Closed1
非LLMのLong Context周りの近況について
経緯
Linear Transformerは主にAttentionの計算を高速化することに主眼がある感じかと思っていたが、long-context周りのSOTAを見ているとAccuracyがxFormer系のモデルを大幅に上回っている[1]。効率化以外にも性能面での工夫がかなりありそう。今後読む論文のストックとして目ぼしいものをキャッシュしておく。
ベンチマーク
2020年にLong Range Arena(LRA)というpublicベンチマーク[2]が公開されてlong contextのSOTAの比較がしやすくなった。2020年11月8日時点でのtopはBigBirdでAvgスコアが55.01だった。
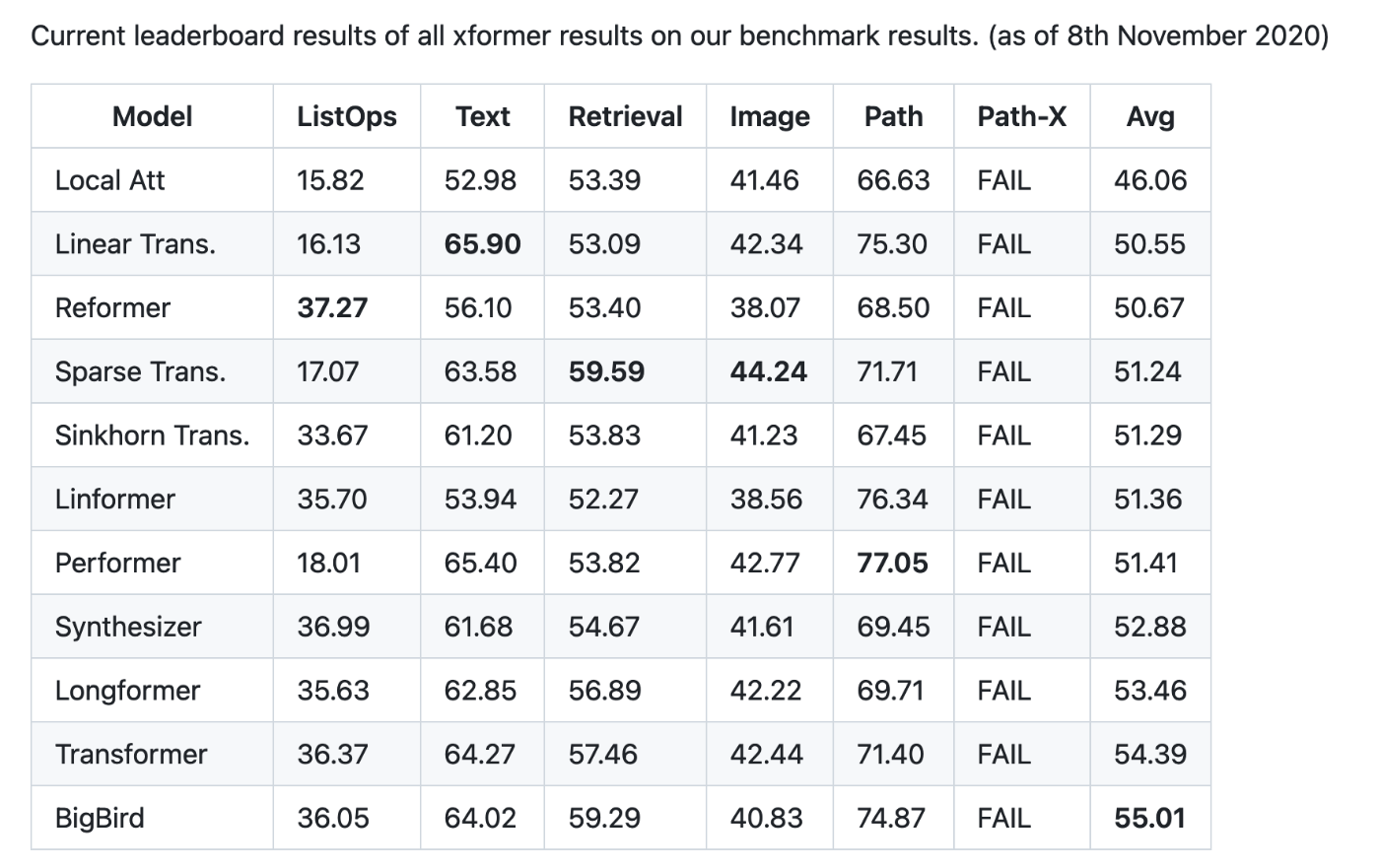
