この記事は、開発生産性 Advent Calendar 2022の24日目の記事です。
株式会社スマートショッピングでSREをしているbiosugar0です。
今回はSREが現在DevOpsに向き合い、開発を加速させるために取り組んでいることについて紹介します。
開発を加速させるDevOpsという考え方
DevOpsは、開発チームと運用チームが協力し、よりスムーズに高品質なサービスを作り上げるという考え方です。
歴史的に、企業は複雑なシステムを開発運用していくために「開発」と「運用」という別々のチームにそれぞれの仕事を任せてきました。
このアプローチに伴う開発/運用の分断には、多くの問題がありました。
その中でも大きい問題は、2つのチームの目標が対立関係に陥りやすいことです。
開発者は新しい機能や改修をスピード感をもって開発してリリースしたい、運用者はシステムをより安定させるためにシステムに変更を加えたくない、といった具合です。
(Googleでは、およそ70%のサービス障害は、稼働中のシステムの変更が原因だったそうです。)
お互いに良いサービスを作りたいというゴールは同じはずです。
しかし、開発者/運用者のように分断された関係では、お互いのチームが目指す方向が対立してしまいます。そこで出てきたのが、開発者と運用者が同じ方向を向いて協力してサービスを作っていくための哲学、DevOpsです。
DevOpsという単語は2009年のオライリー主催のイベント「Velocity 2009」において、
10+ Deploys Per Day: Dev and Ops Cooperation at Flickrという発表で初めて公の場で用いられました。
この発表のはじめのほうで、発表者のPaul Hammond,John Allspawらはこう述べています。
ビジネス、特にオンラインビジネスで働く上での現実は、ビジネスには変化が必要だということです。
もし、あなたのビジネスが立ち止まっていたら、TwitterやFacebookのような新興企業に追い越されてしまうでしょう。もちろん、問題はその変化です。
ほとんどの障害の根本原因を調べて一般化すると、「変化」という結論に至ります。
数日前、数時間前、数週間前に変更がなければ、ほとんどの障害は起こりません。つまり、2つの選択肢があります。
安定性を重視して変化を阻止するか。
それとも、賢くなって、必要に応じて変化を起こせるようなツールや文化を構築するかです。
ここで言う"必要に応じて変化を起こせるようなツールや文化を構築する"ためのDevOpsということです。
DevOpsの哲学のキーポイントを覚えておくのに役立つのが、Jez Humble による造語で、CALMSというものがあります。
