音声信号のスペクトル分解の手法について
torchaudioのSpectrogramの問題点
音声信号の周波数スペクトルを抽出する際には一般的にSTFTを用いることが多いが、torchaudioのSpectrogram[2]には以下の問題がある。
- 周波数の範囲を直接指定できないので使わない周波数のfilter bankは計算リソースの無駄になる
従って最初から使用したい周波数帯が決まっているならばMelSpectrogram[3]を使う方が上記の観点から言えば都合が良い。ただし、副作用としてfilter bankの周波数がmel scale(log scale)に変換される。
等間隔の周波数帯のfilter bankを見たい場合は都合が悪い。
他のスペクトル特徴について
STFT以外にもLFCC[5]やMFCC[4]やという三角形の形状のfilterを基底関数にしたスペクトルの抽出方法がある(STFTはsin/cosを基底関数にしている)。これらはfilter bankの中心周波数がそれぞれ線形とlog scaleになっている。
以下の図は[7, 8]よりそれぞれ転載。


各スペクトル抽出アルゴリズムの相互関係は以下の図のような関係にある([6]より転載)。

学習可能なスペクトル特徴
「Mel Scaleは恣意的だ」という観点から、SincNet[1]のようにIR Filterのcutoff周波数をデータから学習する手法もある。これはconvolutionによるspectrogramの特徴抽出と比べて圧倒的にパラメータ数が小さくなることから、モデルの収束が早いという利点がある。
以下の2つの図は[1]より転載。1番目の図について、conv filterの場合は1つのfilterで複数の周波数帯を担当していたり、隣接する周波数のfilterゲインが必ずしも連続でなかったりするが、SincNetの場合は1つのfilterにつき1つの周波数帯の特徴を抽出するように制約を加えているので、学習した特徴の解釈性が高いという特徴がある。2番目の図について、話者推定タスクにおいて、SyncNetが学習したFilter Bankに対して、周波数領域でfilterの重みの和をとったもの。人間の話者の声の特徴にであるピッチやフォルマントに対応する周波数にピークがあり、物理的に意味のある特徴を学習していることがわかる。
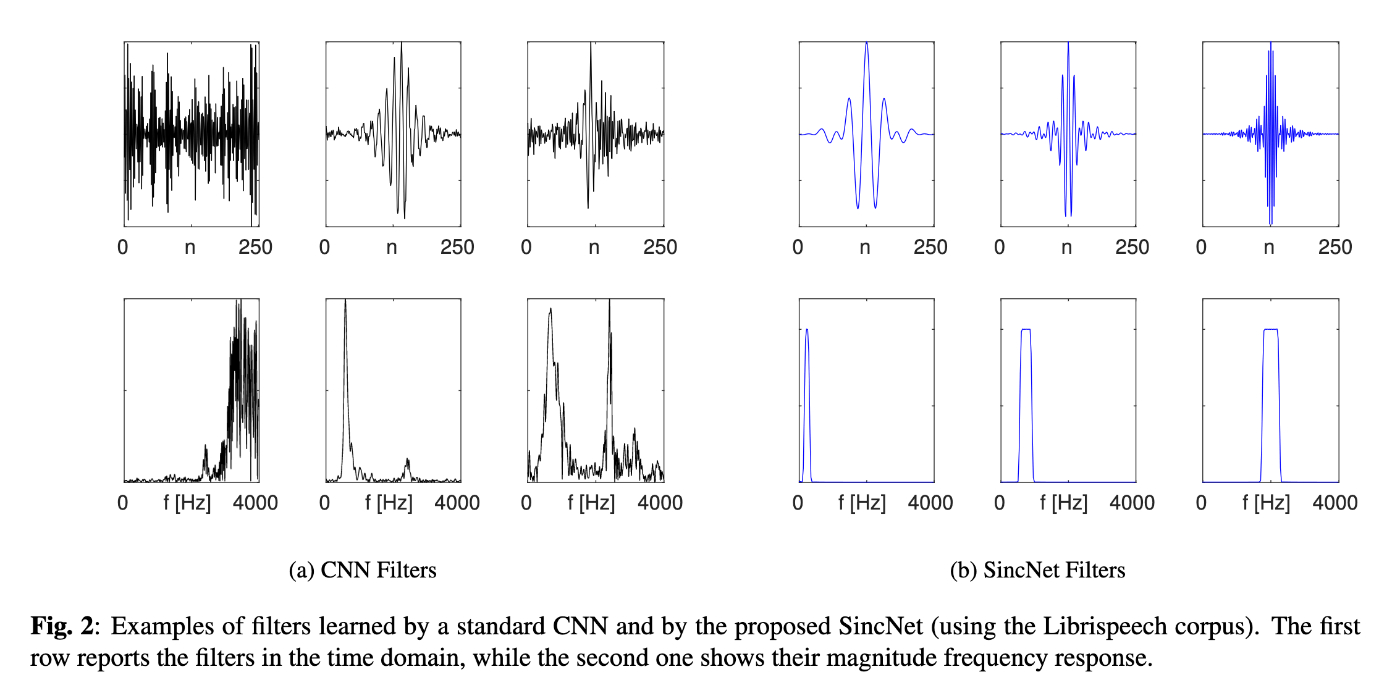
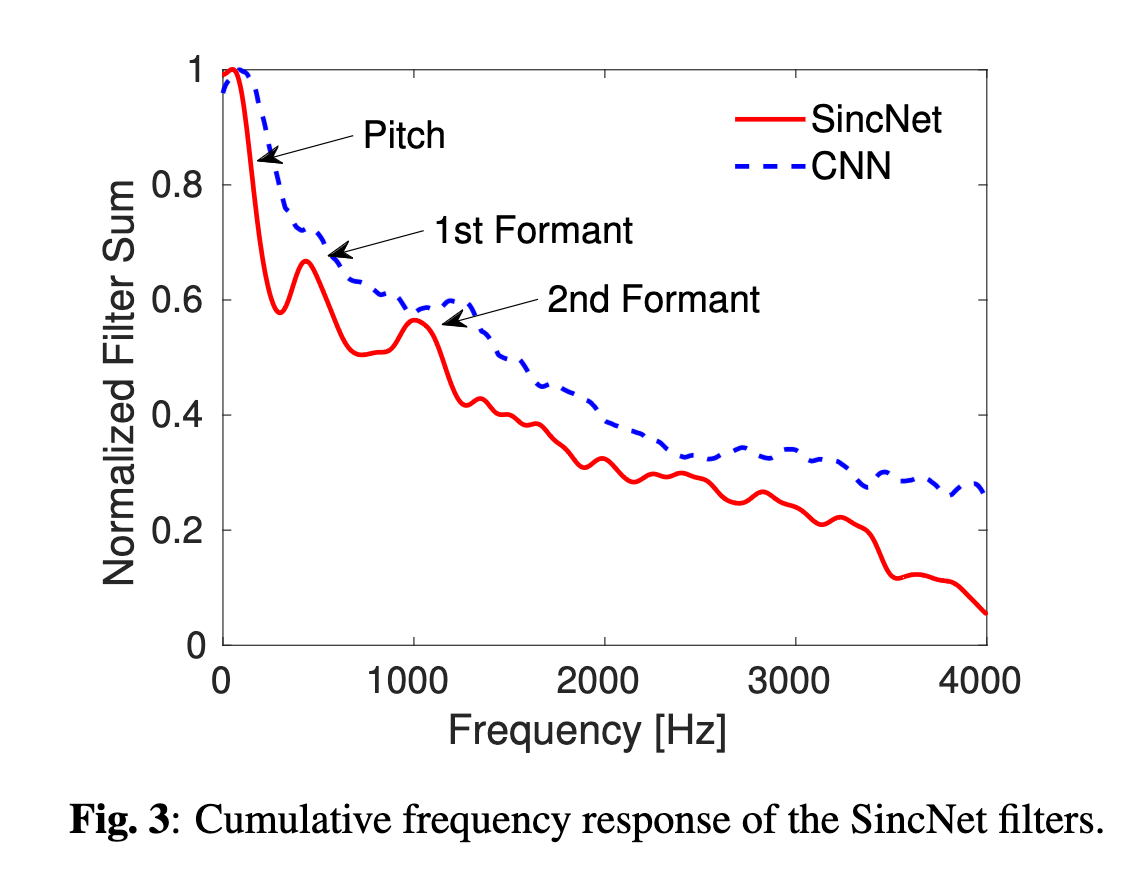
Reference
- [1] Speaker Recognition from Raw Waveform with SincNet
- [2] https://pytorch.org/audio/main/generated/torchaudio.transforms.Spectrogram.html
