Open1
強化学習によりinference scalingは生じているか?
強化学習によりinference scalingは生じているか?
推論時のmax_lengthを途中で打ち切った出力から別のモデルを使って回答を導き出せるかを調査。結果、
- 学習stepを増やすほど、推論時のtoken lengthを増やすことで得られるゲインが増加
- 正解するかしないかに決定づける推論stepをkey stepと定義し、key step中の単語の頻度分布を調べると let's, waitなどの内省に用いられるものが頻出
-> RLの結果、実際に推論時スケーリングの能力が向上することを示唆
他にも
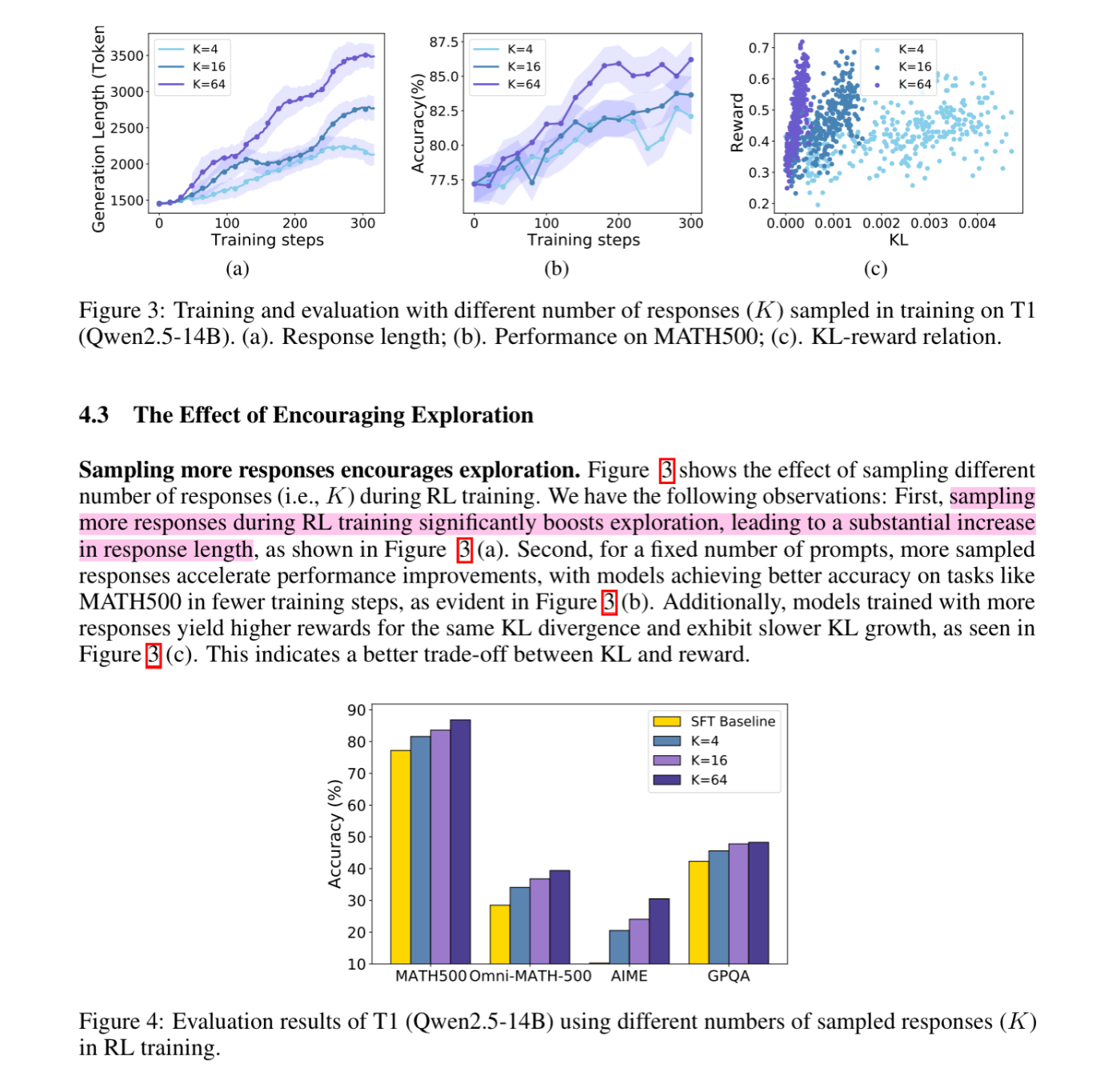
- サンプリング数を増やすほど学習後のモデルの平均出力トークン長が増加 -> 探索が促される?
Tips
- Entropy bonusによりover confidentな学習を抑制
- temperature=1.2と高め
- min_p>0だと出力結果が劣化したのでmax_p=0.95を採用
批判: 学習ステップを増やすほど出力テキスト長が伸びていくので「解答の途中で打ち切られる」確率も上がる。その結果を反映しただけかもしれない