これはCulture (文化)、Automation (自動化)、Lean (リーン)、Measurement (測定)、Sharing (共有) の頭文字です。
DevOpsのアプローチでは、組織全体を改善できるように何かを改善し、結果を計測し、責任と目的をDevとOpsで共有します。
サイトリライアビリティワークブックでは、その哲学の鍵となる5つの概念が紹介されています。
- サイロ(チーム間の溝が深まり連携ができない状態)の抑制
- アクシデントは普通のこと
- 変化は徐々に起こすべきもの
- ツールと文化は相互に関係する
- 計測は必須
組織の改善の指標には、four keysという指標が有名です。
開発組織の生産性を計測するfour keys
GoogleのDevOps Research and Assesment(DORA)によって、毎年State of DevOpsというレポートが公開されています。
日本語ではLeanとDevOpsの科学という本に研究の結果がまとめられているのでおすすめです。
この調査研究はソフトウェアを迅速かつ確実にデプロイすることがビジネスにどう影響するか、開発とデリバリーをどう高速化するかについて、
あらゆる規模、あらゆる業種の世界中の組織を対象に調査したものです。
したがって、この結果はどのような組織にも効果的なものであり、改善に応用できるとされています。
ソフトウェアデリバリのパフォーマンスを的確に計測できる尺度を選ぶにあたって、調査チームは
- グローバルな成果に焦点を当てるもの。チーム同士が競争、対立するような状況を防ぐ。
- 生産量ではなく成果に焦点を当てるもの。「忙しいが価値のない、見せかけの作業」を重ねる大量の仕事を推奨しない。
という基準を満たす計測尺度を探しました。その結果、彼らは「four keys」と呼ばれる以下の4つを選び出しました。
- リードタイム
- デプロイの頻度
- サービス復旧の所要時間
- 変更失敗率
この指標を基準に調査したところ、ソフトウェアデリバリの改善効果の高い様々なケイパビリティ(組織的な能力あるいは機能)が立証されました。
その全体像を図に示したのが以下の図です。
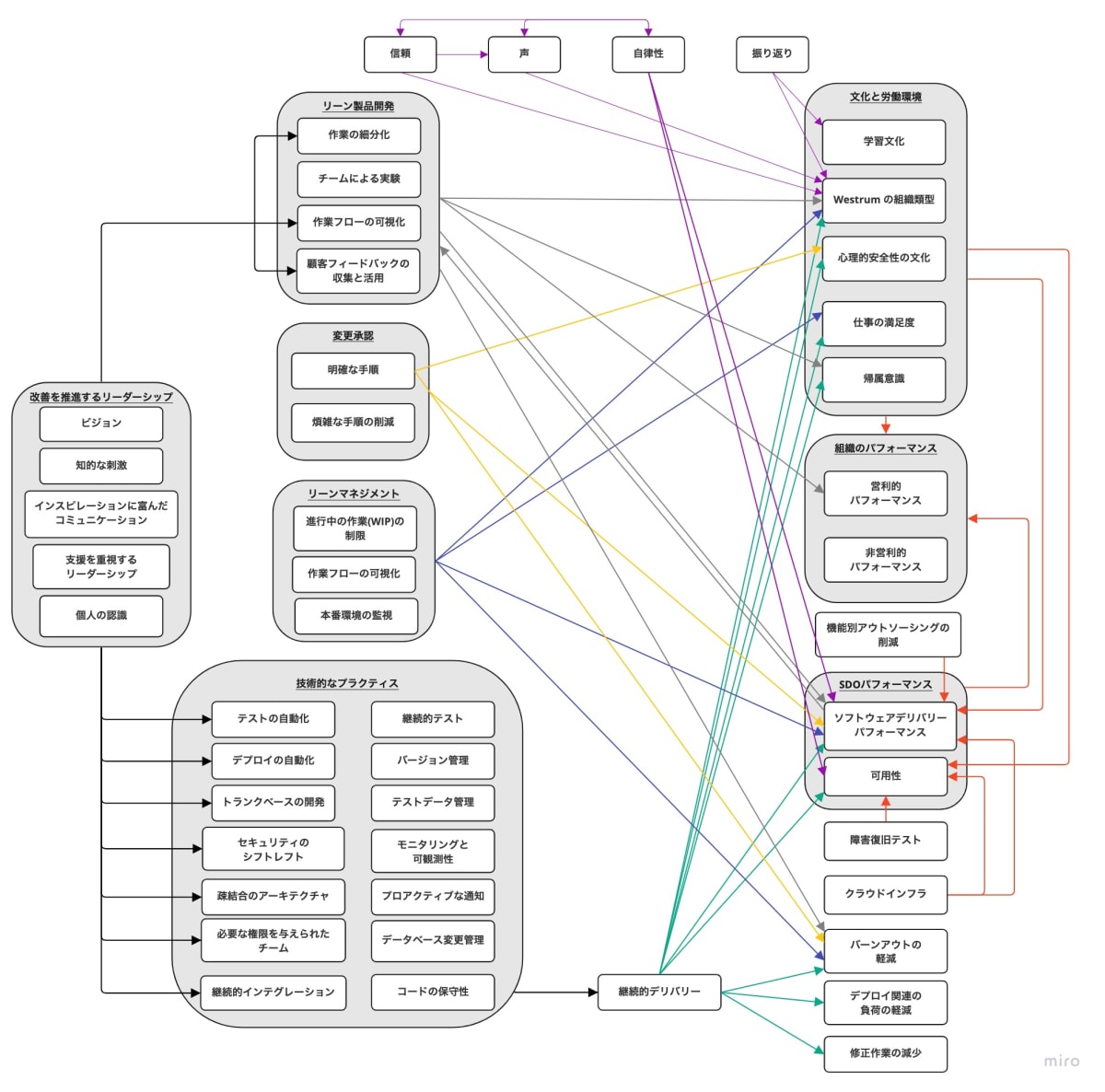
図1. DORAによる研究の全体像を日本語で表現し直したもの
これらの関係性から、改善効果の高い各ケイパビリティについて整備していくのが効果的です。
各ケイパビリティの詳細は、GoogleのCloud アーキテクチャ センターの記事で紹介されています。
興味のある方は、ぜひ図1を全体地図として読んでみてください。
DevOpsとSRE
DevOpsは運用とプロダクト開発のライフサイクル全体をスムーズに回すための哲学です。
