Object Detectionタスクにおけるpost-processing手法について
概要
Object Detectionタスクにおけるpost-processing手法について、最近読んだ論文の内容に基づいて以下の内容を解説する。
- GT boxが混み合った状況でシーンにおけるGTラベルの混雑度(density)をモデル化してそれに基づいて事後処理におけるIoU thresholdを動的に決定する手法[1]
- 提案boxのまとまりをよくするための補助的な損失関数を導入する手法[5]
- 一貫性のないboxラベルの悪影響を抑制するために、boxのuncertaintyを確率的にモデル化して回帰する方法、および学習したuncertaintyを事後処理におけるboxの精度の評価値の計算に利用する手法[2]
Adaptive NMS
GT boxが混み合った領域で適切にFPを間引く
[1]はPedestrian Detection(歩行者検出)タスクに特化したNMS(Non-Maximum Suppression)アルゴリズムのバリエーションを提案した。
pedestrian detection(PD)タスクは、公共のシーンの画像から歩行者の存在するbox領域を検出するタスクで、一般的なobject detection(OD)タスクに比べて、targetの重なりが多いことが特徴である。
NMSでは固定のIoU thresholdによってmaximum confident box(以降 MCB と呼称)周辺周囲の間引くかどうかを決定するが、
PDタスクでこのようなルールベースを用いると、群集が多く重なり合っているシーンでは本来正解とするべき提案boxも間引いてしまうという問題がある。
これに対し、[1]はanchor周辺のシーンのGT boxの density(=混雑度) を推定するheadを新たに学習し、boxのconfidenceと合わせて、混雑度に応じて動的にIoU thresholdを決定する手法を提案する。