現在(2024年8月19日)のSOTA[1]を見ると、Avgスコアが88.21とここから大幅に引き上げられている。
昔のベンチマークにはPathfinder-Xのベンチマークが含まれていないので単純比較はできないものの、他のタスクを見ても差は歴然としている。

現時点でのTop2の論文に掲載されているベンチマーク結果[3, 4]によると、これらの結果は単に性能改善だけでなく速度改善も同時に行なっているようである。
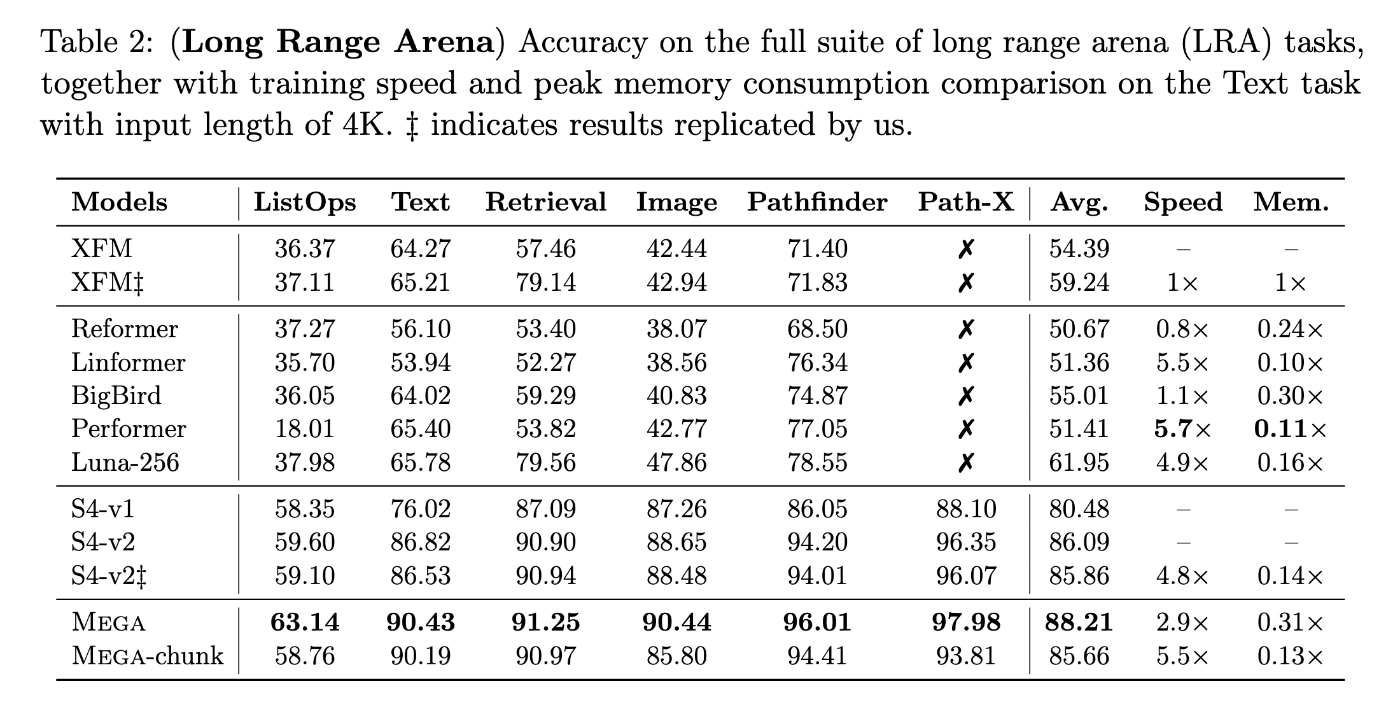

ただし、このベンチマークは非常に小さなパラメータのモデルのベンチマーク(d=256, num_layers=4~6)であるので、近年のLLMでの成果とは互換性がないかもしれない。
Reference
このスクラップは2024/08/19にクローズされました