[survey] 近年のLLMに関する提案手法について
本Surveyの目的
近年LLMの学習や推論に関するさまざまな新しい手法が提案されている。本surveyではこれらの手法を外観することで、近年のLLM研究のキャッチアップを容易にすることを目的とする。また、これらの手法で用いられたアイデアの幾つかはLLM以外の言語モデルや、言語以外のドメインにおいても転用できるものもあると信じている。
LLMに関する提案手法の外観
以下の観点でまとめる。
- アーキテクチャの改善に関する手法
- 事前学習の安定性に関わる手法
- 事前学習の高速化に関わる手法
- 推論の高速化に関する手法
- Decode手法
- 解釈性に関する手法
注意事項として、今までに自分が読んだ論文を中心にまとめているため網羅的なsurveyとはなっていない。また、fine-tuningに関わる手法については提案された手法の多さと比較して自分の調査した範囲が不足していると考えたためこのsurveyからは除外した。
アーキテクチャの改善に関する手法
外挿可能なPositinal Encoding
訓練時よりも長い系列を推論時に扱える性質が好ましいことから、外挿可能なPEの手法が提案されている。
RoPE[1]
代表的なアーキテクチャ:
- GPT-NeoX[3]
- PaLM[5]
XPos[2]
代表的なアーキテクチャ:
- Retentive Network[4] (どちらかというとproof of concept)
Context長の増加に関する手法
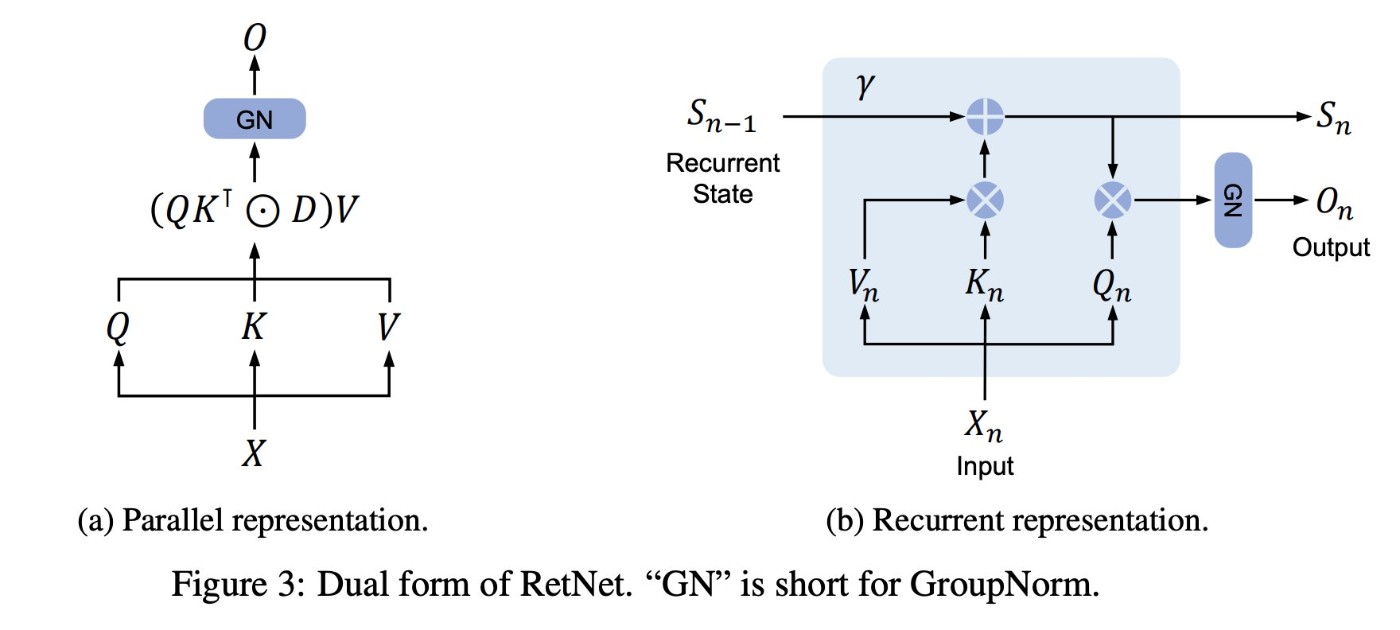
Retentive Network[4]
Transformerに替わる大規模言語モデルの基盤アーキテクチャの提案。提案手法は6.7Bまでのモデルまでで性能を犠牲にせずにO(1)での推論コストで実現できることを経験的に示し、Transformerの課題である長いコンテクスト長の処理に適することを示した。この論文では、Recurrent形式からTransformer形式が理論的に導けることを示し、訓練時と推論時でそれぞれ等価なTransformerとrecurrent形式で処理することで、訓練時の並列処理と推論時のO(1)での処理をともに実現した。
