Text-to-Imageモデルの変遷: DALL·EからStable Diffusionまで
はじめに
本稿では、OpenAIの代表的なtext-to-imageモデルに焦点を当て、DALL·EからStable Diffusionに至るアーキテクチャの変遷を体系的に整理することを試みる。
- DALL·E [2]
- ADM (Classifier Guidance) [1]
- GLIDE (Classifier-Free Guidance) [4]
- DALL·E 2 (unCLIP) [5]
- Stable Diffusion (Latent Diffusion) [6]
狙いとしては、これらのモデルの進化の過程を連続的な軌跡として理解できるようにすることを目指す。
各アプローチの概要
最初に、これらのアプローチの特徴と課題について簡単に述べる。
DALL·E
特徴:
- 自然言語のプロンプトをもとにzero-shotで画像生成を行う、初期の大規模モデルのひとつ
手法:
- decoder-onlyのAutoregressive (AR) Transformerを用いて、text tokenとimage tokenを連結した系列を順に生成することで、テキストによる条件付き画像生成を行う。生成されたimage token列は、事前学習済みのdVAE(discrete Variational AutoEncoder)により高解像度の画像へと復元される。
課題:
- dVAEがデコードした画像はぼやけていたり、細部がうまく再構成できない傾向がある

(source: bilzard)
ADM (Classifier Guidance)
特徴:
- 拡散モデルベースの画像生成手法がFIDスコアにおいて初めてGANベースの手法(例:BigGAN)を上回ったと報告
手法:
- クラス分類器(predictor)を別途学習し、拡散モデルの生成過程にクラスの勾配情報をフィードバックすることで、生成結果を特定のクラスに誘導する(Classifier Guidance)
課題:
- クラス分類器に基づく生成であるため、あらかじめ定義されたクラスに限定され、自然言語などの柔軟なプロンプト指定には対応していない

(source: bilzard)
GLIDE (Classifier-Free Guidance)
特徴:
- Classifier-Free Guidanceという外部predictorを必要としないguidance手法を導入することで、拡散モデルを自然言語プロンプトによって条件制御できるようにした
- 定性評価・定量評価の両方で、DALL·E(初代)よりも高い生成品質を示した
手法:
- 学習時、テキストプロンプトの条件づけを一定確率(GLIDEでは学習サンプルの20%)で無効化し、条件あり/なしの両方のパターンの重みを学習する
- 推論時、条件付き/非条件付きの予測をそれぞれ行い、それらを内挿/外挿することで、テキスト条件への誘導強度を調整する(Classifier-Free Guidance)
課題:
- 複雑な構造や非現実的なオブジェクトの生成に失敗することがある
- GANベースの手法と比べて生成速度が遅い(生成時に多ステップのサンプリングが必要)
- guidance scaleを大きくすると多様性が損なわれやすい
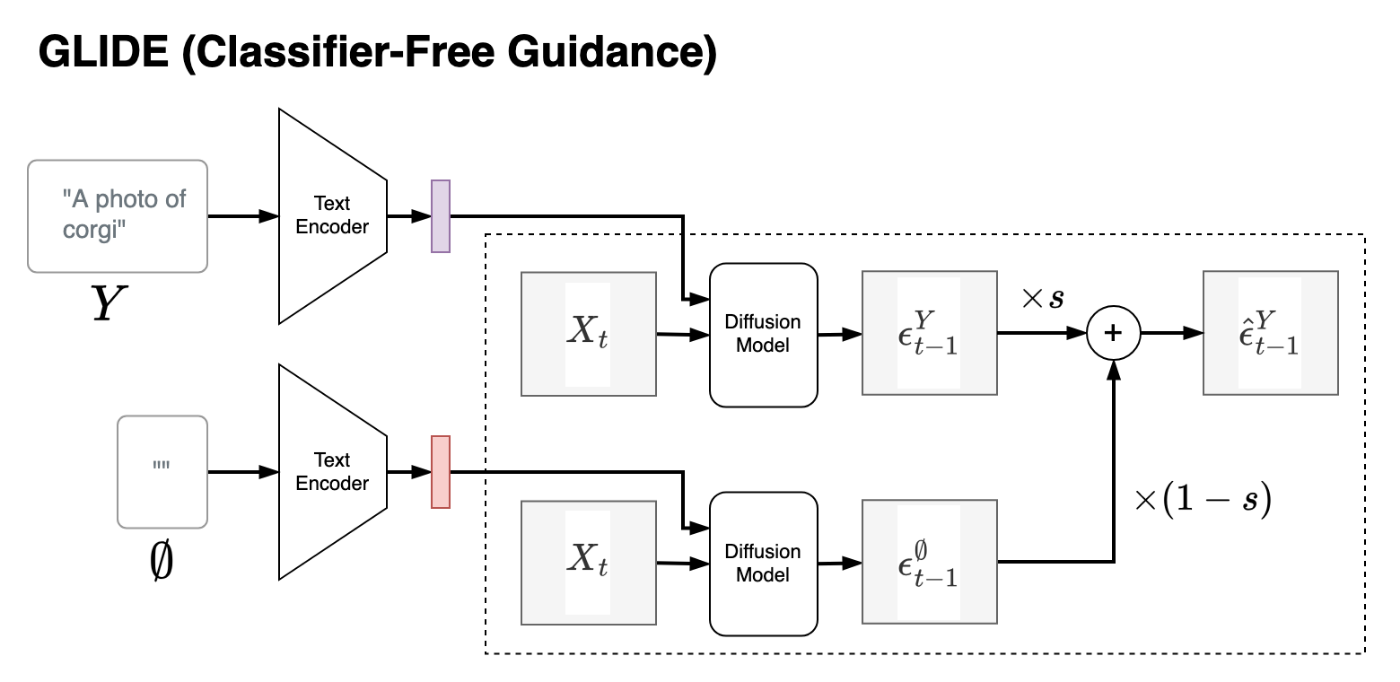
(source: bilzard)
DALL·E 2 (unCLIP)
特徴:
- 生成品質と多様性のトレードオフにおいてGLIDEよりも優位であることが報告された
- GLIDEはguidance scaleを大きくすると多様性が損なわれやすいが、unCLIPでは比較的多様性が保たれる傾向がある
手法:
