こんにちは。バンダイナムコネクサス 上田です。
前回に引き続き、広告出稿のKPI最大化のためのデータ基盤開発について紹介します。
対象読者はデータ基盤新規開発プロジェクト立ち上げに将来携わるエンジニア、PM、ビジネスサイドのメンバー全員を想定し、これから広告関連のデータを触る予定のエンジニアやPMはもちろん、広告関連のデータに関わりのない方、非エンジニアの方にとっても有益な情報となることを願います。
記事に書いてあること
前回までの記事
前回の第2章では
「1. 出稿している広告のデータを毎日収集し、利用しやすく整える」
「2. 出稿している広告の実績レポートを自動で作成し、広告運用者がいつでも参照できる状態にする(データの民主化推進)」
を実現するためのデータパイプライン開発を紹介しました。
今回の記事
今回は第2章の記事の中で登場した「Airflowコードを型化した」を次の流れで紹介していきます。
- データの流れ
- 開発のポイント
- データの洗い替えのロジックの紹介
- Airflowで行っている処理の概要
- 各タスクの詳細
データの流れ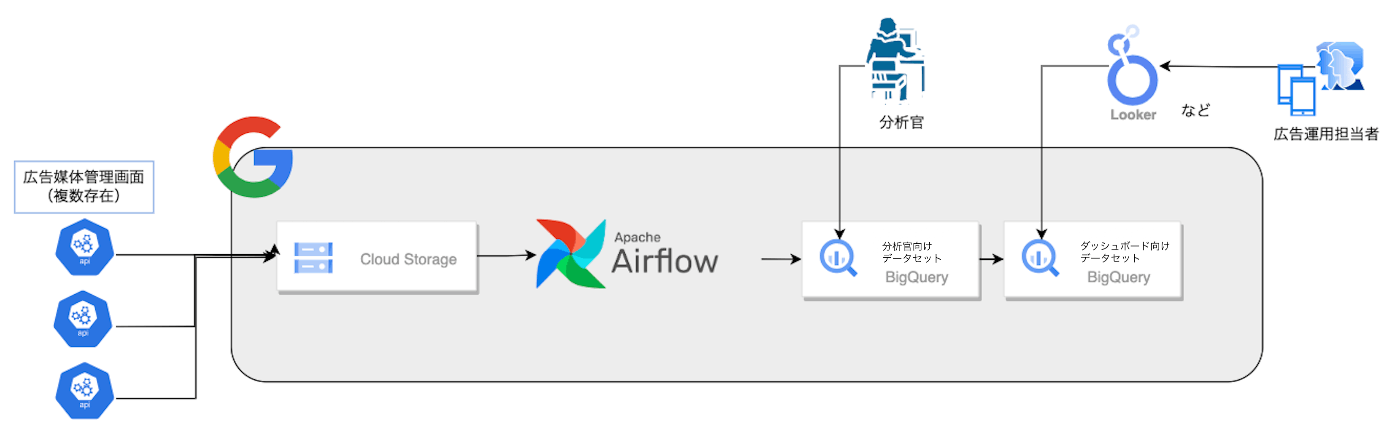
- 収集したデータをそのままCloud Storageに保存します。
- Airflow(正しくはCloud Composer。Cloud ComposerはApache Airflowで構築されています。)でBigQueryに格納します。 ←話すのはここ
- BigQueryに格納したデータを参照するLookerダッシュボードを作成することで、非エンジニアである広告運用担当者もデータを確認することができます。
実績値は安定するまでに時間がかかるので、一定期間(例えば35日間)で洗い替えを行います。
一定期間経過後までは毎日古いデータをなくし、新しく取得した最新のデータを作成します。
データの洗い替えのロジックの紹介
タスクの内容を説明する上で必要なので、データの洗い替えのロジックを紹介します。
まず作成するデータの一部のカラムの説明をします。
- report_date: 実績の日付
- get_report_date: データがGCSに格納された日付
- created_at: Airflowの処理を開始した時刻
今回は35日間洗い替えを行う想定で説明していきます。
例えばreport_date: 2023/1/1のデータの場合、get_report_date: 2023/2/5まで毎日最新のデータに洗い替えするという設計です。

詳しく説明すると次の手順となります。
- 実行のたびに新しい空のテーブル
{tmp_dataset}.{sink_table}を作成し、新しいデータを投入します。 - 現在使用されている分析官向けテーブル
{dwh_dataset}.{sink_table}を一度空にして、必要なデータだけを投入します。- 最も新しく取得したデータに洗い替えます。
- 新しいデータに存在しないデータは残します。
Airflowで行っている処理の概要
弊社では現在、14種類のデータパイプラインが稼働中ですが、ロジックは型化しており、Airflowのtaskの構造は基本的に一緒です。

各タスクの詳細
Airflowで行っている処理の概要に示した画像のtaskの一部を詳しく説明します。
エンジニアの方も読むことを想定しているので、一部コードも掲載します。
create_(raw_)dataset, create_(raw_)table_if_not_exists
必要なデータセット、テーブルを作成します。
すでに存在する場合には、既存のデータセット、テーブルをそのまま使用します。
今回「新しいデータを投入するテーブル」と「現在ユーザーが参照しているテーブル」の2つが必要です。
truncate_raw_table
{tmp_dataset}.{sink_table}を空にします。
「作成したばかりのテーブルは空なのでこの処理はいらないのでは?」と思うかもしれません。しかし必要なテーブルがすでに存在した場合には、テーブルが空ではない可能性もあるため必要な処理です。
truncate_raw_table = BigQueryExecuteQueryOperator(
task_id="truncate_raw_table",
sql="truncate_raw_table.sql",
use_legacy_sql=False,
location="asia-northeast1",
)
insert_bq_raw_table_task
PythonOperatorというPythonに記載した処理を行うtaskです。
PythonではGCSのファイルを取得し、使いやすい形に整形し、BigQueryの{tmp_dataset}.{sink_table}に格納する処理を書いています。
insert_bq_raw_table_task = PythonOperator(
task_id="insert_bq_raw_table_task",
provide_context=True,
templates_dict={"TARGET_DATE": {TARGET_DATE}"},
python_callable=insert_bq_raw_table,
)
TARGET_DATEは、今日格納されたGCSのデータを取得するようにPythonコード内で使用する日付でconfig.pyに記載しています。
insert_unique_data
データの洗い替えのロジックの紹介に記載したデータを抽出するクエリinsert_unique_data.sqlの結果を{dwh_dataset}.{sink_table}にinsertします。
write_dispositionにWRITE_TRUNCATEを指定し、今回insertしたデータだけが残るようにします。
insert_unique_data = BigQueryExecuteQueryOperator(
task_id="insert_unique_data",
sql="insert_unique_data.sql",
destination_dataset_table="{PROJECT_ID}.{DWH_DATASET}.{SINK_TABLE}"
write_disposition="WRITE_TRUNCATE",
allow_large_results=True,
use_legacy_sql=False,
location="asia-northeast1",
)
delete_tmp_table
insert_bq_raw_table_taskで{tmp_dataset}.{sink_table}に格納したデータは不要になったのでテーブルを削除する。
delete_tmp_table = BigQueryDeleteTableOperator(
task_id="delete_tmp_table",
deletion_dataset_table="{PROJECT_ID}.{TMP_DATASET}.{SINK_TABLE}",
)
おわりに
次回はエンジニア向けに今回紹介した「Airflowコードを型化した」をより深く、サンプルコードを含め記事にまとめようと思います。
最後まで読んでいただきありがとうございました!

Discussion