一方、Googleから始まったSRE(Site Reliability Engineering,Site Reliability Engineer)はサイトリライアビリティワークブックでは以下のように書かれています。
SREは仕事のロールであり、私たちがうまくいくと見いだした一連のプラクティスであり、それらのプラクティスを活気づける信念です。DevOpsを哲学と働き方へのアプローチと考えるなら、SREはDevOpsが掲げている哲学の一部を実施したものと言え、「DevOpsエンジニア」よりも明確な仕事やロールの定義と言えるでしょう。したがって、ある意味でclass SRE implements interface DevOpsなのです。
1.2 SREの背景/The Site Reliability Workbook
SREの原理は以下のようなものです。
- 運用はソフトウェアの問題
- サービスレベル目標(SLO)による管理
- トイルの最小化のための作業
- 今年のジョブの自動化
- 失敗のコストの削減による速度の向上
- 開発者との共有オーナーシップ
- 役割や仕事の肩書きに関わらず同じツールを使うこと
SREとDevOpsには多くの共通点があり、先程の
class SRE implements interface DevOps
1.2 SREの背景/The Site Reliability Workbook
という言葉を見るとロールとしてのSREがDevOpsを推進するのは自然なことでしょう。
私はDevOpsを実現するための方法論のひとつが、Site Reliability Engineeringだと捉えています。
DevOpsとSREは、改善のためには変更が必要だという認識を受け入れることが重要です。
どちらも開発チームあるいは組織全体をよりよくし、顧客に価値を提供することを目指しているため、(質を含めた)開発生産性の改善が成果であるべきです。
顧客に価値を提供できない状態は、すなわちサービスの信頼性が失われている状態です。
スマートショッピングのSREチームでは、我々が提供するようなSaaSプロダクトにおいて信頼性とは、
- SLI/SLOなどで表されるシステムの安定性
- よりよい開発者体験によるすばやいバグ修正や魅力的な機能改修で価値を届ける
ことによって構成されていると認識しています。
SREのDevOps推進における役割をチームトポロジーから考える
チーム開発をする場合、ソフトウェアデリバリーのパフォーマンスに重要なのは個人ではなくチームのパフォーマンスです。
開発チームのパフォーマンスを最大化することを目的としたときに、SREチームの役割とは何でしょうか?