- [3] https://pytorch.org/audio/main/generated/torchaudio.transforms.MelSpectrogram.html#torchaudio.transforms.MelSpectrogram
- [4] https://pytorch.org/audio/main/generated/torchaudio.transforms.MFCC.html#torchaudio.transforms.MFCC
- [5] https://pytorch.org/audio/main/generated/torchaudio.transforms.LFCC.html#torchaudio.transforms.LFCC
- [6] https://pytorch.org/audio/main/transforms.html
- [7] https://pytorch.org/audio/main/generated/torchaudio.functional.melscale_fbanks.html#torchaudio.functional.melscale_fbanks
- [8] https://pytorch.org/audio/main/generated/torchaudio.functional.linear_fbanks.html#torchaudio.functional.linear_fbanks
従って最初から使用したい周波数帯が決まっているならばMelSpectrogram[3]を使う方が上記の観点から言えば都合が良い。
ソースコード[9]を見ると、単純にSpectrogramとMelScaleを組み合わせているだけ。
つまり(fmin, fmax)を指定しても計算コストの削減にはつながらない。
Issue[10]にも書いたが、Nyqist frequencyよりも欲しい周波数帯が狭い場合は元の系列が新しいNyqist fequencyに収まるようにダウンサンプルすれば良い。
E.g., If we only want 0-20 Hz frequency band, and the original sampling frequency is 200 Hz, we can down sample original sequence for 40 Hz (1/5) and pass it to STFT.
torchaudio側はtorch.STFTのwrapperを実装しているだけなので、こっちで対応するかtorchaudio側で新たに実装しなおさないととどうにもならない。
torch.STFT[12]でもLibrosaの実装[13]でもfmin/fmaxを指定するインターフェースはない。