MLXと⌘R+ (Command R+)でローカルチャットbotを動かしてみた
はじめに
96GB以上のUnified Memoryを積んだApple Siliconマシーンをお持ちの人向けのニッチな記事です。
MLXを使って、話題の⌘R+ (Command R+)を使ったローカルで動作するチャットbotをクイックに作ってみました。途中で何点かつまづいたので、困っている人に届いたら嬉しいです。
以下の記事を参考にさせてもらいました。
環境
- Apple M3 MAX (128GB)
- 推論中のpythonプロセスのメモリ消費量は62GB程度でした。Unified Memory 64GBでスワップしながらギリ回るくらいですかね
- Python 3.10 (3.11, 3.12でも動作しました)
- 最初、Python 3.9環境で動かそうとしてコケました。エラーメッセージは以下の具合です。
ValueError: Received parameters not in model: model.layers.47.self_attn.q_norm.weight
(上記含む128個のパラメータ名)
ライブラリ
以下を使っています。現状(2024/04/10)、特にバージョン指定しないpipインストールで問題なく動作します。
mlx_lm
MLXはAppleが提供する機械学習(特にDeep Learning)用のフレームワークです。このフレームワーク上でモデルを動作させることで、Unified MemoryとGPUを活用し高速に学習・推論できます。mlx_lmはMLXを用いてhugging faceのLLMを動かしてくれます。
gradio
クイックにチャットbotを構築できます。
使用モデル
C4AI ⌘R+
⌘R+については色々なところで解説されているので、詳細は省略します(ぶっちゃけ色々比較して語れるほど知見はないです)。商用利用は制限されているので留意してください。
今回は、MLX用に4bit量子化済みのモデルを利用しました。
コマンドラインで動作チェック
mlx_lmをインストールした仮想環境をactivateし、ターミナル以下を打つとモデルが動作します。
python -m mlx_lm.generate --model mlx-community/c4ai-command-r-plus-4bit --prompt "名古屋について解説して" --temp 0.0 --max-tokens 500 --use-default-chat-template
以下の通り、かなり流暢に回答してくれました。(微妙な誤りはありますが)
Prompt: <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>名古屋について解説して<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
名古屋は、日本の本州の中部地方に位置する都市です。愛知県の県庁所在地であり、東京、横浜、大阪に続く日本第 4 の都市圏です。名古屋は、その長い歴史、文化、独特の料理、活気ある都市環境で知られていて、国内外の観光客に人気の旅行先となってます。
名古屋の歴史は 16 世紀にさかのぼり、織田信長の拠点として栄えました。名古屋城は 1612 年に徳川家康によって建てられ、この地域の政治的中心地となりました。第二次世界大戦で大きな被害を受けた後、名古屋は復興し、日本の主要工業都市および商業センターとして発展しました。
名古屋は、そのランドマークである名古屋城で有名です。この城は、その壮大な規模と金鯱(金色の虎の頭を持つ神話上の生き物)で知られていて、名古屋の最も重要な観光名所の 1つです。名古屋城は国の特別歴史的建造物に指定されており、内部には博物館があり、日本の歴史と文化に関する展示が行われてます。
名古屋は、活気ある食文化でも知られてます。名古屋めしと呼ばれる独特の料理は、味噌カツ、手羽先、ひつまぶし(うなぎの炊き込みご飯)など、味噌ベースの料理で有名です。名古屋は、日本の自動車産業と密接な関係があることでも知られていて、豊田市の近くにあるため、多くの自動車メーカーの本社があります。
名古屋は、近代的な都市環境と伝統的な文化が融合してます。栄や錦などの繁華街には、高級なショップ、ダイニング、ナイトライフが集まり、活気ある雰囲気を醸し出します。一方、熱田区や大須などの歴史的な地区では、伝統的な神社や寺院、昔ながらの市場を見ることができます。
名古屋は交通の拠点でもあり、新幹線や高速道路で東京や大阪などの他の主要都市と接続されてます。名古屋は、その文化、歴史、料理、活気ある都市環境を体験できる、探索するのに最適な場所です。この都市は、日本を訪問する旅行者にとって人気の旅行先となってます。
要約すると、名古屋は日本の中部地方に位置する活気ある都市です。その歴史、