私がSREチームを再立ち上げしたときに参考にした文献のひとつに、チームトポロジーという本があります。
DevOpsは開発(Dev)と運用(Ops)のサイロ(チーム間の溝が深まり連携ができない状態)を抑制してソフトウェアデリバリーのパフォーマンスを改善することを掲げていますが、実際に組織としてどのような構造を作り、チーム間の相互作用はどうあるべきかのヒントを与えてくれるのがこの本です。
チームトポロジーの組織モデルでは、チームの4つの基本的なタイプと3つの主要なチーム間のコミュニケーションパターンが、コンウェイの法則、チームの認知負荷、応答性の高い組織の進化を意識して組み合わされ、ソフトウェアの構築と運用に対する現実的なアプローチを定義します。
チームの4つの基本的なタイプは次のとおりです。
- Stream-aligned team: 事業の根幹となるビジネスのStream(プロダクトや機能の開発など)に沿って仕事をする職能横断チーム。他のチームはこのチームがStreamに集中できるようにする役割を持つ。
- Enabling team: Stream-aligned teamに欠けている新技術やプラクティスの導入を支援し、能力を獲得するのを支援するチーム。
- Complicated-subsystem team: 数学、画像処理など技術的な専門知識が必要となるサブシステムを研究、開発する責任を持つチーム。
- Platform team: Stream-aligned teamによる自律的なデリバリーと運用を加速するための内部サービスを提供するチーム。
それらのチーム間のコミュニケーションパターンは3つあります。
- Collaboration: 定義された期間中に一緒に働く。
- Facilitating: 1つのチームが別のチームを支援し、助言する。
- X-as-a-Service: 1つのチームが「サービスとして」何かを提供し、もう1つのチームがそれを消費する。コミュニケーションは最小限。
各チームが適切なコミュニケーションを取ることが重要です。例えばStream-aligned teamとPlatform teamが常にCollaborationしていると、Platform teamなしではStream-aligned teamの仕事が進まなくなってしまいます。
チームトポロジーモデルの基本的な原理は、事業の根幹となるビジネスの流れ(Stream)をいかにスムーズに流すことができるかにフォーカスしています。また、チーム間のコミュニケーションパターンは、目指す理想を定義した上で動的に変化することができます。
スマートショッピングのSREチームでは、以下のように理想のチームトポロジーを定義しました。

我々はSREチームをあえてEnabling teamとPlatform teamの両方の役割をもたせたチームとしています。コミュニケーションパターンはFacilitatingとX-as-a-Serviceを中心とします。
これは、我々SREチームが以下の役割を持ち活動しているからです。
- プロダクト開発チームが信頼性エンジニアリング能力を獲得するのを支援し、プロダクト開発チームが自律的にSLOの運用やモニタリングなどのプロダクトの信頼性を維持しながら開発するプラクティスを実践できるようにする。
- プロダクト開発チームが必要とする内部サービスを提供することでインフラ基盤などを開発、運用する認知負荷を減らし、プロダクト開発チームが自律的に安全で素早いソフトウェアデリバリーを行うことを支援する。
個人的には、Enabling をX-as-a-Serviceで実現するPlatformを作れたらいいなと思っています。Enabling Platform ですね。
そのため、Site Reliability Engineering のプラクティス、ケイパビリティをプロダクト開発チームにインストールする役割をSREチームは持っています。
Site Reliability Engineeringを実践するのは開発組織全体で行うべきだからです。
先述した通り、我々は
- よりよい開発者体験によるすばやいバグ修正や魅力的な機能改修で価値を届ける
ということも信頼性の構成要素であると捉えています。
そのことから、DevOpsを推進し開発生産性を向上させることは信頼性にフォーカスするSREチームの主要な目的とも言え、 SREチームは開発生産性を向上させる主要な役割を果たす立場だと考えています。
スマートショッピングでのSREのDevOps推進への取り組み
弊社CTOの開発生産性向上のための取り組みの記事でも紹介しているように、DevOps推進委員会が立ち上がり、現在開発生産性向上への取り組みが始まりました。
この取り組みのなかで、SREとして取り組んでいることを紹介します。
開発生産性の計測