具体的には以下のようにして動的にIoU thresholdを決定する。
表記について、
つまり、混雑度が閾値以下の場合は通常のNMSと同じように振る舞い、混雑度が閾値以上の場合は混雑度自体を閾値とし、間引きの度合いを混雑度に応じて緩和する。
なお、本手法はSoft-NMS[4]にも適用可能で、Soft-NMSの場合は以下のようにしてboxのスコアを更新する。
表記について、
densityの回帰head は1) classの予測結果, 2) box座標の予測結果, 3) feature mapの3つのplaneを元にして浅いconvolutionレイヤーで回帰する構成になっている(図1)。
各GT boxごとのdensityラベルは以下のように定義する。
表記について、
すなわち、他のGT boxの重なりの最大値により定義する[1]。
[1]によると、提案手法はdensityが小さい領域(<0.4)ではNMSと同等の性能を示し、densityが大きくなるほど提案手法が既存手法よりMiss Rate(MR; 小さいほど良い)が小さくなることを示した(図2)。
また、GT boxのocclusion(=重なり)ごとの提案手法の有効性を調査した結果によるとAdaptive-NMSと後述するAggLossという手法を共に用いてCityPersonsデータセットのReasonableカテゴリ(occlusionが35%未満のGT)の予測性能が改善したことを示しており、GT boxが混み合った状況に対して提案手法が実際に有効であったことを示している。
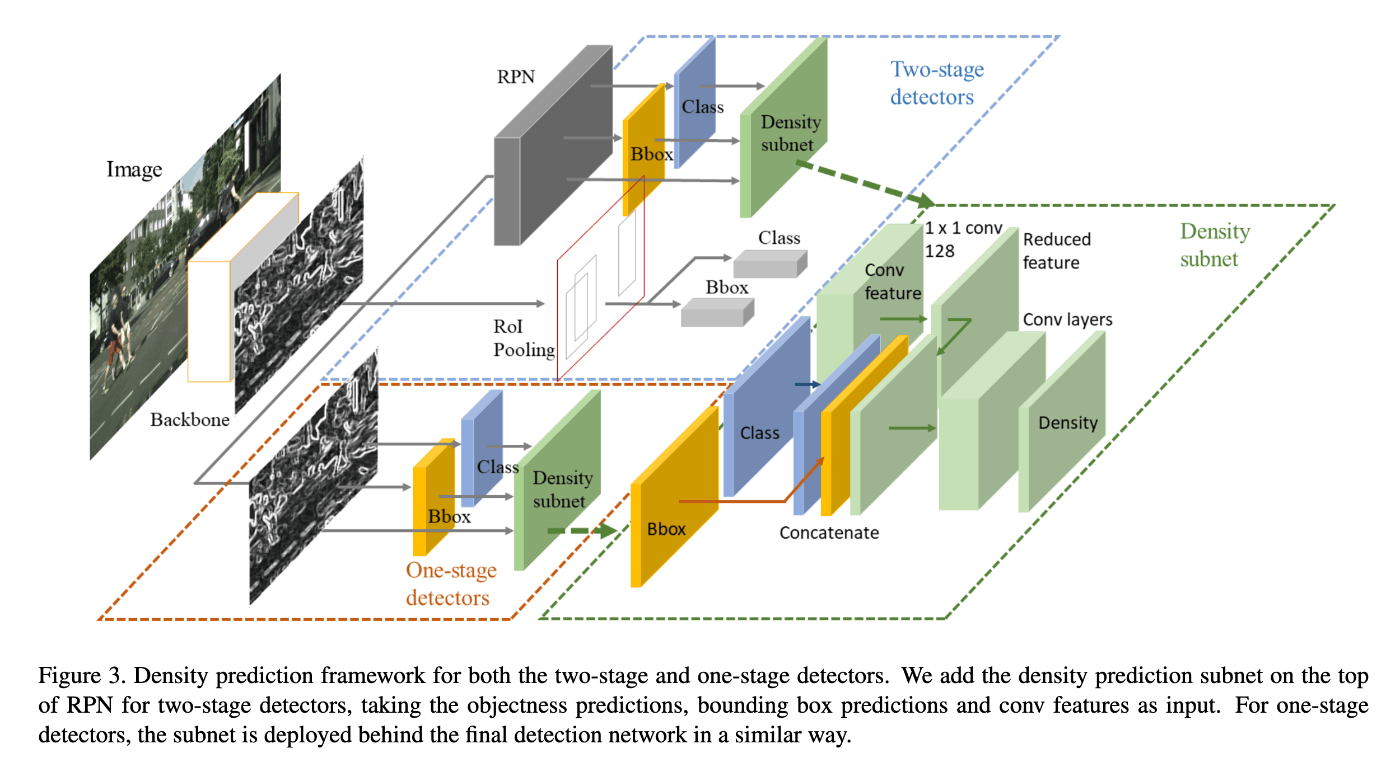
図1. density prediction headの構成 ([1]より転載)
