Open1
ORM vs PRM: 十分な学習データがあればPRMの方が有望
paper: Let's verify step by step, 2023.5
OpenAIの研究チームによる「信頼できるverifierの学習」に関する論文。
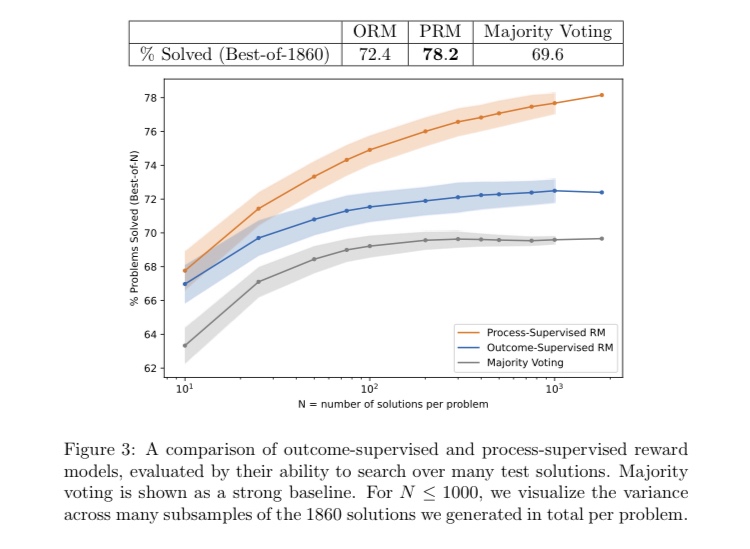
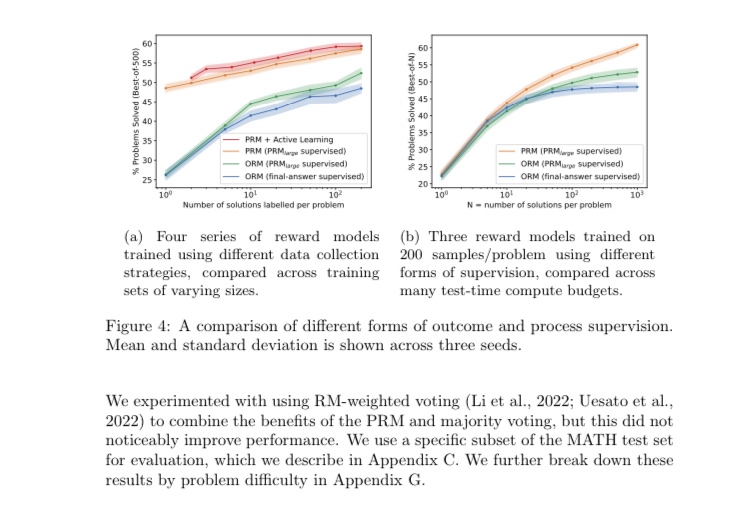
ここでの主要な結論は、最終回答にのみ報酬を与えるORMよりも、推論の各ステップに報酬を与えるPRMの方が学習効率が良いというもの。
十分な性能のgenerator(GPT-4)を使って解法を生成すれば、解法の候補数に対して正解数(verifierが選んだTop1の候補の正答率)はスケールするが、その効果はORMよりもPRMの方が飛躍的に高いことをMATHデータセットで示した。
STaRやDeepSeek-R1などが「正答に導く解法のCoTを擬似ラベルとして用いる」アプローチを用いているのとは対照的に、ステップごとの推論の正誤ラベルは人間が与えている。
著者らのスタンスとしては「最終解答は正しいが推論過程は誤っている」ケースを問題視している。
所感
Noam Brownらの推論時スケーリングの文脈では、「解法の候補の数」は探索ステップ数、すなわち探索コストに置き換えることができる。
この研究では教師信号として人間のラベルに依存しているが、一応Brownらの研究と組み合わせるとスケーリングしそうだ、という見通しはこの時点で立ちそうに思える。