Open2
N-gramによる語彙数のスケーリング
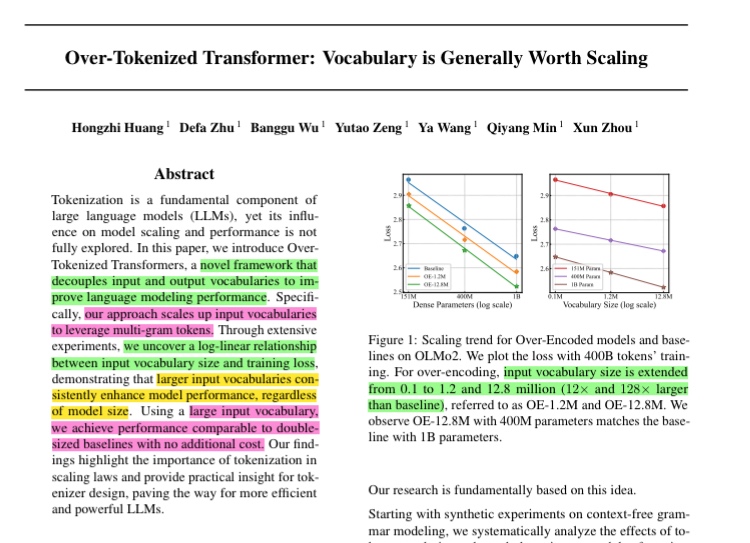
Over-tokenized Transformer
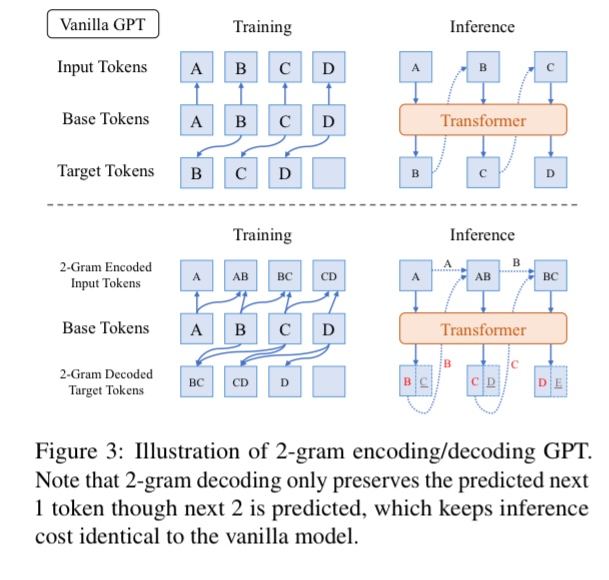
- 直近n tokenの埋め込みを1-tokenに詰め込むことで学習を効率化する
- BLT(Byte Latent Tokenizer)と同様hashを使い、12.8Mまで語彙拡張。PPLと下流タスクの評価で優位性を確認

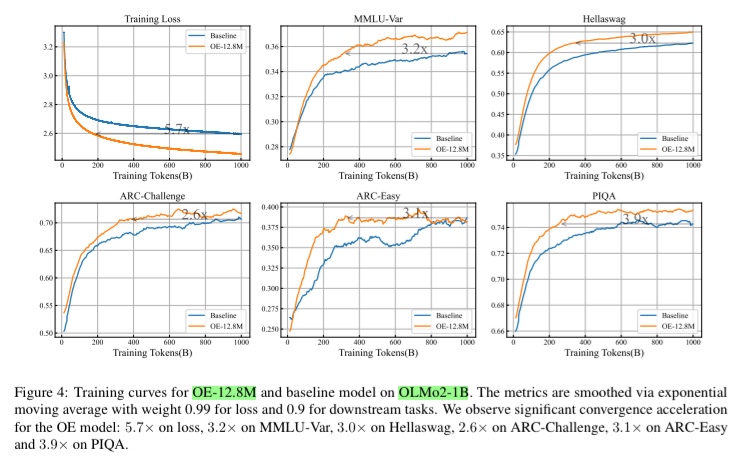
Tips: 本来なら語彙拡張を行うとPPLでの比較は意味がないが、この論文ではPPLで評価している
→推論時は先読みをせずに1-tokenずつ予測するのでPPLでの比較が有効(多分)
なお、語彙拡張と言ってもn-gramを表現する新たなembeddingをルールベースで定義してるだけなので、元のtokenizerはそのまま使える。また、1-gramの表現は不変になるよう定義している。
この手法はBLTと同様、1-tokenに詰め込む情報を増やすことでスケーリングを試みたものと理解している(現状まだ余裕があるという仮定のもと)。
→日本語など既存のtokenizerが仕事してない言語で活躍するか?