- text/image encoderにマルチモーダル事前学習済みモデル(CLIP [3])を利用
- priorモデルにCLIPのtext embeddingを入力とした拡散モデルを採用(DALL·EのAR priorと比べて性能が良いことを示した)
課題:
- オブジェクト間の紐付け(例: 「青いキューブの上の赤いキューブ」といった相対的な位置関係など)は生成結果には正しく反映されなかった
- プロンプトで指定したテキストを画像中に出力するのが難しい傾向にある
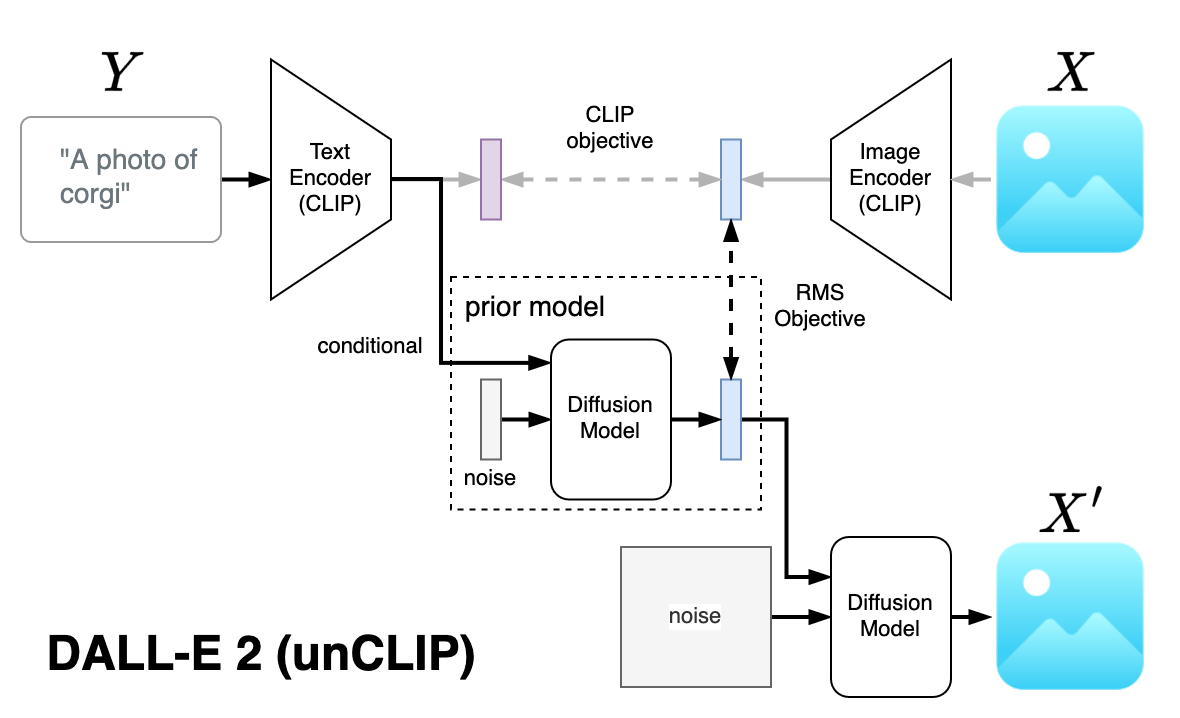
(source: bilzard)
Stable Diffusion (Latent Diffusion)
特徴:
- 高解像度画像の逆拡散過程を直接適用するのではなく、1) 低解像度のlatent feature map上で逆拡散を行い、2) 高解像度の画像にデコードするという2段階アプローチを採用し、学習および推論の計算効率を大幅に向上させた。
手法:
- DALL·E 2と全体の構成が類似している(🐢)が、以下の違いがある:
- DALL·E 2のようなprior(テキスト埋め込み→画像埋め込み)のステージが存在しない
- conditioningにはdecoder-only transformerではなく、encoder-decoder transformerを使用
- DALL·E 2では画像を段階的にアップサンプルする一方で、Latent Diffusionではlatent feature mapをVAE decoderで一度にピクセル空間へ変換する方式を採用している(🐔)
課題:
- 生成品質(FID)においては、GLIDEに若干劣ると報告されている

(source: bilzard)
各アプローチの整理
本章では、前章で取り上げた各モデルのアプローチの違いを、以下の2つの観点から体系的に整理する:
- プロンプトに合わせて生成結果を調整する手法
- 画像のデコード手法
1. プロンプトに合わせて生成結果を調整する手法
Guidance(誘導)
生成過程に介入して出力を誘導する手法。推論時にguidance scaleを調整することで、生成結果がどの程度プロンプトに従うかを制御できるのが特徴。
Classifier Guidance
ADMで採用された手法で、別途学習したクラス分類器の勾配を用いて、特定の条件に沿った出力を促す。
- 利点: 汎用モデル(条件なし)を再利用できるため、導入が容易。
- 欠点: 分類器(predictor)の学習が別途必要で、柔軟な自然言語プロンプトには未対応。推論時にpredictorの勾配計算が必要→計算コストのオーバーヘッドが発生する。
Classifier-Free Guidance (CFG)
GLIDEで採用された手法で、条件付き・非条件付きの出力をそれぞれ計算し、両者を内挿・外挿することでプロンプトへの誘導を行う。
この手法では、あらかじめ 学習時に一定の確率で条件づけを無効化する(例:キャプションを空文字に置換)ことで、条件なし出力を学習する必要がある(GLIDEでは学習サンプル中の20%のキャプションを無効化)。
- 利点: 外部分類器の学習が不要で、柔軟な自然言語プロンプトに対応可能。
- 欠点: 条件付き・非条件付きの両方に対応した生成モデルを新たに学習する必要がある。また、推論時、1サンプリングあたり2回のforward passが必要なため計算コストが高い。

(source: bilzard)
Conditioning(条件づけ)
DALL·E、DALL·E 2、Latent Diffusionで採用された手法で、プロンプトやその埋め込みを直接モデルの入力とする。
- 利点: 推論時にGuidanceのようなオーバーヘッドがなく、計算効率が高い。
