda を紐付ける
さきほど、作成した Lambda のコンソールからトリガーを追加をクリックします。
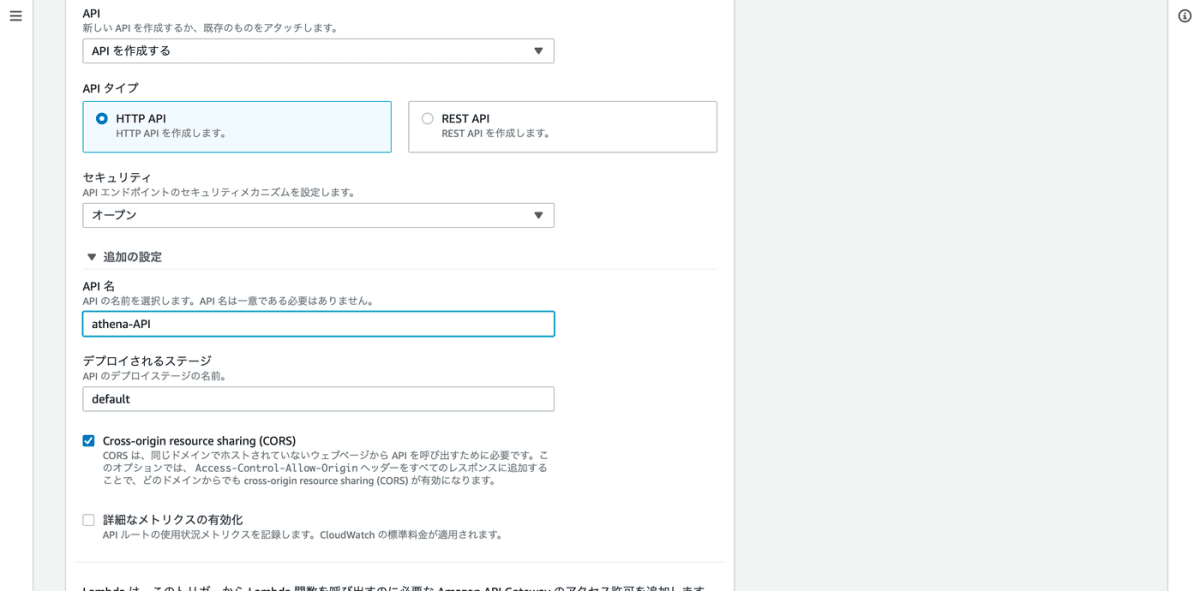
トリガーを選択から、API Gateway を選択し必要な情報を入力します。HTTP API を選択し、セキュリティはオープンを
選択、React のフロントエンドから呼び出すので CORS 設定のチェックをし追加をクリックします。
API Gateway のコンソールに移動し作成されていることを確認します。ルートが ANY で紐付いているので、ANY を削除し Invoke 関数は POST、Poll 関数は GET として紐付けます。まずは、Invoke 関数を紐付けます。API Gateway のコンソールからルートを選択し、Create をクリックします。
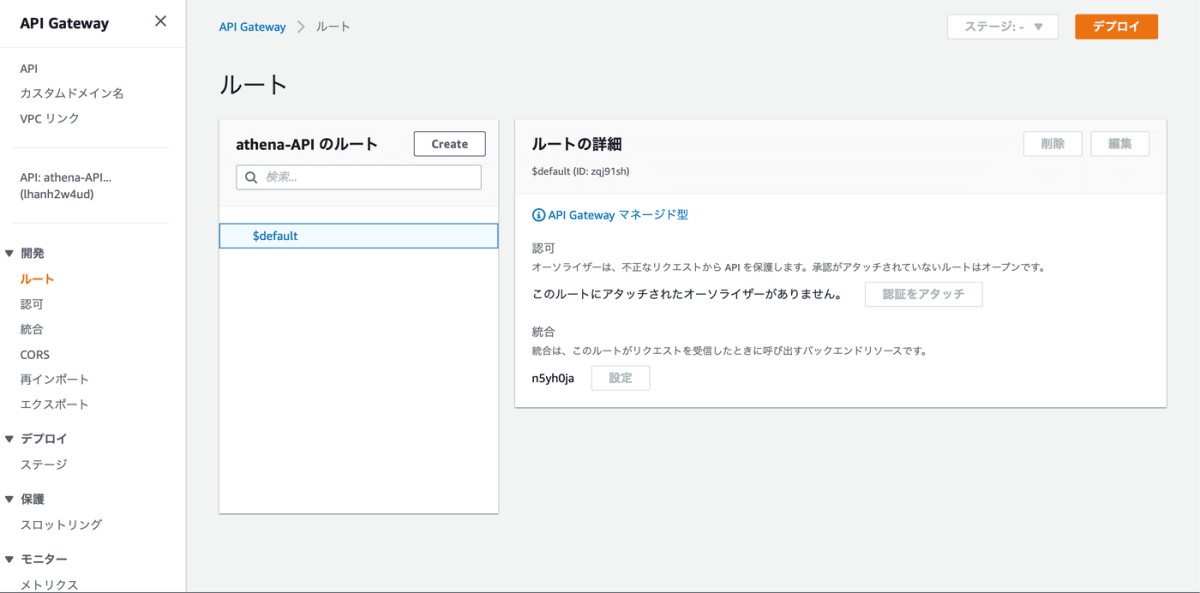
次に、POST メソッドとしてパスは /athena-invoke とし作成します。
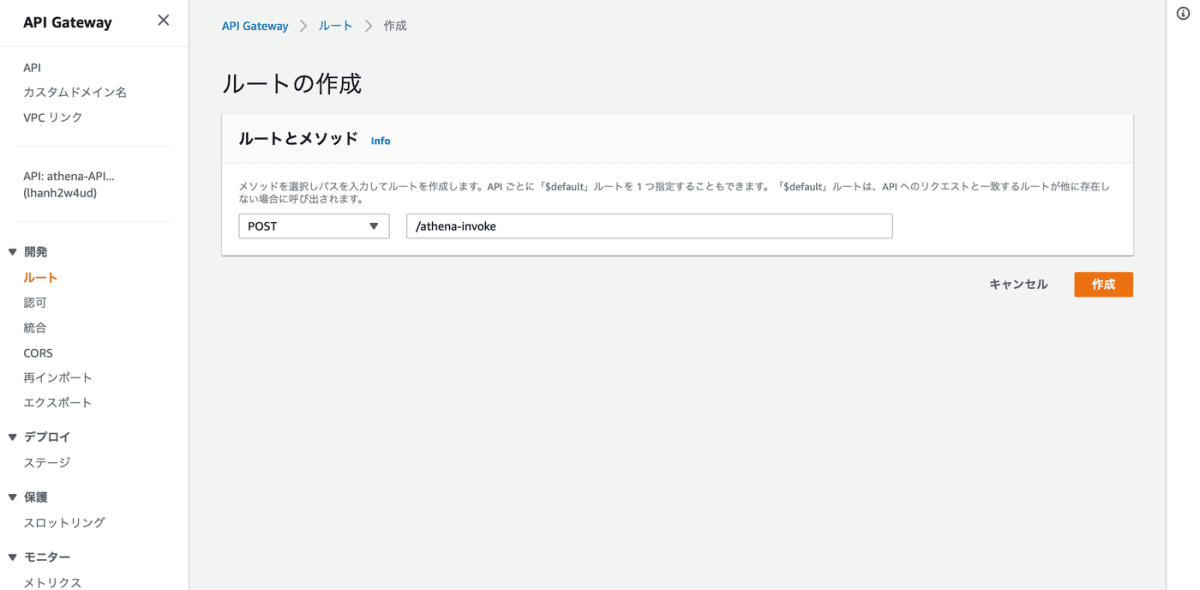
次に作成したパスの POST に対して、Lambda 統合を作成します。統合を作成するをクリックします。
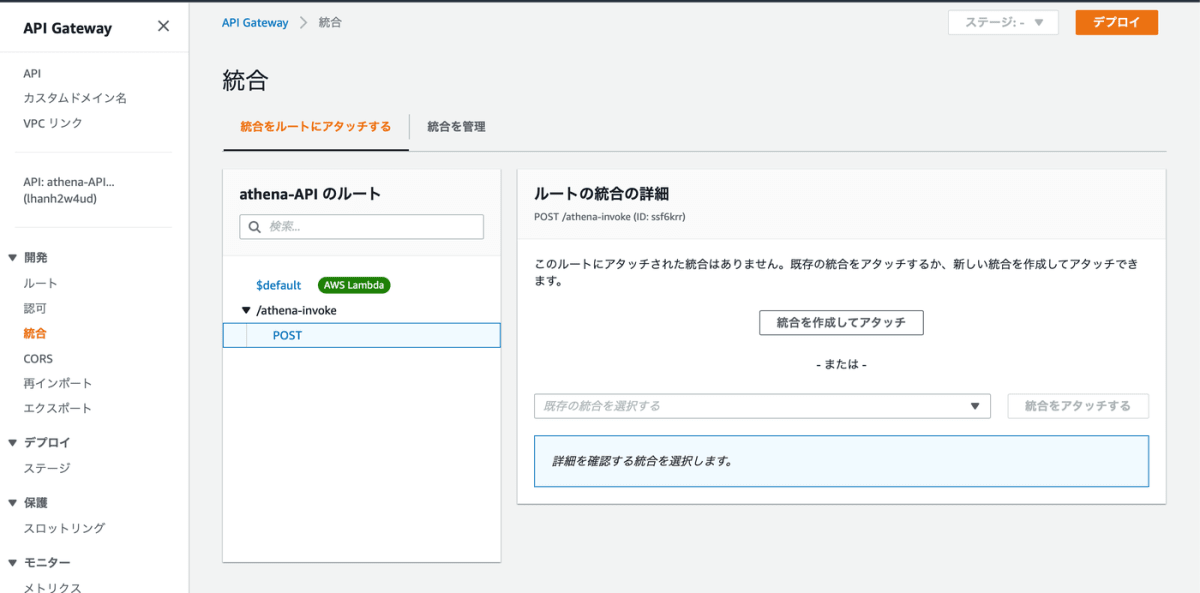
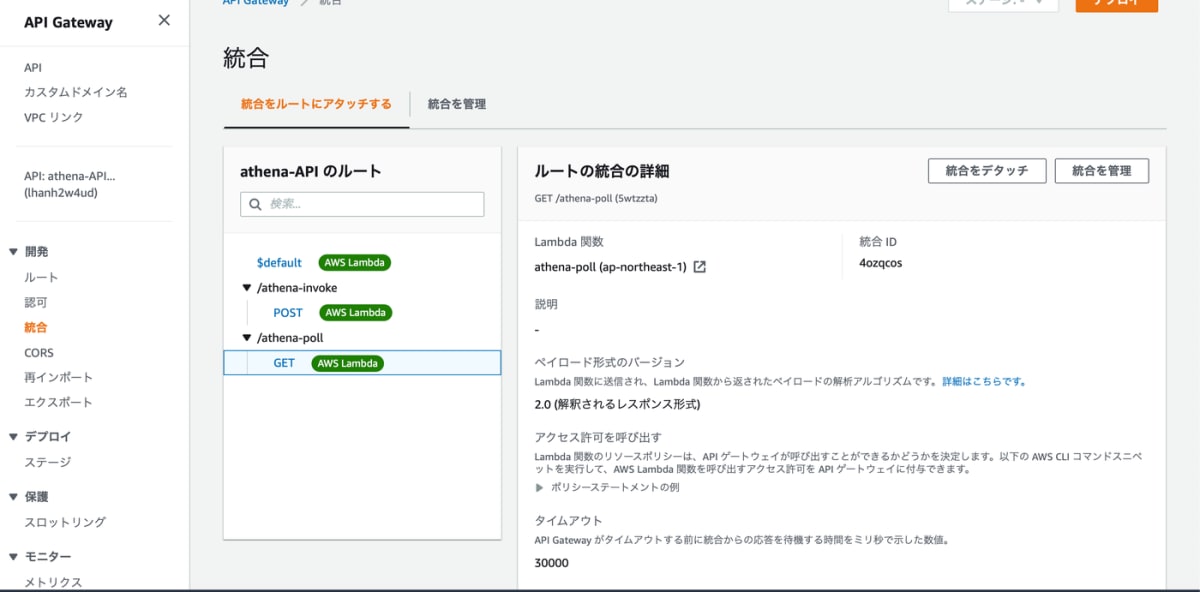
以下のように入力してさきほど作成した Lambda を紐付け作成をクリックします。

次に同じようにパスを athena-pollで GET メソッドとしてルートを作成し、athena-poll 関数を紐付けます。最終的にはルートがこの様になっています。これで、フロントエンド用の Web API の準備ができました。
React のフロントエンドを作成する