事前学習の安定性に関する手法
QK normalization
attentionを計算する前のQ, Kのembeddingを正規化する手法。ViT-22B[6]の論文によると、既存のnormalization手法だと8Bパラメータ付近でattentionのlogitに極めて大きな値が入るようになり、学習が不安定になったことから導入した。この手法で8Bモデルの学習が不安定になる問題は回避されたとのこと。
事前学習の高速化に関する手法
Parallel layers
QKVとFF層の最初の線型変換の計算を一度に行うことで並列処理によるスループットの増加を意図した手法。GPT-NeoX-20B[3], PaLM[5], ViT-22B[6]で使われている。

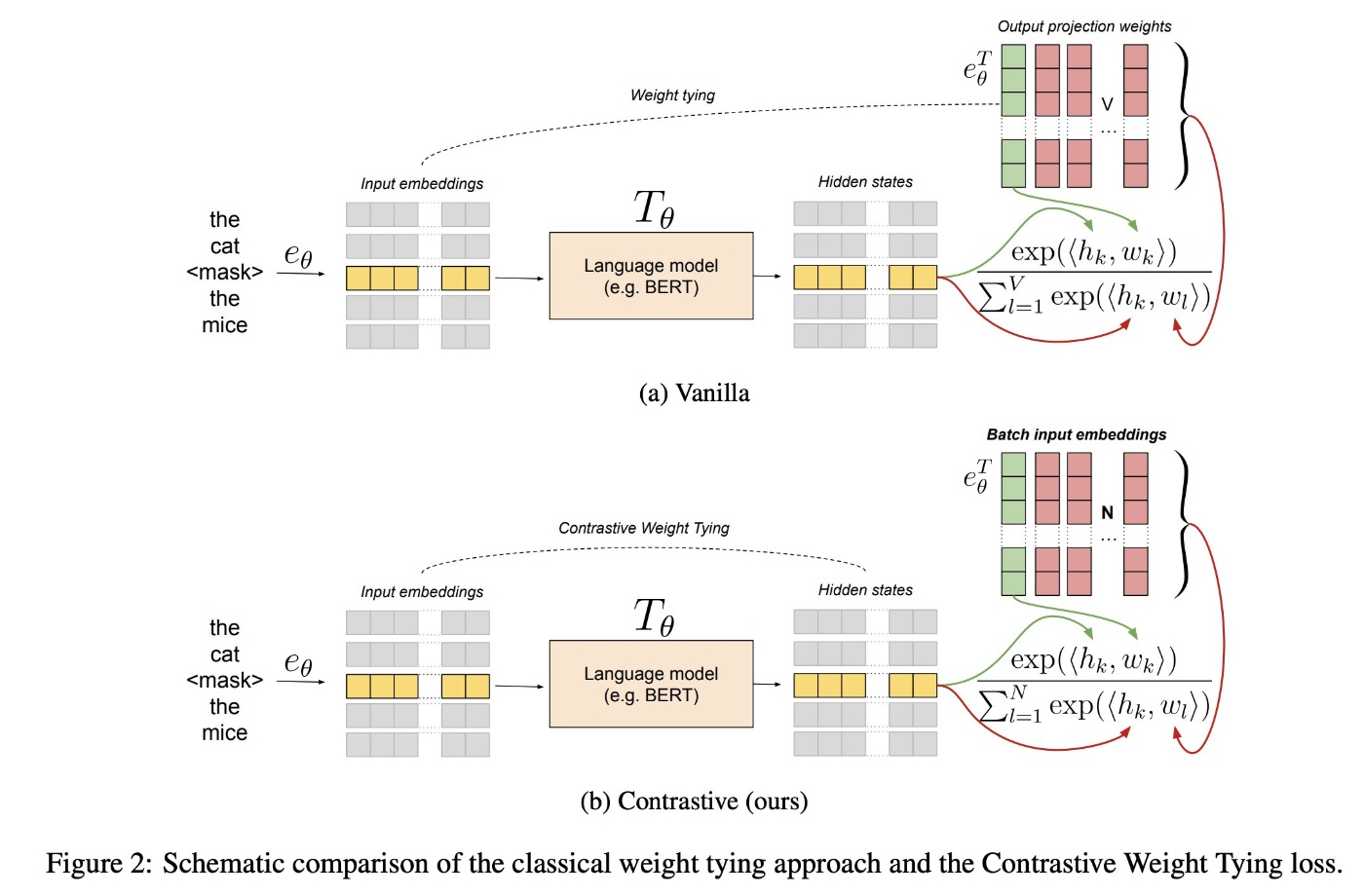
Headless Language Modeling[9]
言語モデルの事前学習において最終層のprojectionとsoftmaxの計算に多くのメモリを消費する。提案手法はheadを取り払い、入力系列のembeddingを復元する形式の学習タスクに置き換えることで、訓練時間とメモリ消費を削減するというもの。
推論の高速化に関する手法
Early Exiting[11]
Transformerの中間のレイヤのactivationにclassifierを適用して後続のレイヤの伝播を省略し、推論時の高速化を図る手法。 Residual接続により、Boostモデルのように「レイヤが深くなるにつれて漸近的に正確な予測を生成している」という仮説に基づく。

Decode手法
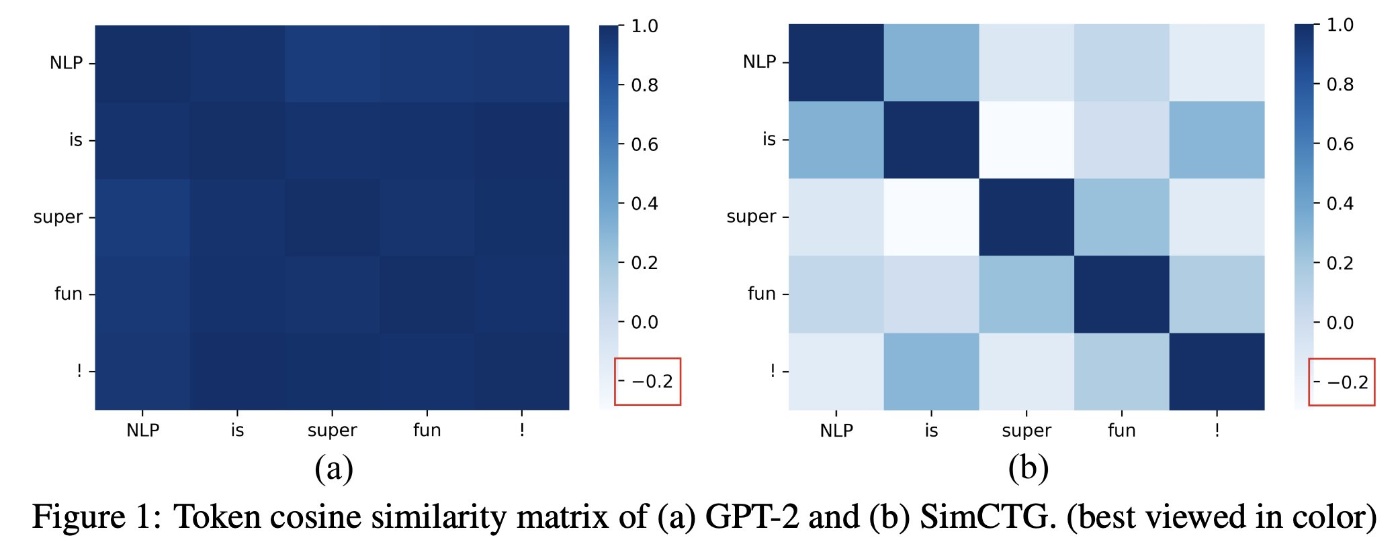
SimCTG, Contrastive Search[7]
確率を最大にするタイプのdecoding手法では生成されたテキストが不自然だったり、表現の繰り返しが多用されることが知られている。本論文はこの原因が生成文中のトークンのembeddingが非常によく似ていることに起因することに着目し、以下のの2つのアプローチを提案した:
