Open2
7BモデルでDeepSeek-R1のRLを再現する
7B model/8k dataを使ってR1のself-improve phenomenaを再現したという報告。
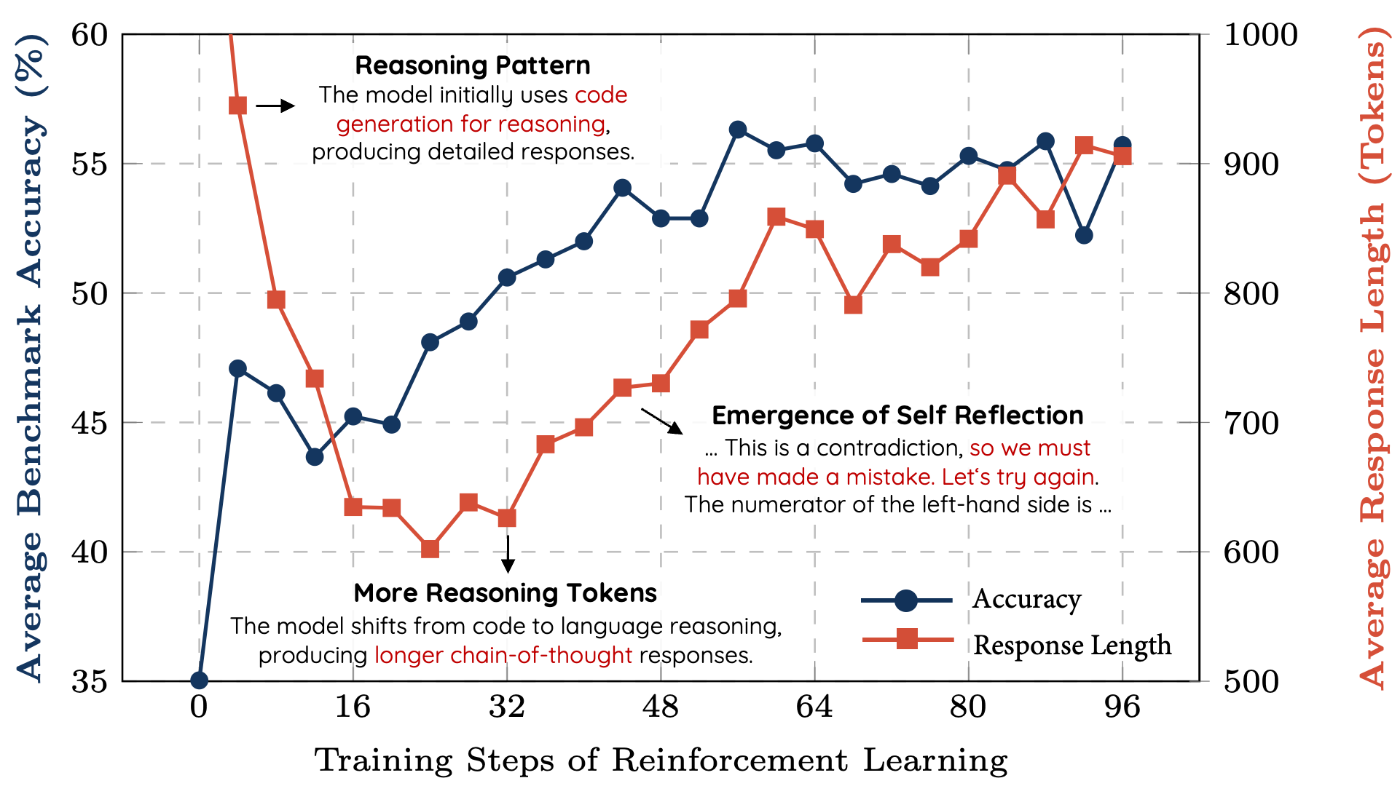
Training stepの増加とともにトークン長が増加する現象や、"aha moment"も再現した。
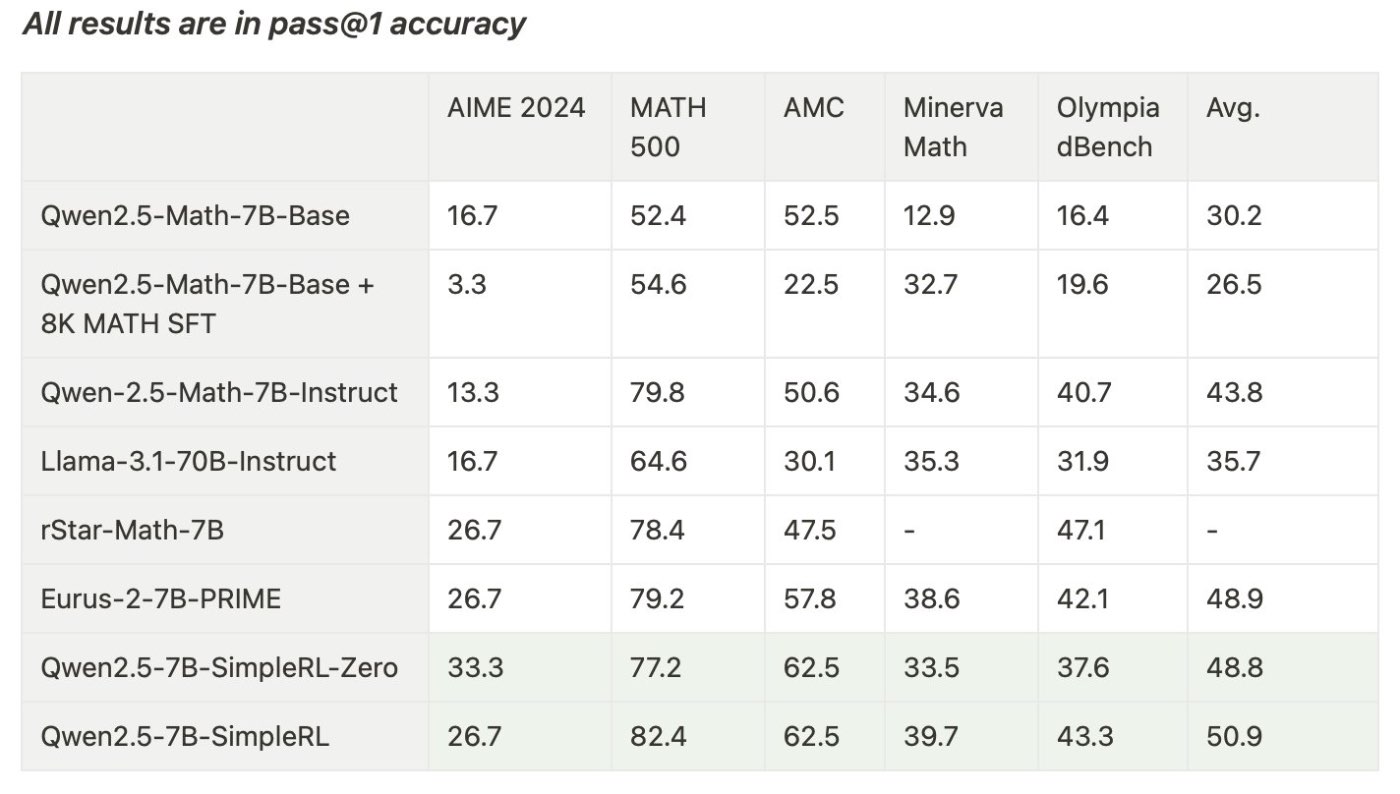
訓練に使用したのはMathデータセットだが、AIMEのようなより難しい問題に対しても汎化した。
最初にQwQで生成したCoTテキストを使ってwarmupする。
R1とは異なり、トークン長が最初減少し、再び増加に転じるという振る舞いを観測した。
おそらくこれはベースモデルのコンテクスト長がQwQより短いので、解法の途中で打ち切られたためだろう。

3Bモデルを使った再現実験も報告されている