こんにちは。バンダイナムコネクサス 上田です。
前回に引き続き、広告出稿のKPI最大化のためのデータ基盤開発について紹介します。
対象読者はデータ基盤新規開発に将来携わるエンジニアを想定し、これから広告関連のデータを触る予定の方、Airflowで開発予定の方々にとって有益な情報となることを願います。
記事に書いてあること
前回までの記事
第3章ではAirflowコードをできる限り型化して広告データパイプラインを開発したことを紹介しました。
今回の記事
今回は、第3章で触れた「Airflowコードを型化した」件についてをエンジニア向けにより深く、サンプルコードを含め今後エンジニア向けに次の流れで紹介していきます。
- データの流れ
- 開発のポイント
- Airflowで行っている処理
- Airflowタスクの詳細
データの流れ
前回と内容が重複しますが、データの流れをおさらいします。

- 収集したデータをそのままCloud Storageに保存します。
- Airflow(正しくはCloud Composer。Cloud ComposerはApache Airflowで構築されています。)でBigQueryに格納します。 ←話すのはここ
- BigQueryに格納したデータを参照するLookerダッシュボードを作成することで、非エンジニアである広告運用担当者もデータを確認することができます。
実績値は安定するまでに時間がかかるので、一定期間洗い替えを行います。
開発のポイント
-
再実行しても同じ結果となるように設計します。
- 同じ日に何度実行しても同じ結果となる設計にすることで、不測の事態の対応が簡単になります。
-
コード内で使用する日時はAirflowのTemplates referenceを使用します。
- https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
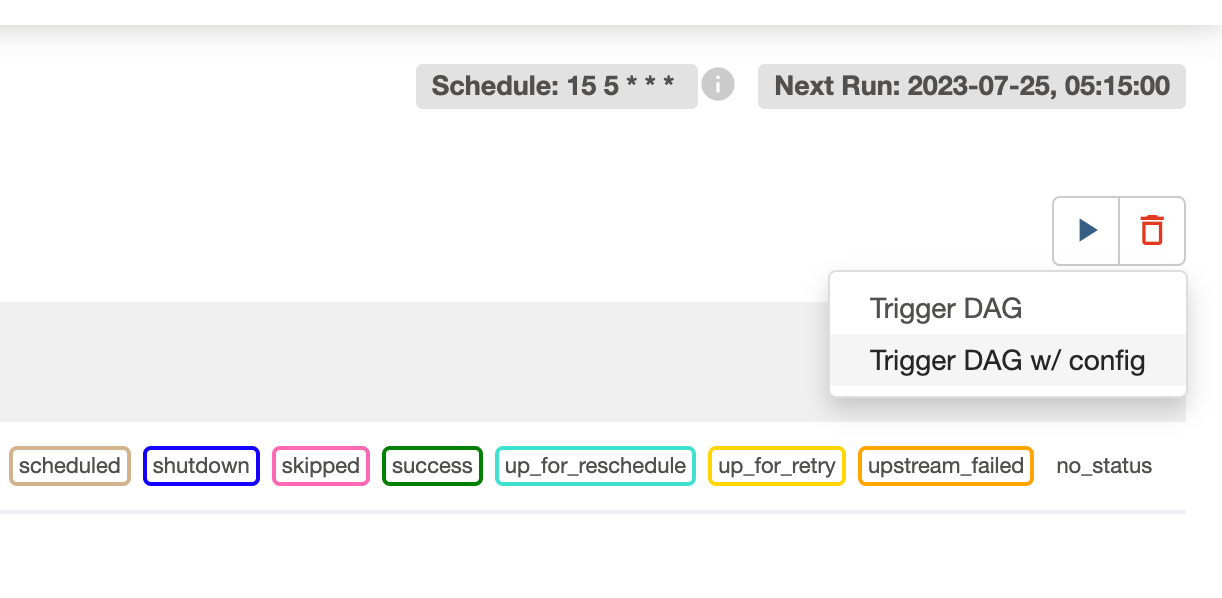
- このメリットは過去の日付のLogical dateを指定して、過去の日付の状態で(過去に行われた or 過去に行われるはずだった)実行をGUIからすることができることです。再実行の工程は以下の通り簡単なのでエンジニア以外の担当者も実行可能です。
-
各dagの画面から「Trigger DAG w/ config」をクリック
-
Logical dateを指定して「Trigger」をクリック

-
-
格納先データセットの命名規則を設けています。
- 命名規則によってデータセットの役割が想像しやすくなります。データ作成者と利用者の誤解が生じないように工夫しています。
-
エラーが発生した場合の通知先を必要に応じて振り分けています。(第1章で紹介)
Airflowで行っている処理
14種類のデータパイプラインが現在稼働中ですが、ロジックは型化しており、Airflowのtask構造は一緒です。

Airflowタスクの詳細
<config.py>
class AdDataConfig:
# 全媒体で使用する項目
DWH_DATASET = "dataset_name1"
TMP_DATASET = "dataset_name2"
TARGET_DATE = "{{ macros.ds_format(data_interval_end.in_tz('Asia/Tokyo') | ds , '%Y-%m-%d', '%Y/%m/%d') }}" # データがGCSに格納された日付
class { 媒体名 }:
# それぞれの媒体で使用する項目
SINK_TABLE = "sink_table_name"
BAITAI = "baitai_name"
REPORT_TYPE = "report_type"
全媒体で使用する項目とそれぞれの媒体で使用する項目をconfig.pyに記載します。
必要に応じてサブクラスを使用してください。
<dagの設定>
@dag(
schedule_interval="15 5 * * *",
start_date=pendulum.datetime(2022, 12, 14, 13, 40, tz="Asia/Tokyo"),
default_args={
"retries": 1,
"retry_delay": timedelta(minutes=5),
"on_failure_callback": some_task_failed,
'depends_on_past': True,
},
user_defined_macros=user_defined_macros,
catchup=True,
