Open1
FP8精度によるモデル学習
FP8-LM
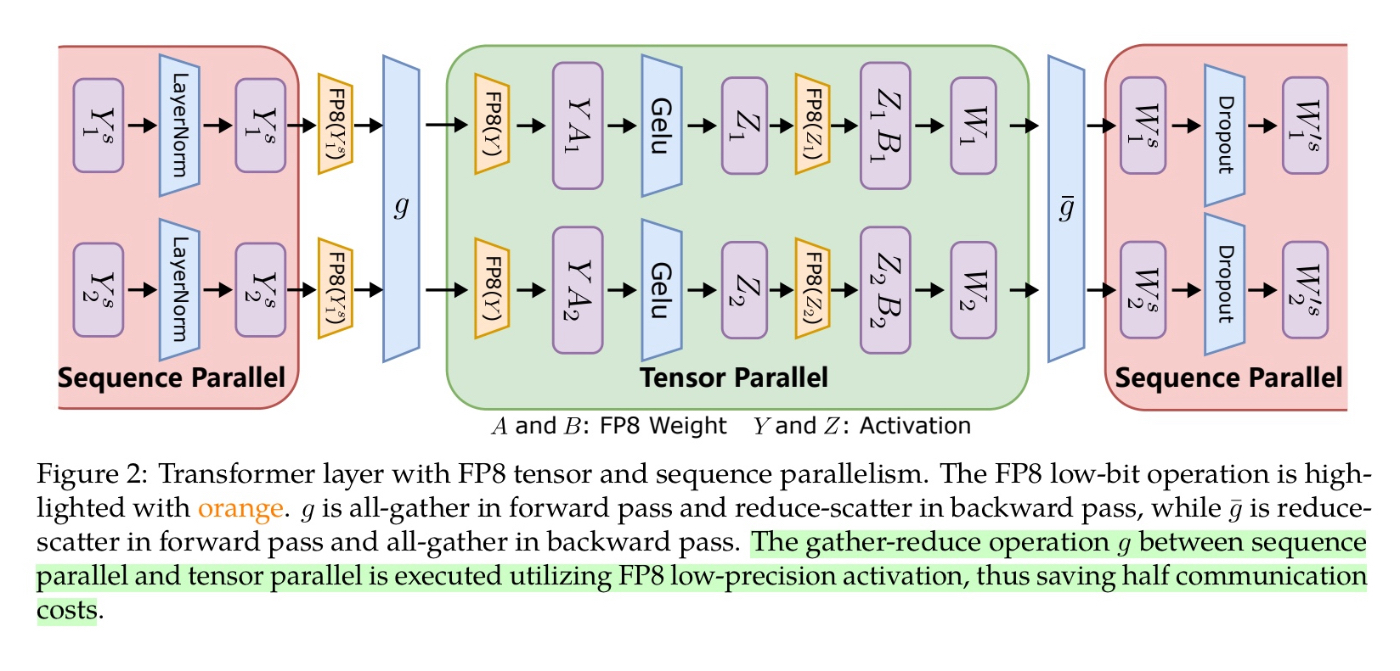
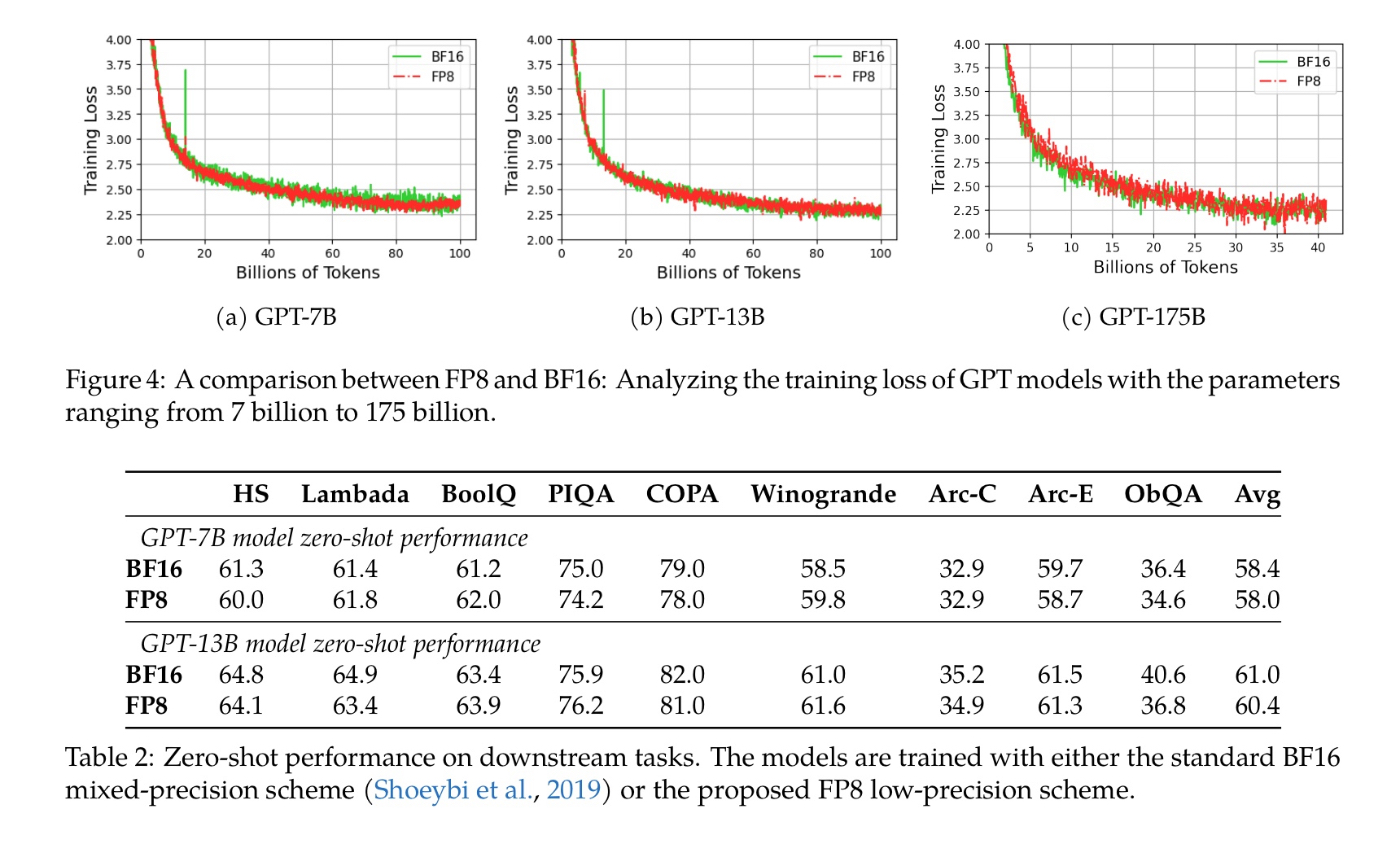
勾配の精度をFP8で量子化によるGPU間のコミュニケーションコストの削減により、NvidiaのTransformer EngineによるFP8の混合精度学習と比較して37%の追加の速度改善を実現。他にもOptimizerの精度のFP8化、FP8の分散学習などの手法を用いている。
TEの混合精度学習は行列計算をFP8で行うが、勾配の計算精度はFP32やFP16で行っている。この論文では勾配計算の精度をFP8にすることでOptimizerのweight分のメモリ削減と、GPU間の転送コストの削減を行なうもの。
所感
これは正しく理解できたか自信がないが、量子化時のスケーリングを全GPUで共通にするのでなく、それぞれ個別のスケーリングファクターを適用することでスケーリングのさいの量子化誤差を抑えることをやっていると理解している。
175Bモデルでも安定して学習できているのはこのためか?