==========
Prompt: 12.937 tokens-per-sec
Generation: 4.448 tokens-per-sec
チャットbotをクイックに
前のステップでモデルの動作確認もでき、結構いい回答をしてくれることがわかったので、普段使いできるよう最低限のチャットbotを作ってみました。
定番はStreamlitあたりかなと思うのですが、クイックに作るにはダルイので、Claude 3 Opusに相談したところ、gradioを提案してくれました。(本当はこれも⌘R+が回答してくれたら嬉しかったですが。。。)
チャットbotのコードは以下のとおりです。
import gradio as gr
from mlx_lm import load, generate
model_name = "mlx-community/c4ai-command-r-plus-4bit"
model, tokenizer = load(model_name)
def generate_response(input_text):
start_token = "<BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>"
end_token = "<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>"
prompt = start_token + input_text + end_token
response = generate(
model, tokenizer, prompt,
max_tokens=512,
verbose=True
)
return response
gr.Interface(fn=generate_response, inputs="text", outputs="text").launch()
上記を実行すると、以下のようにチャットbotが起動し、プロンプトに応答してくれます。
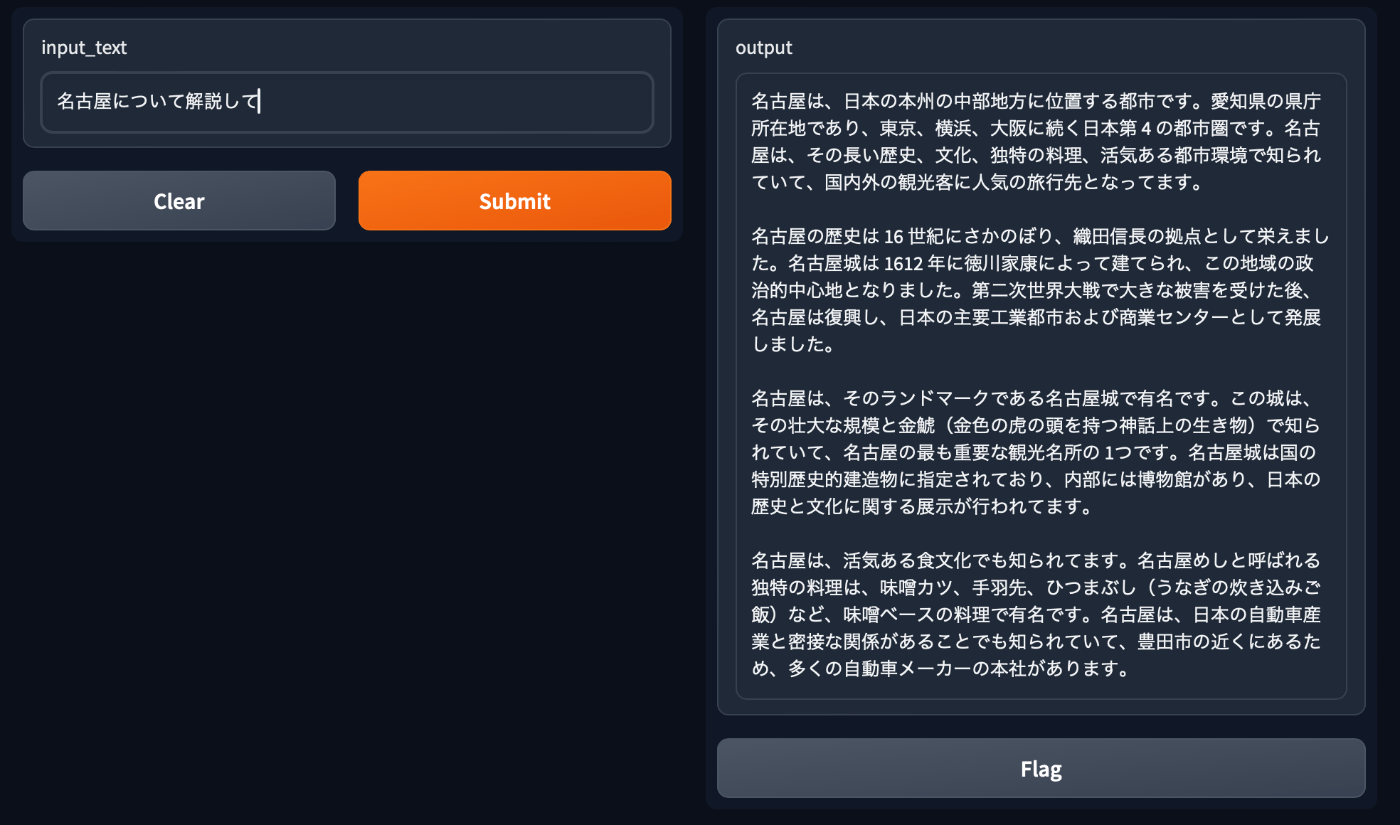
コードの注意点
上記のコードのポイントについて補足します。
mlx_lmでの⌘R+のサンプルに従って動かすと、支離滅裂な回答をします。
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/c4ai-command-r-plus-4bit")
response = generate(model, tokenizer, prompt="hello", verbose=True)
Prompt: hello
,
I have a problem with the "グリーン" color.
I have a "green" color in my palette, but when I use it, it is not the same color.
I have a "green" color in my palette, but when I use it, it is not the same color.
グリーン
グリーン
グリーン
グリーン
I have a "green" color in my palette, but when I use it, it is not the same color.
I have a
==========
Prompt: 2.012 tokens-per-sec
Generation: 4.466 tokens-per-sec
原因を探ってみると、元のモデルカードに答えがありました。
# Format message with the command-r-plus chat template
messages = [{"role": "user", "content": "Hello, how are you?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
要は、テンプレートを使うためには、
- 特殊トークン
<BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>をプロンプトの頭に付与し - 特殊トークン
<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>をプロンプトの末尾につけろ
ということです。そのため、上記のapp.pyではstart_token, end_tokenを定義し、プロンプトに追加するようにしています。
おわりに
ローカルでここまでのレベルの回答を、使えるレベルのスピードで出力してくれるのは痺れますね。ここまで賢いなら、本来のトークン長の強みを活かした応用もどんどん試したいです。
Discussion