Closed3
InstructGPTで用いられている強化学習手法について
概要
ChatGPT-3.5のベースとなっていると思われるInstructGPT[1]。ここで用いられているRLHF(Reinforcement Learning from Human Feedback)[3]手法の内容について概観する。
PPO(Proximal Policy Optimization)とは?
強化学習におけるpolicy最適化手法の一つで、学習を安定化させるために更新前のpolicyの分布との乖離に対してペナルティを追加する[4]。
InstructGPTにおけるPPOの適用
InstructGPTの論文[1]によると、以下の3ステップで学習している。
- PT(Pre-Training): next token予測
- SFT(Supervised Fine-Tuning): 人間による問答の良し悪しについての評価ラベルを付加し、教師あり学習によりfine tuning
- RL(Reinforcement Learning): 人間の評価を学習した評価モデルを用いて強化学習する
論文では3において2通りのパターンの学習スキームを採用している。
a. PPO: 2で学習したpolicy(
b. PPO-ptx: aのペナルティに加え、pre-training時の確率分布から乖離しないような正則化項を加える。
参考文献
- [1] Training language models to follow instructions
with human feedback - [2] Llama 2: Open Foundation and Fine-Tuned Chat Models
- [3] Deep reinforcement learning from human preferences
- [4] Proximal Policy Optimization
- [5] Trust Region Policy Optimization
- [6] Fine-Tuning Language Models from Human Preferences
RLHFの実装
OpenAIによる公式の実装
- [c1] openai/lm-human-preferences
- InstructGPTの実装ではなく、それよりも以前に出された[6]の実装。
PyTorchによる非公式実装
- [c2] huggingface/trl
- [c3] CarperAI/trlx
- [c4] allenai/RL4LMs
その他の解説資料
論文のまとめ。
強化学習スキームの詳細について説明がある。
LlamaのモデルをStackExchangeの応答データでfine-tuningするハンズオン資料
強化学習の目的関数:
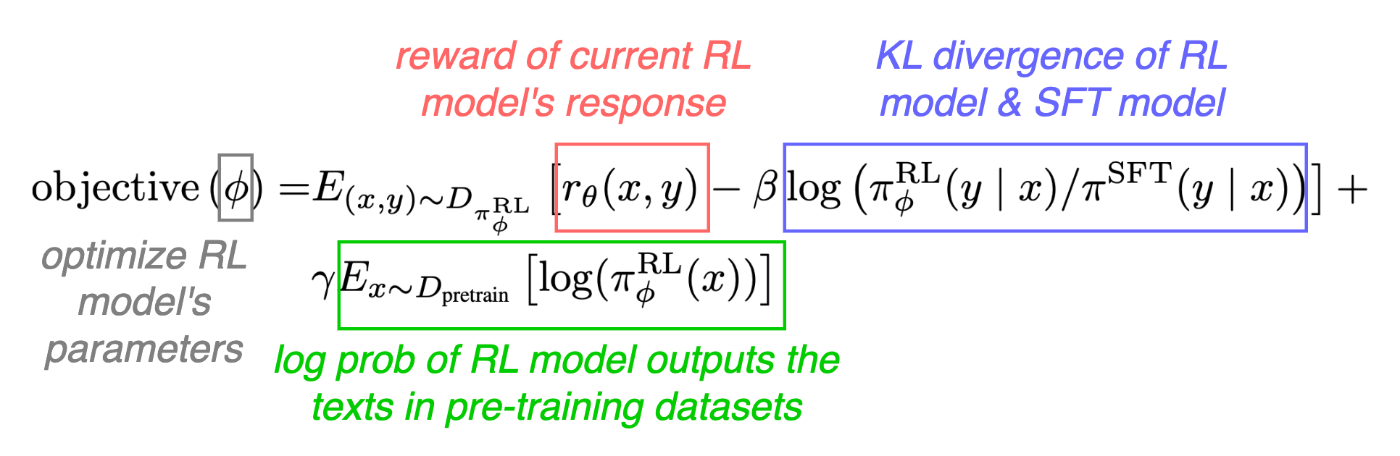
日本語で解釈すると、
学習目的: 以下を満たすようにRLモデルの重みを最適化する
- 評価モデルの報酬を最大化する
- SFTモデルの出力分布との隔たりが大きすぎない
- 事前学習で利用されたテキストにおける出力分布を維持
2は学習の安定化のためのもので、3はfine-tuningにより特定のタスクの性能が劣化する現象(論文内で"alignment-tax"と表現)を抑制するため。
このスクラップは2023/09/27にクローズされました