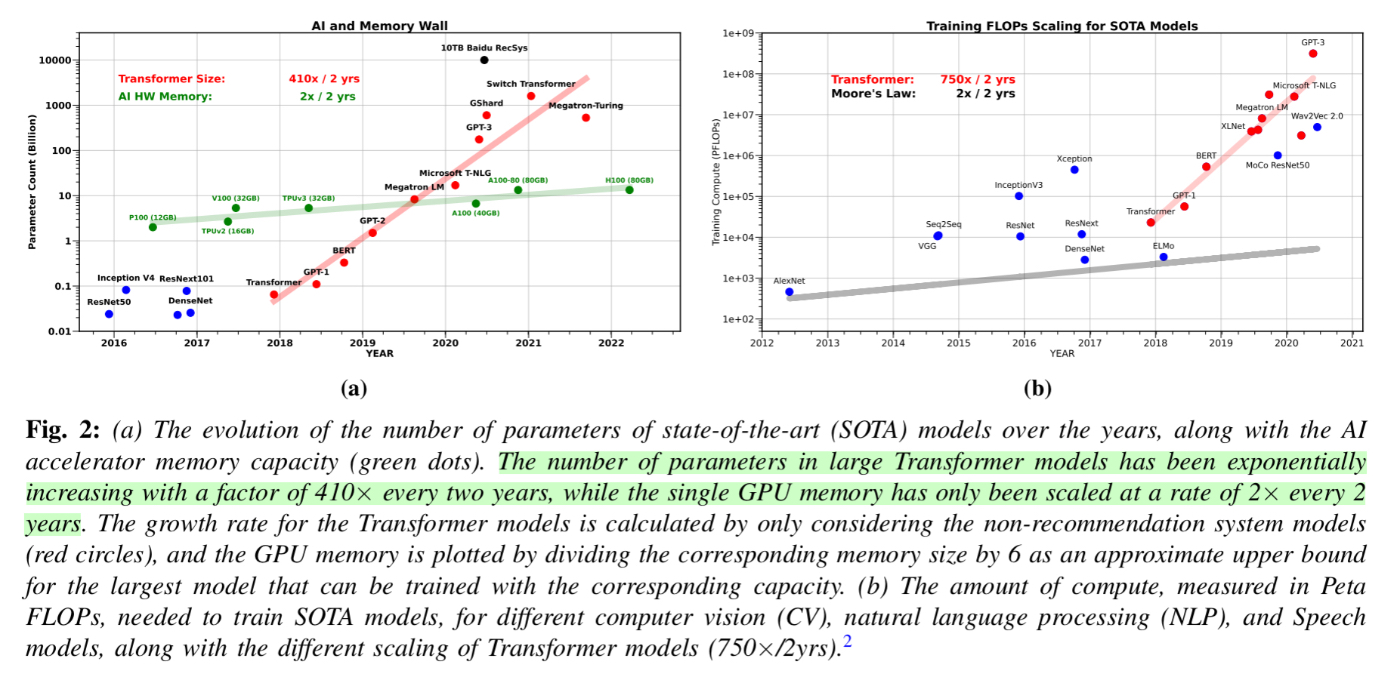
Open2025/02/05にコメント追加2AI and Memory Wall (Mar 2024)bilzardpaperbilzard2025/02/05に更新 学習コストのスケール則はHWのスケール則より遥かに早い HWのメモリがますますボトルネックになりつつある モデル モデルパラメータ: x410/2y 学習コスト: x750/2y HW computing: x3/2y メモリの帯域: x1.6/2y, x1.4/2y https://arxiv.org/abs/2403.14123 返信を追加bilzard2025/02/05参考: DeepSeekV3におけるGPU間の通信速度のボトルネック対策 132個あるSMのうち20個をGPU間/ノード間通信専用に割り当てた 高価なSMに割り当てるのは勿体無いので、将来的な設計ではGPUのコプロセッサに割り当てるようHWベンダに提言している 返信を追加
bilzard2025/02/05に更新 学習コストのスケール則はHWのスケール則より遥かに早い HWのメモリがますますボトルネックになりつつある モデル モデルパラメータ: x410/2y 学習コスト: x750/2y HW computing: x3/2y メモリの帯域: x1.6/2y, x1.4/2y https://arxiv.org/abs/2403.14123 返信を追加
bilzard2025/02/05参考: DeepSeekV3におけるGPU間の通信速度のボトルネック対策 132個あるSMのうち20個をGPU間/ノード間通信専用に割り当てた 高価なSMに割り当てるのは勿体無いので、将来的な設計ではGPUのコプロセッサに割り当てるようHWベンダに提言している 返信を追加