Open1
PagedAttention: vLLMにおけるメモリ削減手法
PagedAttention
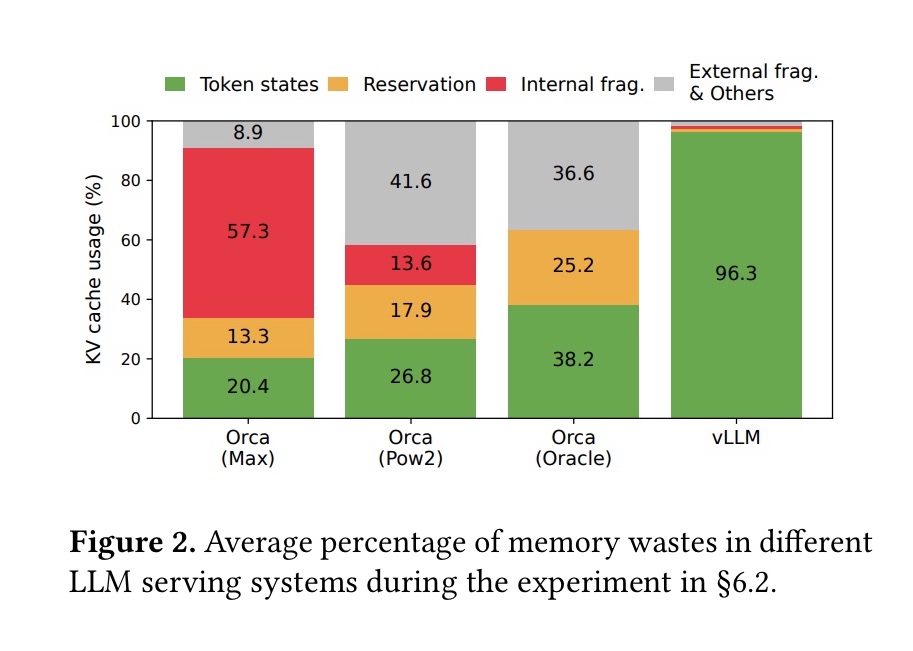
- メモリ消費に占めるKV cacheの割合は大きい(13Bの場合30%)
- このうち、既存のシステムは20.4%ほどしか有効活用できていない
- その原因は連続するメモリに割り当てることによるフラグメンテーション
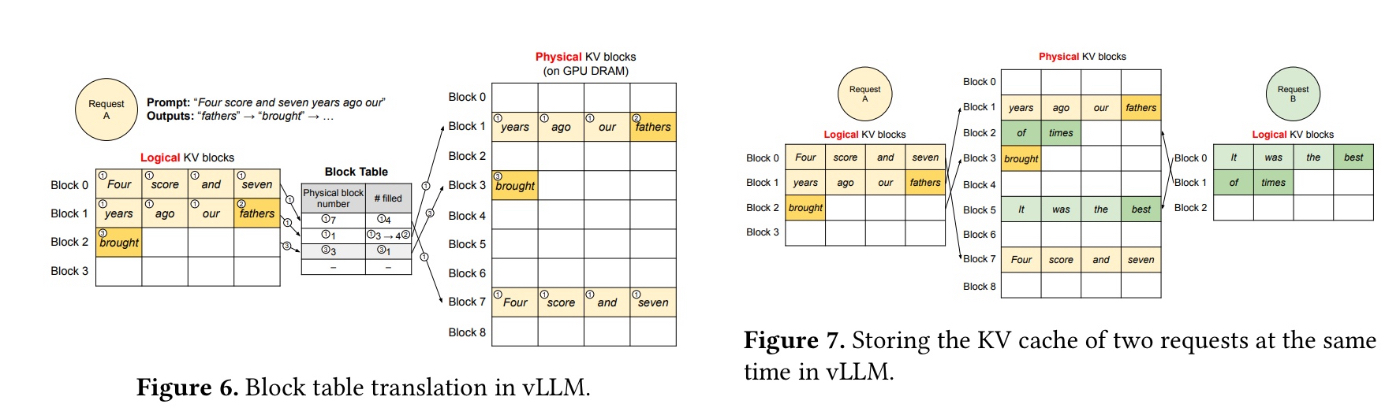
- 固定長のblock単位で不連続なメモリ領域に確保することで無駄をほぼzeroにした
仕組み
- 連続するメモリ空間に割り当てると確保されているが実際には使えない隙間ができる(fragmentation)
- あらかじめサイズがわからないのでmax_token割り当てる→それ未満の場合は余る(internal fragmentation)
- 異なるリクエスト間でのメモリ領域の隙間(external fragmentation)
- 固定長のblockで管理することでより柔軟なメモリ管理ができる
Tips:
- KV cacheは以前処理したすべてのトークンに依存する→場所が変わると同じトークンでも計算結果は異なる
PagedAttentionでやってないこと:
- Cache hit rateによるoffloadingとSwapping
PAでやってるSwappingはリソースがfullになった場合に先に来たリクエストの処理を優先させるため、最後のリクエストの処理途中のcacheを退避させる目的で使われている