現在、Findy Team+による開発生産性の計測を行っています。
継続的に追っているのはStream-aligned teamであるプロダクト開発チームです。
計測の組織的な粒度は柔軟にでき、プロダクト開発チームを親チームとしてその中のユニットを子チームとして計測しています。
プロダクト開発全体のメトリクスを見たり、ユニットごとに見たりすることで開発の現状を知ることができます。
SREではこのFindy Team+のメトリクスが実態にあっているかなどの有効利用するための計測のメンテナンスを行っています。
ノイズとなるデータが見つかった場合は、フィルタリング可能にする仕組みを構築するなど対策を打ちます。
また、Findy Team+のカスタマーサクセスの方との定期的なミーテイングで施策のヒントをもらったりしています。
プロダクションミーティングでの定期的な状況のトラッキング
スマートショッピングでは、プロダクト開発チームとの間に週1回の情報共有の機会を設け、
プロダクトのメトリクスなどからの現在の状況の認識共有、運用、開発における相談、SREからの連絡などを行っています。
これにより日頃からある程度情報を共有出来ている状態を維持することができ、プロダクト開発チームはSREからの適切なサポートを受けることができます。
このような場のことをSRE本ではプロダクションミーティングと呼んでいます。
プロダクト開発チームの代表数人が出席するこのSREとのプロダクションミーティングでは、
SREへの相談、生産性課題の吸い上げのパートを設けていました。
DevOps推進委員会始動後は、このパートを拡張し、
- SREへの相談
- 開発生産性向上施策のトラッキング、委員会で決めたルールの運用状況の確認、相互フィードバック
- 各UnitのFindy Team+のメトリクスの確認とボトルネックがあればヒアリング
- 現場の生産性課題の吸い上げ
を実施しています。
ここで得た課題などはDevOps推進委員会へフィードバックし、改善を回しています。
Datadogなどを見ながらプロダクトの状況の話をする場でもあるので、
four keysの計測結果などを見ながら話をするように拡張するにはぴったりの場でした。
開発生産性向上施策を効果的にするための仕組みの構築
開発生産性向上施策には、ルールを決めるだけではなかなか定着がしないものもあるかもしれません。
プルリクエストの粒度を小さくする、などがそうです。
このような課題に対して、自然に意識するように仕組みを構築するのが有効な場合があります。
例えば、現在SREで仕組みを用意したものは以下のようなものです。
- Findy Team+による計測でノイズとなるプルリクエストの自動ラベリングするGitHub Actions Workflow。(Findy Team+では、プルリクエストのラベルによる計測対象のフィルタリングができます)
- プルリクエストの変更行数が200行を超えたらWarningするGitHub Actions Workflow。あくまでWarningでマージすることはできる。
プルリクエストの粒度を小さくするなどといった文化も、エンジニアリングで定着をブーストできると思うので今後も仕組みで効果を上げられるところは実装していきます。
そして日々のSite Reliability Engineering
Site Reliability Engineeringそれ自体がDevOpsを推進する方法そのものです。
Stream-aligned teamのStreamをスムーズに流して顧客にすばやく価値を提供するため、
日々インフラ変更の半セルフサービス化やトイルの削減などに取り組んでいます。
SREチームの再立ち上げとミッション、ビジョン、バリューを作った話でも書いたように、
スマートショッピングのSREチームのミッションは
日常を革新するプロダクトが走り続けるために、整備された道とガードレールを作り改善していく
です。
SREチームは、Stream-aligned teamたるプロダクト開発チームが全力で安全に走り続けられるようなプラットフォームと文化を作っていきます。
そのために、我々はプロダクトのソフトウェアだけでなく、組織のエンジニアリングにも取り組む必要があるでしょう。
スマートショッピングのSREチームは走りだしたばかりです。共に理想を探求する仲間を募集しています。
一緒にGoogleのような大企業ではないスタートアップでこそ、Site Reliability Engineeringが威力を発揮し、ビジネスを加速させるということを示しましょう!
参考文献

IoT重量計スマートマットを活用した在庫管理・発注自動化DXソリューション「SmartMat Cloud」を運営しています。一緒に働く仲間を募集しています。 s-mat.co.jp/recruit
Discussion