Closed5
vLLM/llama.cppの開発の進行状況
Quantization
vLLM
GPTQ, AWQ, GGUFに対応。
- Implement AWQ quantization support for LLaMA #1032, Sep 16, 2023
- Add GPTQ support #916, Dec 15, 2023
- [Core] Support loading GGUF model #5191, Aug 6, 2024
Llama.cpp
GPTQ, AWQ, GGUFに対応。
- Importer for GPTQ quantized LLaMA models #301, Mar 22, 2023
- GGUF #2398, Aug 22, 2023
- Add AWQ (Activation-aware Weight Quantization) for llama, llama2, mpt, and mistral models #4593, Dec 28, 2023
Speculative Decoding
vLLM
ドキュメントに記載はあるが、「最適化が十分でない」と書かれている。
ドキュメントのリンクにあるIssueはrepo側ではAug 6, 2024に完了しているっぽい。
Issue: https://github.com/vllm-project/vllm/issues/4630#
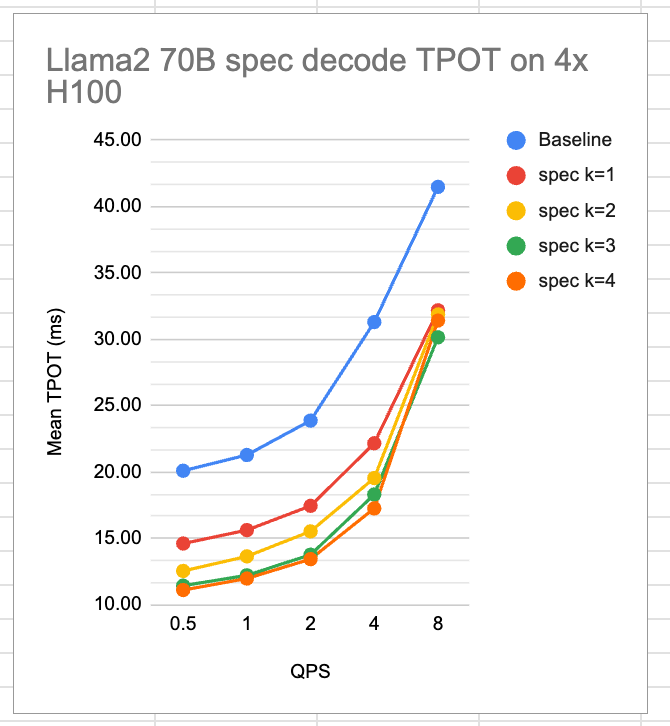
source: https://github.com/vllm-project/vllm/issues/4630#
以下開発時の資料
開発計画:
現時点で全体のタスクのうち6/8が終わっている。
Llama.cpp
機能追加(server):
パフォーマンスが劣化するバグがあるっぽい
Multiple Response
vLLM
対応ずみ。
Llama.cpp
status: TODO
Quantized KV-cache
vLLM
対応している。メモリ消費が約半分になる。現時点での実装ではlatencyの改善は得られない。
ref: https://docs.vllm.ai/en/latest/features/quantization/quantized_kvcache.html#quantized-kv-cache
get Logprobs
vLLM
sampling paramのlogprobで上位n+1を指定する(全部のtoken分取得できるわけではない)
ref: https://docs.vllm.ai/en/stable/api/inference_params.html
このスクラップは2025/02/11にクローズされました