ConformerからSqueezeFormerへのアーキテクチャの変更点について
はじめに
SqueezeFormer[1]は自動音声認識(Automatic Speech Recognition; ASR)タスクにおいて、Conformerの構成変更を試みたもの。Macro/Micro Architectureの変更からなる。以下各節で順を追って変更点を確認していく。
(基本的には原著[1]の内容を確認していくだけ)
Macro Architecture
1. Temporal U-Net
オリジナルのConformerは各層でサンプリングレートが40ms(25Hz)で一定だった。
Transformerは計算量が系列長の2乗に比例して増加するので、系列長を短くすることで計算量を抑えることができる。
著者らはConformerにおける隣あう系列同士の類似度を計算し、隣接したembeddingは平均で95%の類似度があり、4frame離れたembeddingでも80%とかなり時間方向に冗長性があることを特定した。
We observe that the embeddings for the speech frames directly next to each other have an average similarity of 95% at the topmost layer, and even those 4 speech frames away from each other have a similarity of more than 80%. This reveals that there is an increasing temporal redundancy as inputs are processed through the Conformer blocks deeper in the network.
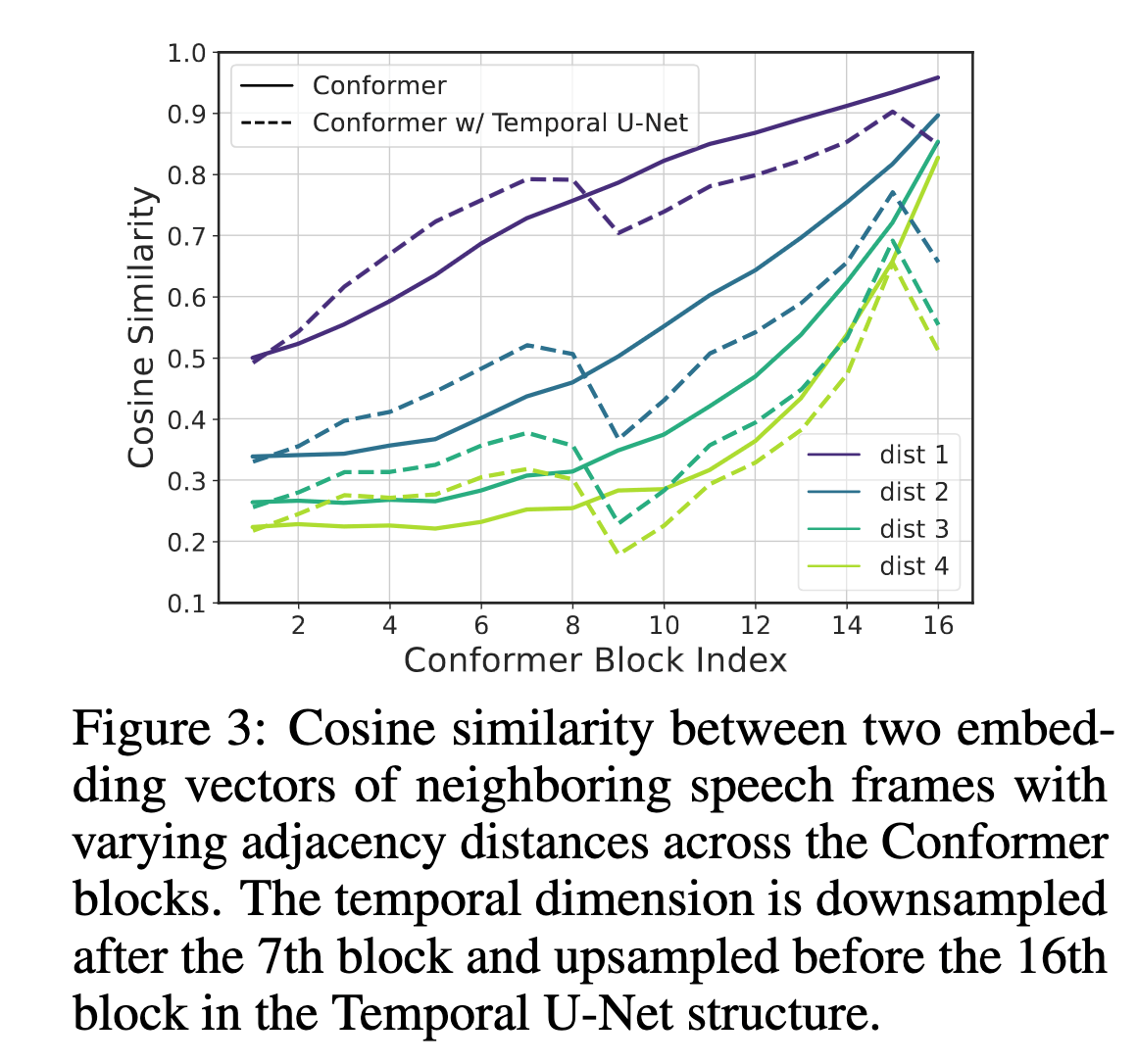
この知見をもとに、SqueezeFormerでは7層目までは40msで処理し、それ以降の層では80ms(12.5Hz)にダウンサンプルする構成とした。
しかしながら、著者らによると、down samplingのみでは学習が安定しなかったとのこと。
ASRタスクは音声入力からテキストを生成するタスクなので、時間方向の解像度を保ったままエンコーディングすることが重要ととなる。
これに対し、画像分野における同様な要件であるセグメンテーションタスクで成功を収めたU-Netの構成を採用することで解決した。
最終的にConformerと比べて20%のFLOP数の減少と同時にWERで0.62%の改善を実現した。
This change not only reduces the total FLOPs by 20% compared to Conformer1, but also improves the test-other WER by 0.62% from 7.90% to 7.28% (Tab. 1, 2nd row).

