Open1
DeepSeek-R1の学習コスト
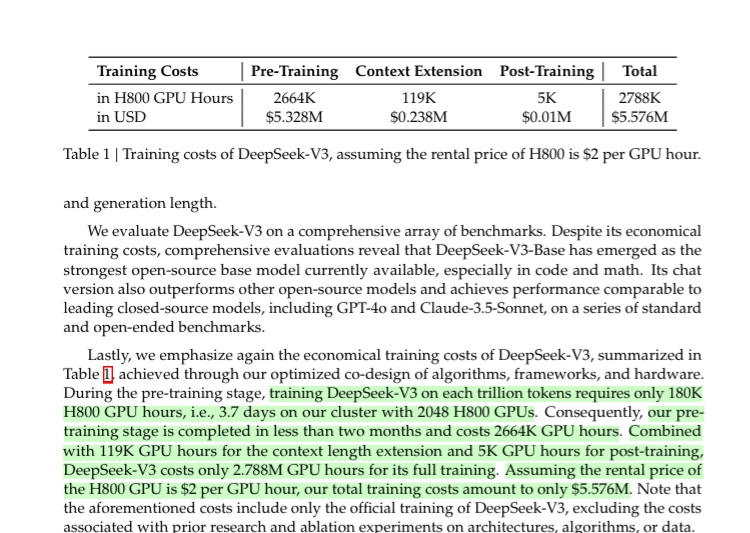
R1のベースモデルであるDeepSeek-v3の事前学習のコストは~$5.3Mらしい。
これにはパラメータ探索などのコストは含まれないが、それでも$数10Mほどの計算機コストで実現できたのではないか。
これを考えると後発のプレイヤーでも高い目標と実現能力があればトップ競争に参入できる可能性が見える。
もちろん背景には
- 大規模なMoEモデルを安定して学習する技術
- FP8の混合精度学習を安定して実現する技術
- H800x2048のクラスタにモデルやテンソルを分散し、効率的に学習する技術
といった低レイヤの最適化を含む高度な技術投資がある。
Tips
- 事後学習にかかったコストは全体の僅か0.18%(R1の事後学習にはもっとかかってるかもしれないが、それでも数%以下だろう)
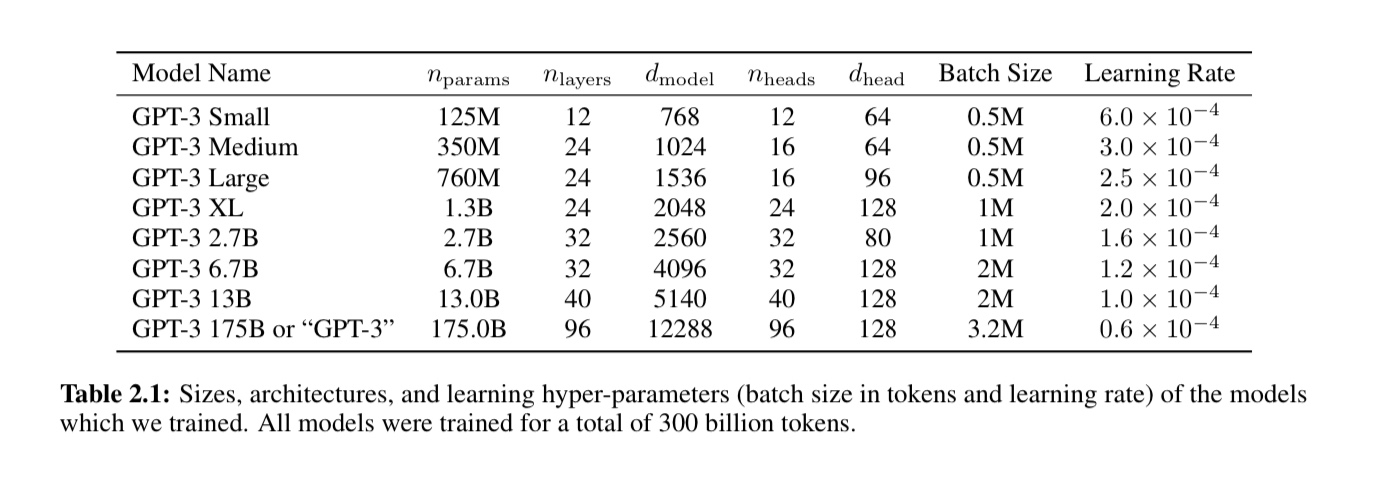
- V3/R1のパラメータサイズ681Bというのは、GPT3が175Bで、GPT4が500B~1Tだとすると、大きさ的にはGPT4と同規模か少し小さいくらいの規模と思われる
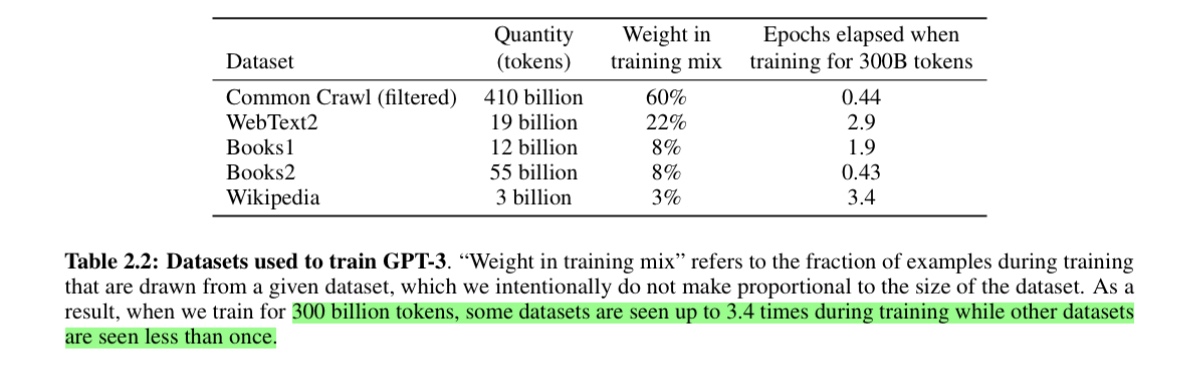
- V3の事前学習に用いられたコーパスのトークン数は14.8Tで、GPTの300Bと比較すると50倍にもなる