- 欠点: 条件付き生成に対応したモデルを新たに学習する必要があり、学習コストは高め。
なお、GuidanceとConditioningは独立した概念であり、両者を併用することも可能である。
2. 画像のデコード手法
Diffusion Model(拡散モデル)
Diffusion Model は、ノイズを段階的に除去して画像を生成する手法であり、高品質な生成結果が得られる。一方で、samplingに複数ステップを必要とするため計算コストが高い。
VAE(変分オートエンコーダ)
初期のDALL·Eでは、dVAE (discrete VAE)が使用されていたが、生成された画像がぼやけていたり、細部の特徴が再現されにくいといった課題が見られた。このため、GLIDEやDALL·E 2では、より高品質な生成を意図して拡散モデルに置き換えられている。
一方で、Latent Diffusionでは高解像度のピクセル表現を得るのにDiffusionベースのUpsamplerの代わりにVAEを採用し、生成品質と計算コストのトレードオフを調整している。また、VAEの品質上の課題に関して、Latent Diffusionではperceptual loss や adversarial objective (敵対的損失) などの補助的な損失関数を導入することで対応している。
所感
以上、DALL·EからStable Diffusion(Latent Diffusion)までのtext-to-imageモデルのアーキテクチャの変遷を振り返った。
調査を進める中で意外だったのは、Stable DiffusionとDALL·E 2のアーキテクチャにそれほど大きな違いがないことだった。それまでStable Diffusionは従来のtext-to-imageモデルとは一線を画す革新的な存在だと捉えていたが、実際にはDALL·E 2に相当するアーキテクチャを誰でも利用できる形で公開したことがStable Diffusionが急速に普及した大きな要因だと感じた。
アーキテクチャの体系的整理を通じて、text-to-imageモデルの進化を連続的な軌跡として捉えるという当初の目的はおおむね達成できたと考えている。
今後、同様の技術を調査・整理する際の参考になれば幸いである。
References
- [1] Diffusion Models Beat GANs on Image Synthesis, 1 Jun 2021, https://arxiv.org/abs/2105.05233
- [2] Zero-Shot Text-to-Image Generation, 26 Feb 2021, https://arxiv.org/abs/2102.12092
- [3] Learning Transferable Visual Models From Natural Language Supervision, 26 Feb 2021, https://arxiv.org/abs/2103.00020
- [4] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models, 8 Mar 2022, https://arxiv.org/abs/2112.10741
- [5] Hierarchical Text-Conditional Image Generation with CLIP Latents, 13 Apr 2022, https://arxiv.org/abs/2204.06125
- [6] High-Resolution Image Synthesis with Latent Diffusion Models, 20 Dec 2021, https://arxiv.org/abs/2112.10752
Discussion