UsearchとFAISSを比較するベンチマーク結果
Unum社は自社製品のUSearchとMeta社のFAISSのベンチマーク結果について報告している[1]。
図1-2は~100MベクトルまでのレンジでUSearchとFAISSのindex構築速度と検索速度を比較したもの。これらによると、1M以下の小さな大きさのベクトル集合に対してはFAISSの方がUSearchを凌駕しているが、それ以降はベクトルの集合の大きさが大きくなるにつれてインデックス構築速度、検索速度ともに急激にFAISSのパフォーマンスが下がっていく。一方でUSearchは100M以下のレンジでは、インデックス構築速度と検索速度ともにベクトルの集合の大きさによらず概ね一定である。100Mの時点でFAISSと比較したUsearchのベンチマーク結果は、インデックス構築速度が19倍、検索速度では189倍のスピードとなっている。
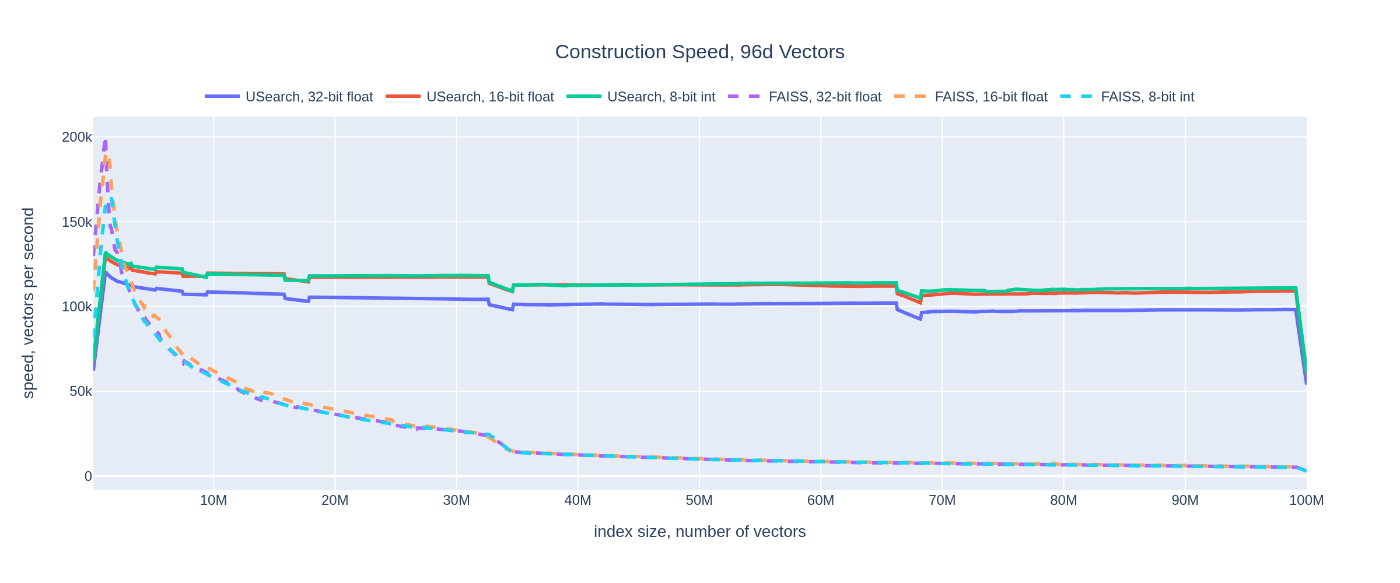
図1: ~100MレンジにおけるUSearchとFAISSのインデックス構築速度の比較([1]より転載)

図2: ~100MレンジにおけるUSearchとFAISSの検索速度の比較([1]より転載)
さらに、同じ96次元のデータセットで〜1BのレンジでのUSearchとインデックス構築速度と検索速度、および検索精度を調査している(図3-5)。このレンジではベクトル集合の大きさが大きくなるについれてインデックス構築速度が緩やかに低下する傾向が見られる(図1)。一方で、検索速度についてはベクトル集合の大きさによらず概ね一定である(図2)。なお、16bit/8bit量子化の検索速度はベクトル集合の大きさが特定のレンジで早くなったり遅くなったりする傾向が見られる。検索精度についてはベクトル集合の大きさに応じて緩やかな低下傾向が見られる。

図3: ~1BレンジにおけるUSearchのインデックス構築速度の推移([1]より転載)

図4: ~1BレンジにおけるUSearchの検索速度の推移([1]より転載)

図5: ~1BレンジにおけるUSearchの検索精度の推移([1]より転載)
記事を読んでて気になったこと
- FAISSもUSearchも同じHierarchial Navigable Small World Graphs(HNSW)[2]という近似近傍探索アルゴリズムを採用しているようだが、速度面の劇的な違いはどこで生じているのか?
- CPUのアルゴリズムの代替手法として、「FAISSの『学習可能な量子化』アプローチ(IVFPQのこと)はポピュラーだがエレガントな解決方法ではない。転置インデックスに基づく検索システムとしては最もトリビアルな設計である。また、スケーラビリティとdistribution shift下(注1)での課題がある」。
- 現行のUSearchのアルゴリズムはCPUを利用したもので、GPUに対応したものはまだない。しかし、記事にもある通り、CPUの方が一般的に搭載メモリが大きく安価であること、GPUメモリは機械学習モデルのために予約しておきたいことを踏まえると、CPUで劇的な高速化を実現したプロダクトは有望そうに思える。とはいえ、USearchもGPUの利用を捨てているわけではなく、「今後の研究開発分野だ」としている。
注1: 要は過学習しやすいということ?
注2: IVF(Inverted File Index), PQ(Product Quantization)
Reference
ANN benchmarksというサイト[3]で色々なツールのベンチマーク結果を比較できる。