GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers (Mar 2023)
paper: GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Mar 2023
Summary
- LLMがデカくなるにつれ、限られたHW推論でさえ難しくなってきている→modelを圧縮する手法が注目されている
- 4bitモデルで初めてFP16と遜色ない性能を実現
- Memory-boundな環境で大きなspeedupが見込める→3.25x (A100), 4.5x (A6000)
- 3bit圧縮: 4bitより若干劣る+OPT familyのモデルではパフォーマンスが安定しないが、~100B程度の大規模モデルでは4bitと同程度の性能
Method
Optimal Brain Quantization(OBQ)という最適化手法の問題を改善した。
Optimal Brain Quantization(OBQ)について
各レイヤーごとに、量子化前後のアクティベーションのノルムを最小化するような量子化重みを計算する手法。目的関数は(1)。
Limitation: 目的関数が2次なので(1)式の解はヘッシアンを使って計算できるが、
提案手法
提案手法GPTQはOBQの以下の問題を解決した。
- 近似解法による計算量の削減: →
O(\max\lbrace d _ \text{row} \cdot d _ \text{col}^2, d _ \text{col}^3 \rbrace) - さらにヒューリスティックな方法で計算量を削減→理論的には計算量は減らないが、実験では~100Bモデルまでモデルサイズに対してほぼ線形の実行時間で計算できた。
- 数値計算が不安定になる問題に対応
Experimental Setup
- Calibration Dataset: C4から2048 tokenのセグメントを128個ランダムに抽出。
結果
PPL
4-bit quantization
GPTQ(4-bit)概ねFP16と遜色ないPPL。モデルサイズを増やすほど差は縮まる。
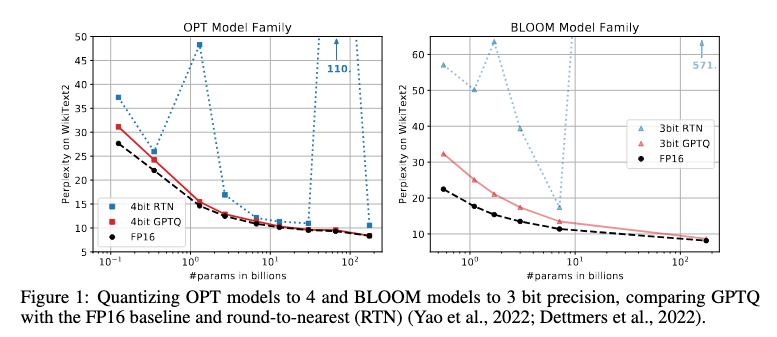
図は論文より引用。
3-bit quantization
OPT Familyのモデルではパラメータ数により性能がまちまちだが、175BではFP16/4bitと遜色ないPPL。
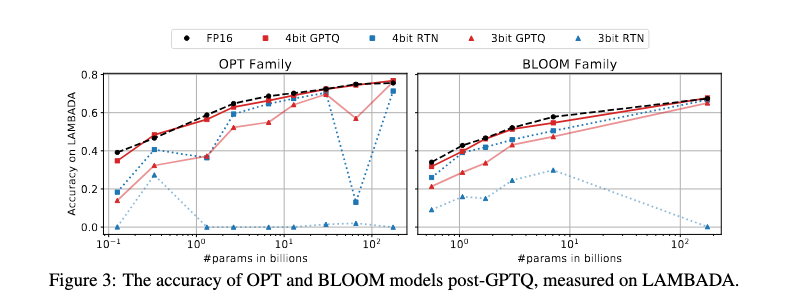
図は論文より引用。
Runtime
For Quantization
量子化された重みの計算時間は175Bまでほぼ線形。

図は論文のTable2を元にグラフにプロットしたもの。縦軸: 量子化にかかった時間(分)、横軸: モデルのパラメータサイズ(B)。A100 x1を使用。
For Text Generation
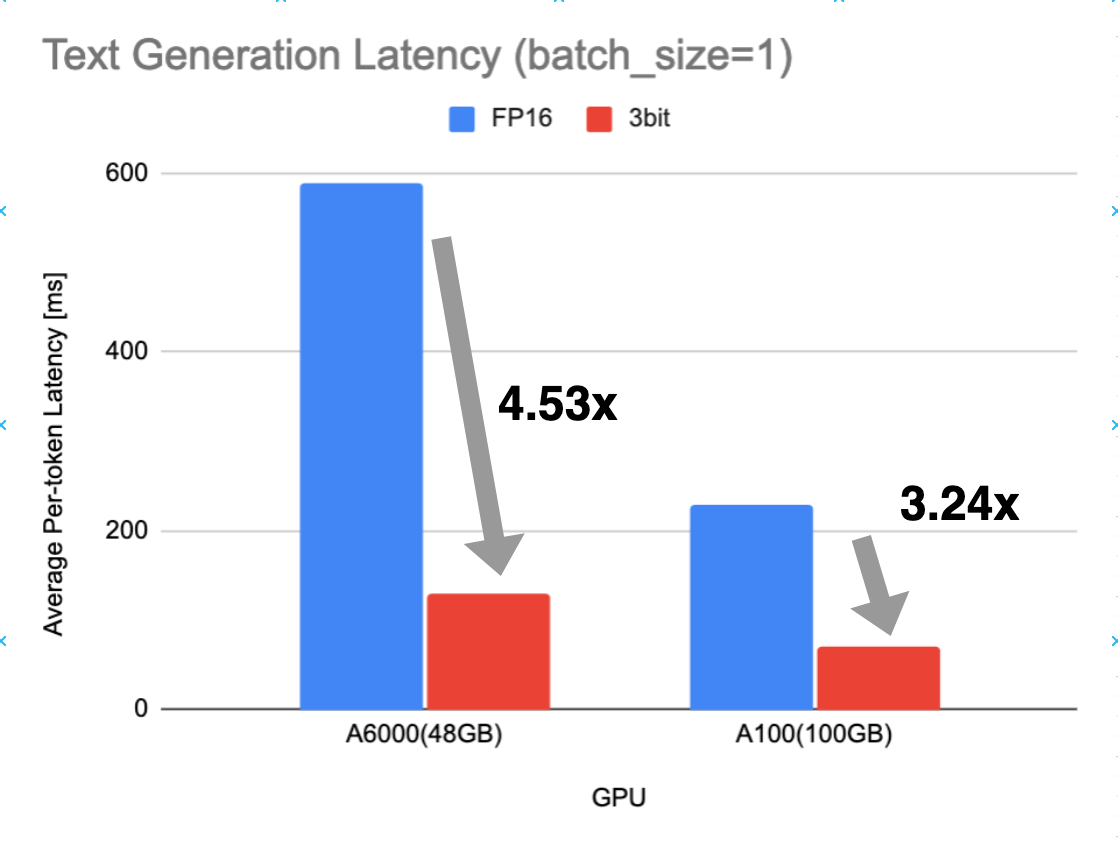
図は論文のTable6を元にグラフにプロットしたもの。横軸: tokenあたりの平均latency(ms)。FP16と3bitでGPU数が異なる。batch_size=1で比較。
参考: GPTQ vs AWQ
- AWQの論文に「GPTQはcalibrationデータセットに過剰適合する可能性がある」と書いてあったが、この主張は妥当だろうか?→最適化するパラメータ数が多い(モデルサイズと同じ)ので、少数のcalibration setに過剰適合するリスクはありそう。
