Llama 3とApple MLXでローカルチャットbotを動かしてみた
はじめに
リリースされたばかりのLlama 3をMLXを使ってローカルのMacBook Proで動かして遊んでみました。
前回の⌘R+ (Command R+)と同様、ローカルで動作するチャットbotをクイックに作ってみました。今回もやはり途中で何点かつまづいたので、困っている人に届いたら嬉しいです。
環境
- Apple M3 MAX (128GB)
- 推論中のpythonプロセスのUnified Memory消費量はざっくり最大で以下のとおりでした
- 8B 4bit : 7.5GB
- 8B 8bit : 10GB
- 70B 4bit : 39GB
- 70B 8bit : 70GB
- なお、後述しますが70B 4bitはいまのとこまともに動作しないです
- 推論中のpythonプロセスのUnified Memory消費量はざっくり最大で以下のとおりでした
- Python 3.10
- 前回の記事のとおり、3.9以前では動作しないと思われます
ライブラリ
以下を使っています。現状(2024/04/20)、特にバージョン指定しないpipインストールで問題なく動作します。
mlx_lm
MLXはAppleが提供する機械学習(特にDeep Learning)用のフレームワークです。このフレームワーク上でモデルを動作させることで、Unified MemoryとGPUを活用し高速に学習・推論できます。mlx_lmはMLXを用いてhugging faceのLLMを動かしてくれます。
gradio
クイックにチャットbotを構築できます。
使用モデル
Meta Llama3
言わずと知れたOpen-AccessなLLMの先駆け、Llamaの最新バージョンです。8Bモデルで先代の70B相当の性能が出て、3の70Bモデルは英語性能でGPT4に匹敵するそうです。
今回は、8BモデルについてはMLX用に量子化されたモデルを利用しました。
また、70Bモデルについては動くMLX版が共有されていなかったので、私で量子化し、HuggingFaceで共有しました。
コマンドラインで動作チェック
とりあえず、8Bモデルで遊んでみましょう。mlx_lmをインストールした仮想環境をactivateし、ターミナル以下を打つとモデルが動作します。
python -m mlx_lm.generate --model mlx-community/Meta-Llama-3-8B-Instruct-8bit --prompt "トランジスタについて解説して" --temp 0.0 --max-tokens 500
以下の通り、なぜか英語で回答してきました。ただ、動作確認はできたので次のステップに移ります。
Prompt: <|begin_of_text|><|start_header_id|>user<|end_header_id|>
トランジスタについて解説して<|eot_id|><|start_header_id|>assistant<|end_header_id|>
A great topic! 📊
A transistor is a type of semiconductor device that plays a crucial role in modern electronics. It's a fundamental component in many electronic circuits, and its invention revolutionized the field of electronics. In this explanation, I'll cover the basics of transistors, their types, and their applications.
**What is a transistor?**
A transistor is a three-layer semiconductor device that consists of two types of materials: p-type (positive) and n-type (negative). The p-type material has an excess of holes (positive charge carriers), while the n-type material has an excess of electrons (negative charge carriers). The layers are typically referred to as the base, collector, and emitter.
**How does a transistor work?**
A transistor works by controlling the flow of current between the collector and emitter terminals. The base terminal is used to control the flow of current by injecting or removing charge carriers. Here's a simplified explanation of the transistor's operation:
1. **Base-Emitter Junction**: When a small current is applied to the base terminal, it creates a flow of charge carriers (holes or electrons) across the base-emitter junction.
2. **Collector-Emitter Junction**: The flow of charge carriers from the base-emitter junction creates a flow of current between the collector and emitter terminals.
3. **Amplification**: By controlling the base current, the transistor can amplify or switch the current flowing between the collector and emitter terminals.
**Types of transistors**
There are two main types of transistors: Bipolar Junction Transistors (BJTs) and Field-Effect Transistors (FETs).
1. **Bipolar Junction Transistors (BJTs)**: BJTs use both holes and electrons as charge carriers. They are further divided into two subtypes:
* **NPN Transistors**: Have a p-type base, an n-type collector, and an n-type emitter.
* **PNP Transistors**: Have a p-type base, a p-type collector, and an n-type emitter.
2. **Field-Effect Transistors (FETs)**: FETs use a voltage applied to a control electrode (gate) to create a flow of current between the source and drain terminals. There are two main types of FETs:
* **Metal-Oxide-Semiconductor Field-Effect Transistors (MOSFETs)**: Use a metal
==========
Prompt: 105.886 tokens-per-sec
Generation: 41.829 tokens-per-sec
チャットbotをクイックに
前の記事と同様、クイックにチャットbotを作ってみました。
チャットbotのコードは以下のとおりです。
import gradio as gr
from mlx_lm import load, generate
model_name = "mlx-community/Meta-Llama-3-8B-Instruct-8bit"
model, tokenizer = load(model_name)
def generate_response(input_text):
response = generate(
model, tokenizer, input_text,
max_tokens=512,
verbose=True
)
return response
gr.Interface(fn=generate_response, inputs="text", outputs="text").launch()
上記を実行すると、以下のようにチャットbotが起動し、プロンプトに応答してくれます。

70Bモデルを動かす
次に、英語においてGPT4並の性能を示すという70Bモデルを動かしてみました。70Bモデルは量子化なしでは動かないため、mlx-communityにアップロードされている4bit量子化モデルで遊んでみることにしました。
しかし・・・
python -m mlx_lm.generate --model mlx-community/Meta-Llama-3-80B-Instruct-4bit --prompt "トランジスタについて解説して" --temp 0.0 --max-tokens 500
Prompt: トランジスタについて解説して
\\\\\\ of\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ the<|begin_of_text|>. and and the. and the in the. and the in the.