2. Transformer-Style Block
アーキテクチャの基本構成要素にも変更を加えている。ConformerではFF->MHA->Conv->FFという順番でブロックが並んでいるのを、MHA->FF->Conv->FFというTransformerの初期構成っぽい並び順に変更した。
音声認識タスクではkernel sizeが31と画像タスクに比べて大きいのが特徴で、これはMHAによるglobal attentionと機能分担的に重複する。従って、ConformerのようにMHAの直後にConvを配置するアーキテクチャは賢明ではないように思えると著者らは指摘している。
Note that the convolutional kernel sizes in ASR models are rather large, e.g., 31 in Conformer, which makes its behaviour similar to attention in mixing global information. This is stark contrast to convolutional kernels in computer vision, which often have small 3 × 3 kernels and hence benefit greatly from attention’s global processing. As such, placing the convolution and MHA module with a similar functionality back-to-back (i.e., the MC substructure) does not seem prudent.
(所感)Conformerではlayerを跨いでFFが2回連続しているから、その意味でも妥当な構成変更のように思える。

Micro Architecture
1. Unified Activation
単純にconformerでは異なる種類のactivationレイヤーが1つのアーキテクチャ内に混在しており、意味がないから1種類にまとめた。著者らによると、エッジデバイスにデプロイする際にactivationが1種類の方が効率的に処理できるとのこと。
2. Simplified Layer Normalizations
ConformerのBasic Blockをみると、layerを跨ぐ前後でPost LNの直後にPreLNが配置されており、冗長であるように思われる。
ところが、著者らによると、ナイーブにPreLNやPostLNのいずれかを除去するだけでは学習が不安定になったり、発散する問題があったとのこと。著者らはこの原因を調査し、典型的なConformerの学習結果ではresidual pathとskip pathの信号のスケールに大きな差異があり、PreLNが両者のスケール差を緩和する役割があることを特定した。Activationのscalingの重要性についてはnormalizationを使わないNNであるNFNet[2]や1000レイヤに及ぶ多層のNNであるDeepNet[3]でも学習を安定させるための手法として採用されている。
Investigating the cause of failure, we observe that a typical trained Conformer model has orders of magnitude differences in the norms of the learnable scale variables of the back-to-back preLN and postLN. In particular, we found that the preLN would scale down the input signal by a large value, giving more weight to the skip connection. Therefore, it is important to use a scaling layer when replacing the preLN component to allow the network to control this weight.
この知見をもとに、SqueezeFormerではConformerのPreLNを学習可能なScalingブロックで置き換えている。

3. Depthwise Separable Subsampling
音声信号を扱う機械学習モデルを設計したことのある人なら経験したことがあるかもしれないが、生の音声データは系列長が非常に長いため、機械学習モデルの計算量の大部分は入力部分に消費されていることが多い。
著者らによれば、Conformer-CTC-Mのモデルの30秒の入力では全体のFLOP数の28%が入力層の2層の畳み込みで消費されているとのこと。
While it is easy to overlook this single module at the beginning of the architecture, we note that it accounts for a significant portion of the overall FLOPs count, up to 28% for Conformer-CTC-M with a 30-second input. This is because the subsampling layer uses two vanilla convolution operations each of which has a stride 2.
SqueezeFormerでは入力層の2層の畳み込みをDepthwise Separable Convolutionに置換することで、性能を落とすことなく22%の計算量を削減することに成功した。
感想
闇雲にアーキテクチャの変更を試すのではなく、原因を特定した上で改善していくと言う姿勢が参考になった(研究分野なので当然といえば当然だが)。最近の(時)系列タスク系のコンペのtop解法でもよく見かける(Appendix. A1)ので、一度触っておきたいアーキテクチャではある。
Reference
- [1] Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
- [2] High-Performance Large-Scale Image Recognition Without Normalization
- [3] DeepNet: Scaling Transformers to 1,000 Layers
Appendix
A1. 直近のKaggleコンペのTop solutionにおけるSqueezeFormerの採用状況について
時系列処理系のタスクのTop solutionでよく見かける。
ASLのようなSeq2seqタスクだけでなく、通常のclassificationタスクでもよく見る。
Stanford Ribonanza RNA Folding
- 2nd place solution - Squeezeformer + BPP Conv2D Attention
- [3rd Place Solution] AlphaFold Style Twin Tower Architecture + Squeezeformer
Discussion