it may overfit the calibration set during reconstruction, distorting the learned features on out-of-distribution domains.
(source: "AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration", pp.2)
AWQの論文の実験によると、GPTQよりAWQの方がout-of domainのcalibration setに対してPPLの増加がロバストという報告がある。→経験的にも主張は正しいっぽい

(source: "AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration", pp.2)
なお、AWQの論文にはruntimeに関するデータは載ってない。grid searchの時間はほぼゼロで、大部分は各層のチャネルごとのactivationの平均値を計算するのに使われる。→forard pathに要する時間 x calibration dataのサイズ?
参考: AutoAWQの場合:
quantize()関数の引数で指定する。
- max_calib_samples=128 (default)
- max_calib_seq_len=512 (default)
所感
GPTQとAWQのアプローチの違い
- 量子化誤差の最小化問題の解法として両者を比較すると、GPTQがHessianを使って真面目に量子化誤差を計算するアプローチなのに対し、AWQはscaleの雑な推定値を使って最小限の計算量で実用的な近似解を得ている。
GPTQを改善できそうな点
言語モデルとしての性能(PPL)
- GPTQはLayerごとの大きな粒度でしかパラメータ調整してないので、より細かい粒度(channel/row/block etc.)ごとにスケールしたらもっと量子化誤差は減らせそう。あとは計算量的にどうか?という感じ。
汎化性能
- GPTQのように量子化重みを直接最適化するアプローチだと「少数データに過剰適合する」というケースは実際にありそう。→元の重みとのKL divergenceを正則化項に加えるとかすれば緩和できるかも。
新規の量子化手法の有望な方向性は?
- 新規手法を開発する場合、推論エンジン(vLLM, Llama.cpp etc.)側で対応が必要なので、明確な性能・速度的なゲインがでない限り主流として使われるのは難しそう。→GGUFのように実装の簡単さを追求するという方向性も。
参考: 現状のモデルの重みの量子化手法の改善方向
- bit rateの最小化: memory-boundな環境でいかにweightのロード時間とメモリ帯域を減らすか?
- PPLの最小化: 言語モデルとしての性能をいかに劣化させないか?
- HWに特化したlatencyの最小化: HWに最適化された実装による行列計算の高速化(e.g. FP4/FP8 matrix multiplication, matrix fusing)
大まかに上記の3つくらいあって、memory-boundな実行環境なら1, 2のみの対応で実用的な旨みが得られるので、そっちが中心な印象。一方で3はHW側、推論エンジン側で対応が必要なため、後回しにされている印象。
あと、1もblockサイズを変える、レイヤごとに量子化サイズを変えるといったナイーブな対応はすぐ対応されているが、高度な情報理論に基づく圧縮手法はよほどゲインがない限り後回しにされている印象→個人的に3bit以上ではナイーブな対応でもかなり最適に近いと思っていて、高度な手法を適用しても正直コスパに見合うのか?問題がある。例外は1.5bit/2bit量子化。