- 学習時: 文中の過去のトークンと現在のトークンのembeddingの類似度が異なるようにする対照損失を目的関数に加える(SimCTG)
- 生成時: 予測トークンの確率に過去のトークンと現在のトークンとの類似度をペナルティとして加える(Contrastive Search)
Contrastive Decoding[8]
パラメータ数の大きな熟練したモデル(expert)のトークンの対数確率の分布からパラメータ数の小さな未熟なモデル(amateur)のトークンの対数確率分布を引くことで、より一貫した内容のテキストを生成することを意図したdecode方式。パラメータ数の小さなモデルの方が表現の繰り返しの頻度が多いことから経験的に導かれた。
本手法と類似のdecoding手法を用いた研究[10]ではモデルの解釈性との関連においても注目がされている。また、本手法を用いて実際に論理的推論を要求するとされるタスクの性能が改善したという報告もある[13]。

解釈性に関する手法
DoLA[10]
LLMに「事実に基づいた推論」をさせることを意図した論文。「層が深くなるにつれて、中間層に存在する事実に関する知識を利用して推論を行うようになる」という仮説をもとに、Contrastive Decoding[8]と同様の手法により中間のレイヤでearly exit[11]した推論結果を「単純なパターンに基づく推論」と仮定し、最終層の推論結果のトークン対数確率分布から中間層の推論結果のトークン対数確率分布を引くことで「単純なパターンに基づく推論を減らし、より事実に基づく推論」を行えると主張している。

Inference-Time Intervention[12]
画像生成モデルのstyle transferの要領で、潜在空間上で特定の方向にシフトすることでLLMの生成テキストの「編集」を行う手法がいくつか提案されている。提案手法では訓練サンプルからテキストの「真実性」に関わるembedding空間上の方向を学習し、推論時に「真実性」を増やす方向にembeddingを移動させる。「生成結果が人間にとって望ましいものでなくても、潜在空間上では『真実性』を判別する境界がある」という既存研究の成果を掘り下げたもの。生成されたテキストからのみではLLMが蓄えている「知識」を適切に評価できるとは限らないことを示唆する。
参考文献
- [1] RoFormer: Enhanced Transformer with Rotary Position Embedding
- [2] A Length-Extrapolatable Transformer
- [3] GPT-NeoX-20B: An Open-Source Autoregressive Language Model
- [4] Retentive Network: A Successor to Transformer for Large Language Models
- [5] PaLM: Scaling Language Modeling with Pathways
- [6] Scaling Vision Transformers to 22 Billion Parameters
- [7] A Contrastive Framework for Neural Text Generation
- [8] Contrastive Decoding: Open-ended Text Generation as Optimization
- [9] Headless Language Models: Learning without Predicting with Contrastive Weight Tying
- [10] DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
- [11] Early Exiting BERT for Efficient Document Ranking
- [12] Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
- [13] Contrastive Decoding Improves Reasoning in Large Language Models
Discussion