次に、ブラウザから作成した CSV ファイルをダウンロードさせるため、React のフロントエンドを作成します。今回は、Create React App を使います。
npx create-react-app dynamodb-athena-csv-download --template typescript
作成できたら、src/App.tsx を以下のように実装します。画面の CSV 出力というボタンをクリックすると、さきほど作成した Athena を invoke する API を実行します。その後 Athena の実行結果を取得する API を React からポーリングしています。実行が成功したら S3 に CSV ファイルが出力されるので、それを PreSignedUrl 経由でブラウザからダウンロードします。
import { useState } from "react";
import Axios from "axios";
import "./App.css";
import axios from "axios";
type InvokeQueryResult = {
queryExecutionId: string;
};
type PollQueryResult = InvokeQueryResult & {
status: string;
signedUrl: string;
};
// 先程デプロイした API GatewayのURLを設定します
const url = "<url>";
// ポーリングの際に指定時間待つ
function delay(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
// ポーリング
function poll<T>(
fn: () => T,
retries = Infinity,
timeoutBetweenAttempts = 1000
): Promise<T> {
return Promise.resolve()
.then(fn)
.catch(function retry(err): Promise<T> {
if (retries-- > 0)
return delay(timeoutBetweenAttempts).then(fn).catch(retry);
throw err;
});
}
// Athena Invoke APIを実行
async function invokeCsvOutput(): Promise<PollQueryResult> {
const res = await Axios.post<InvokeQueryResult>(
`${url}/athena-invoke`,
undefined,
{
headers: {
"Content-Type": "application/json",
},
}
);
// ポーリングする
return poll(() =>
pollCsvOutputStatus(res.data.queryExecutionId).then((value) => {
if (
value.status === "CANCELLED" ||
value.status === "FAILED" ||
value.status === "SUCCEEDED"
) {
return value;
} else {
// 終了系ステータス出ない場合は、catchでリトライする
throw value;
}
})
);
}
// AthenaのステータスとPreSignedUrlを取得するAPIを実行する
async function pollCsvOutputStatus(
queryExecutionId: string
