Open1
MLA(Multi-head Latent Attention)
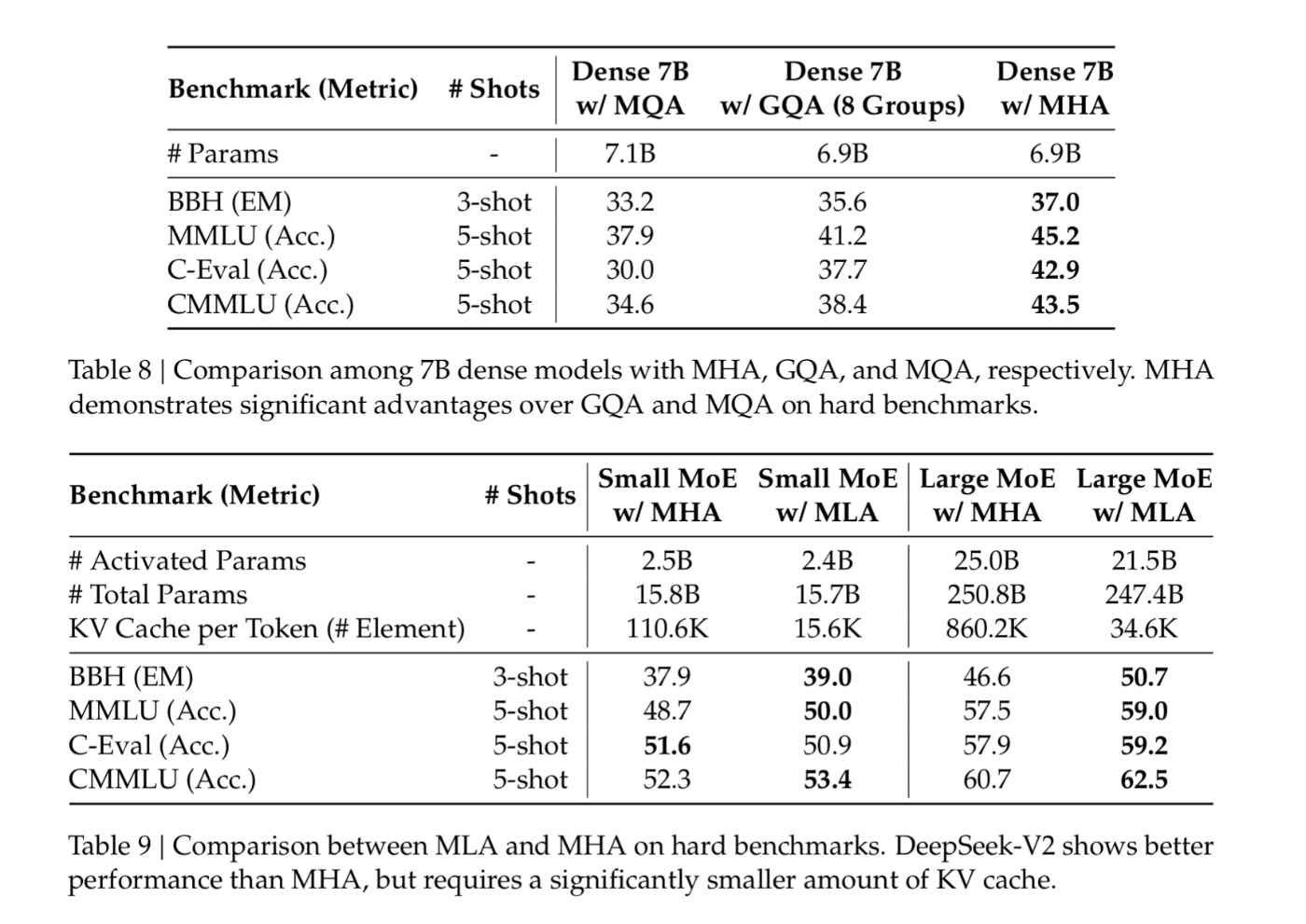
DeepSeek-V2で導入されたMLA(Multihead Latent Attention)ではKV-cacheのサイズを抑えるためにKV/Qの次元削減をしている。
言語モデリングではMHSAよりMLPの方が重要なのでこっちに計算量はサボっても問題ないのかもしれない。
- V2のtechnical paperによればlarge MoE modelでkv-cacheを4%に削減したとある
- 理屈はわからないが、MHAの方がMHAより性能が良いという結果になっている

source: https://github.com/flashinfer-ai/flashinfer/pull/551