max_active_runs=1,
tags=["ad_data"],
)
- schedule_interval: cron形式で記載します。例では毎日5:15に実行するように記載しました。
- start_date: catchup=Trueとなっている場合にはstart_dateをもとに過去の未実行taskから実行されます。
- on_failure_callback: どこかのtaskでこけた場合の通知です。以下で紹介する「check_bucket_object_exists」taskのように別途task内で指定している場合にはそちらが優先されます。
- depends_on_past: Trueの場合には、taskが失敗しているとそれより未来のtaskが保留になります。
- tags: 複数のプロジェクトが走っている場合やtestも同じ管理下の場合には指定しておくとGUIで表示した時見やすいかと思います。
<check_bucket_object_exists>
check_bucket_object_exists = GCSObjectsWithPrefixExistenceSensor(
task_id="check_bucket_object_exists",
bucket=AdDataConfig.SOURCE_BUCKET,
prefix=SOURCE_FILE_PREFIX,
timeout=60,
on_failure_callback=gcs_file_not_found,
google_cloud_conn_id="google_cloud_default",
)
毎日GCSに取得したデータを格納しています。
該当のデータが存在する場合にのみ次のtaskに進みます。
timeoutに設定した時間待機しても該当のデータが存在しない場合、gcs_file_not_foundで指定したslackチャンネルに通知します。
<create_(raw_)dataset, create_(raw_)table_if_not_exists>
必要なデータセット、テーブルを作成します。
すでに存在する場合には、既存のデータセット、テーブルをそのまま使用されます。
今回は実行のたびに
新しい空のテーブル{{PROJECT_ID}}.{{TMP_DATASET}}.{{SINK_TABLE}}
と
現在ユーザーが参照しているテーブル{{PROJECT_ID}}.{{DWH_DATASET}}.{{SINK_TABLE}}
の2つが必要になるのでそれぞれのデータセット、テーブルを作成します。
<truncate_raw_table>
truncate_raw_table = BigQueryExecuteQueryOperator(
task_id="truncate_raw_table",
sql="{}/truncate_raw_table.sql".format(SQL_DIR_PATH),
use_legacy_sql=False,
location="asia-northeast1",
)
テーブル{{PROJECT_ID}}.{{TMP_DATASET}}.{{SINK_TABLE}}を空にします。
truncate_raw_table.sqlの中身はTRUNCATE TABLE {{PROJECT_ID}}.{{TMP_DATASET}}.{{SINK_TABLE}};` です。
<insert_bq_raw_table_task>
PythonOperatorというPythonに記載した処理を行うtaskです。
Pythonには以下の処理をさせます。
- GCSのファイルを取得
- GCSに保存されている形式はcsv, jsonなど。必要に応じて圧縮されている。
- 必要なデータを選択し使いやすい形に整形する
- jsonの場合深くネストされたデータが欲しい場合があり、コードが複雑になる可能性がある
- データ型の変換
- 整形したデータをBigQueryの
{{PROJECT_ID}}.{{TMP_DATASET}}.{{SINK_TABLE}}に格納する
Pythonを作成する際の注意点
1~3の流れをどの単位(ファイル単位など)で実行するか、リクエスト数や処理速度、メモリなどに注意して作成します。
特にBigQueryは1日のリクエスト回数などの制限があるのでそれも考慮します。
insert_bq_raw_table_task = PythonOperator(
task_id="insert_bq_raw_table_task",
provide_context=True,