.
and he in the he and he in the he.
the he and he in the he and he in the he и he и he и и he и и he и he и и he и he и и he и и и he и и he и и и и и и и и и и и и и и и и и и и и и и и и и и и и и and he it и и и и и и и и и and he it in the he и и и и he and it he и и he it in the he и и и and he it in the he и in the he и и and he it in the he и in the he и in the he и in the he it in the he and it in the he и in the he it in the he и in the he it in the he и in the he it in the he he it in the he it in the he и in the he it in the he it in the he and it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in the he it in
このとおり、ゴミしか出力されませんでした。huggingfaceのmlx-communityでも同様なバグが報告されており、4bit量子化がうまく機能していないようです。
では8bit量子化だと奮い立ちましたが、mlx-communityには70Bの8bit量子化モデルがありません。そのため、以下の手順で頑張って量子化し、mlx-communityにアップロードしました。
- Llama3 70B利用の認証を受ける(このページに申請フォームがあるので、入力してしばらくすると認証してもらえます https://huggingface.co/meta-llama/Meta-Llama-3-70B)
- communityに参加する(画像参照)
- 以下のコマンドで、量子化を行いつつ、communityにモデルをアップロード(mlx-communityのトップページにスニペットがあります)
python -m mlx_lm.convert --hf-path meta-llama/Meta-Llama-3-70B-Instruct --q-bits 8 -q --upload-repo mlx-community/Meta-Llama-3-70B-Instruct-8bit
アップロード先は以下となっています。
app.pyのモデルをmlx-community/Meta-Llama-3-70B-Instruct-8bitに書き換えて動かしてみたところ、下のようにいい感じに動作してくれました。
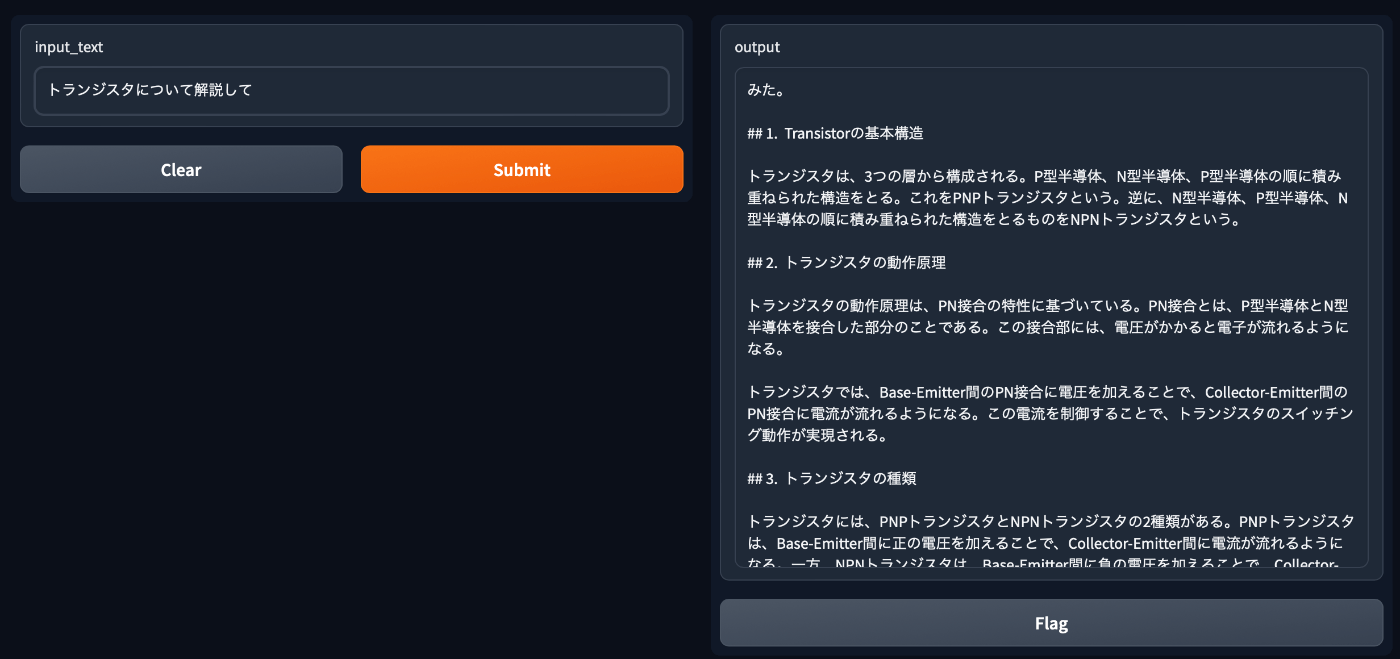
おわりに
日本語の使用感は⌘R+のほうが良さげです。
今回は70BモデルをMLX用に8bit量子化し、共有したということで、OSSに微力ながら初めて貢献できたのは良い経験になりました。
2024-04-21追記
70B 4bit量子化の不具合について、修正がなされたようです。
Discussion