): Promise<PollQueryResult> {
const res = await Axios.get<PollQueryResult>(
`${url}/athena-poll?queryExecutionId=${queryExecutionId}`,
{
headers: {
"Content-Type": "application/json",
},
}
);
return res.data;
}
function App() {
const [loading, setLoading] = useState(false);
return (
<div className="App">
<button
disabled={loading}
onClick={async () => {
setLoading(true);
const invoke = await invokeCsvOutput();
setLoading(false);
// axiosでCSVダウンロード
const res = await axios.get<any>(invoke.signedUrl, {
responseType: "blob",
});
// 動的にaタグを作成して、それを擬似的にクリックしダウンロードを実現する
const url = URL.createObjectURL(new Blob([res.data]));
const link = document.createElement("a");
link.href = url;
link.setAttribute("download", "sample.csv");
if (typeof link.download === "undefined") {
link.setAttribute("target", "_blank");
}
document.body.appendChild(link);
link.click();
setTimeout(() => {
document.body.removeChild(link);
window.URL.revokeObjectURL(url);
}, 100);
}}
>
{loading ? "出力中" : "CSV出力"}
</button>
</div>
);
}
export default App;
yarn start で Chrome で動かしてみます。すごいシンプルな CSV 出力のボタンだけが表示されます。この CSV 出力ボタンを押すと、出力中となり Athena の実行結果をポーリングします。実行が成功したらブラウザに CSV がダウンロードされます。DynamoDB の 10 万件のデータに対して全件クエリしても 10 秒程度で終了します。
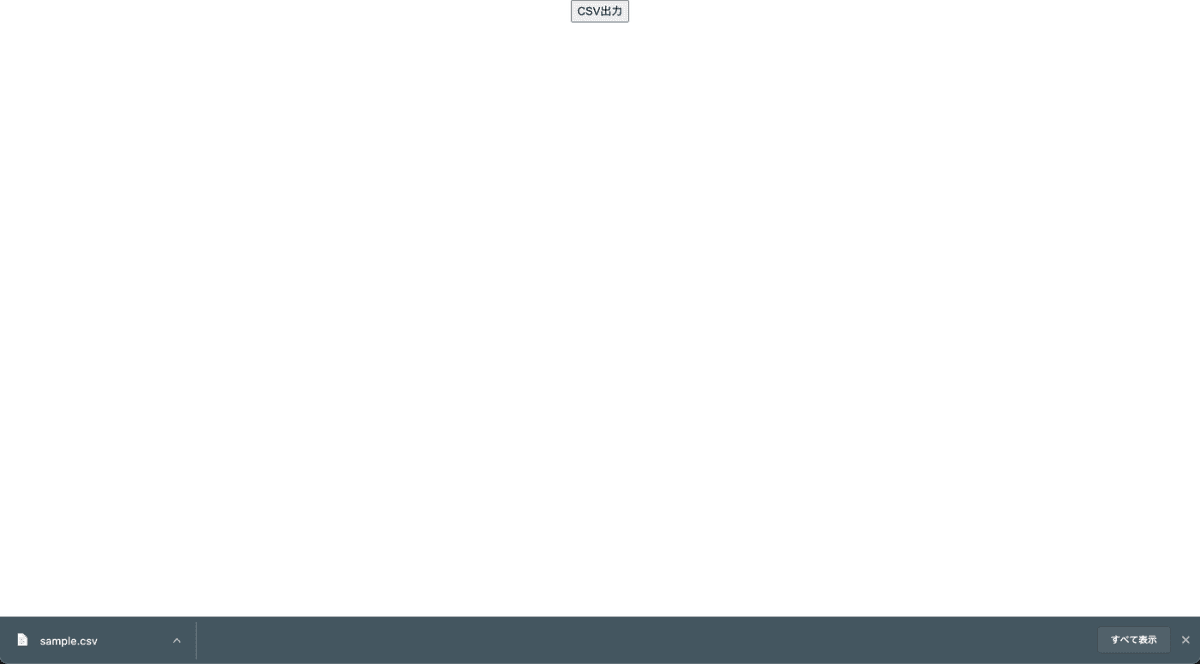
CSV を確認します。DynamoDB に格納した 10 万件のデータがダウンロードできていました。

まとめ
Athena のフェデレーテッドクエリを使って、DynamoDB のデータを CSV 出力してみました。アプリケーション側で CSV 形式に変換するようなことはしなくてよく、すべて Athena の機能で完結できます。また SQL をいじれば、たとえばカラム名を日本語にしたり、日付を YYYY年MM月DD日 にしたりなど、柔軟に CSV 形式を変更できます。
誰かの助けになれば幸いです。
Discussion
比較的扱いやすいCSVでしかもダウンロードできるのはありがたいですね!
「フェデレーテッドクエリとは」みたいな説明が最初にあるともっとっつきやすくなるかも?と思いました!
ありがとうございます!修正します