templates_dict={"TARGET_DATE": AdDataConfig.TARGET_DATE"},
python_callable=insert_bq_raw_table,
)
config.pyで指定したTARGET_DATEをPython内部で使用するためには、templates_dictに記載します。
また、AirflowのTemplates referenceをPython内部で使用するためには、provide_contextをTrueとします。
<insert_unique_data>
新しい空のテーブル{{PROJECT_ID}}.{{TMP_DATASET}}.{{SINK_TABLE}}に新しいデータを投入します。
BigQueryExecuteQueryOperatorを使用すると、例の場合ではsqlに指定したinsert_unique_data.sqlの結果がinsertされます。
write_dispositionでWRITE_TRUNCATEを指定し、今回insertしたデータだけが残るようにします。
insert_unique_data = BigQueryExecuteQueryOperator(
task_id="insert_unique_data",
sql="{}/insert_unique_data.sql".format(SQL_DIR_PATH),
destination_dataset_table="{}.{}.{}".format(
PROJECT_ID, AdDataConfig.DWH_DATASET, { 媒体名 }.SINK_TABLE
),
write_disposition="WRITE_TRUNCATE",
allow_large_results=True,
use_legacy_sql=False,
location="asia-northeast1",
)
「第3章Airflowコードを型化する データの洗い替えのロジックの紹介」で説明した
- 洗い替えの対象となる期間のデータを再取得する。
- 最も新しく取得したデータに洗い替える。
- 新しいデータに存在しないデータは残す。
の3点を実現するため、
{{PROJECT_ID}}.{{DWH_DATASET}}.{{SINK_TABLE}}へのデータ投入する際のsql(insert_unique_data.sql)は次のような感じで作成します。
insert_unique_data.sql
SELECT * EXCEPT(row_num)
FROM
(
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY
report_date, {その他、洗い替えする際のkey} -- 元データがuniqueになるように漏れなく指定します
ORDER BY
get_report_date DESC, -- get_report_dateが最新のデータをrow_num = 1とする
created_at DESC -- 1日に複数回実行された場合には、get_report_dateが最新のデータが複数存在してしまうので、created_atが最新のデータをrow_num = 1とする
) as row_num
FROM
(
SELECT
report_date,
{洗い替えする際のkey},
{実績値},
created_at,
get_report_date
FROM `{{PROJECT_ID}}.{{DWH_DATASET}}.{{SINK_TABLE}}`
UNION DISTINCT
SELECT
report_date,
{洗い替えする際のkey},
{実績値},
created_at,
get_report_date
FROM `{{PROJECT_ID}}.{{TMP_DATASET}}.{{SINK_TABLE}}`
)
) WHERE row_num = 1
<delete_tmp_table>
insert_bq_raw_table_taskで{{PROJECT_ID}}.{{TMP_DATASET}}.{{SINK_TABLE}}に格納したデータは不要になったのでテーブルを削除します。
delete_tmp_table = BigQueryDeleteTableOperator(
task_id="delete_tmp_table",
deletion_dataset_table=f"{PROJECT_ID}.{AdDataConfig.TMP_DATASET}.{{ 媒体名 }.SINK_TABLE}",
)
おわりに
最後まで読んでいただきありがとうございました!

Discussion