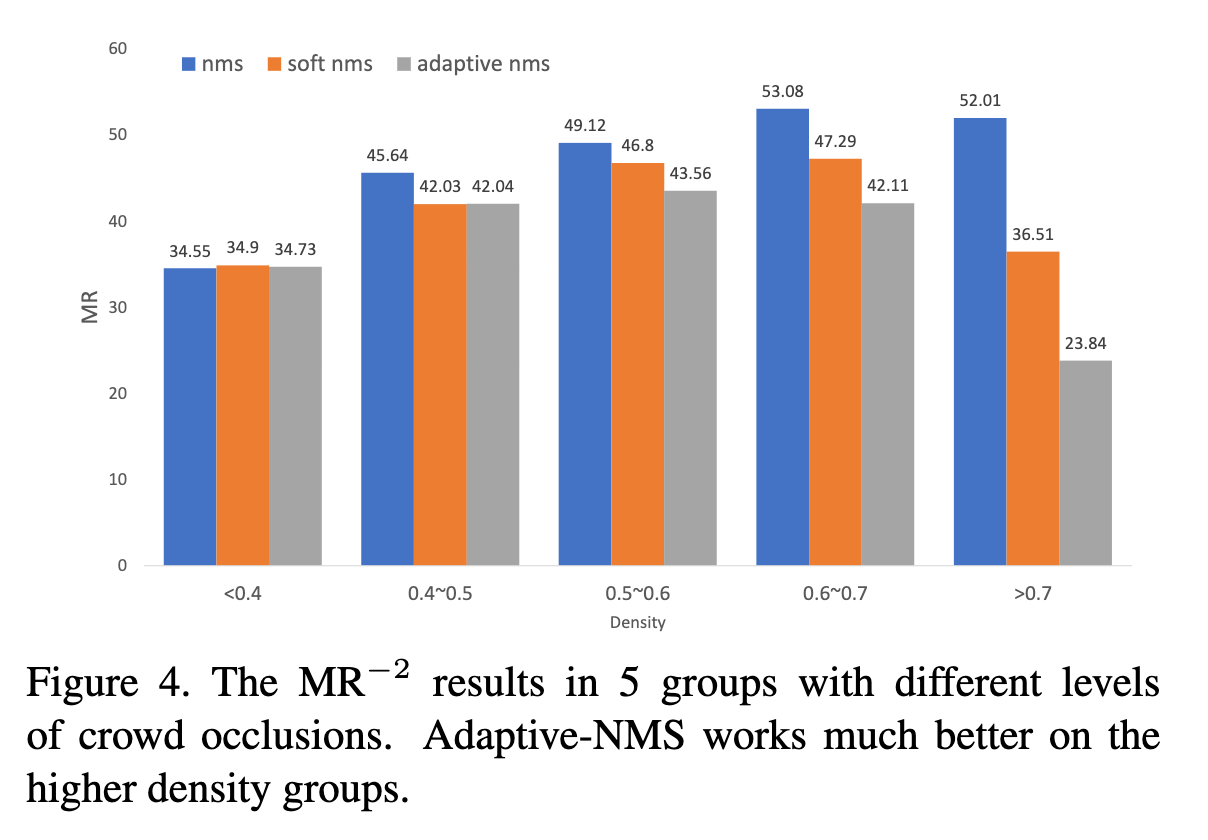
図2. 提案手法の混雑度ごとのMiss Rateの既存手法との比較 ([1]より転載)
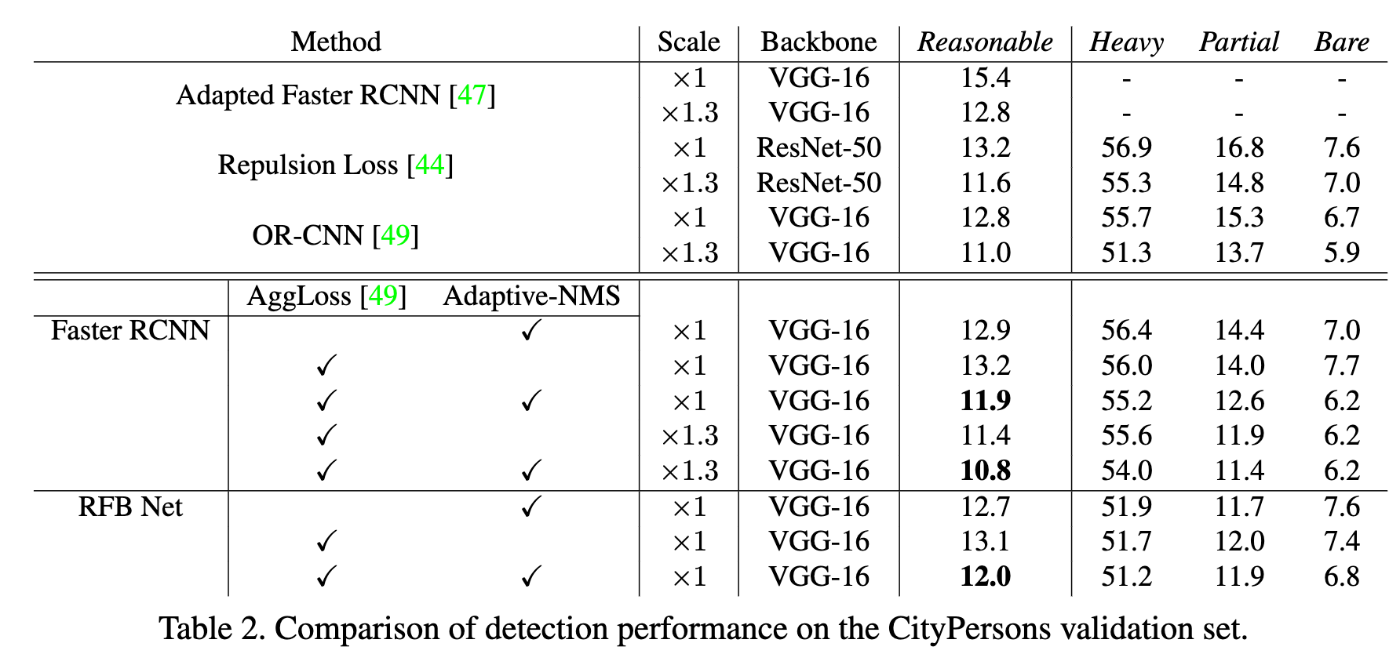
表1. GTサンプルのocclusionごとの既存手法と提案手法の性能比較 ([1]より転載)
AggLoss
予測boxの"まとまり"をよくする
PDタスクにおけるbox精度の改善手法として、AggLoss[5]という手法がある。
コンセプトとしては、GTに近いboxの集合がそのGT box周辺に"まとまった"状態にすることを目指したもので、以下のような補助的な損失(compact loss)を導入する。
表記について、
AggLossはGT boxに近い提案boxをグループとして捉え、それらを同じGTの座標に近づける、という意味を持つ[2]。
Variance Voting (Softer-NMS)
[2]はBox座標の予測に確率的な表現を導入した回帰手法とそれを利用したSoft-NMS[4]の変種のアルゴリズム(Variance Voting; Softer-NMS)を提案する。
この論文ではMS-COCOデータセットにおけるラベルに一貫性がないケース(図3)に着目し、ラベルの不確実性を反映した回帰手法を提案する。

図3. MS-COCOデータセットにおける非一貫的なラベルの例 ([2]より転載)
Boxの座標を確率的な表現でモデル化する
具体的にはラベルの確率分布をGauss分布と仮定して以下のようにモデル化する。
表記について、
本手法は一般的なpoint回帰手法に用いられる確率的表現とは異なり、Gauss分布のパラメータ自体をNeural Networkにより回帰する。すなわち、Gauss分布の標準偏差
ラベルはGauss分布ではなく以下のようにpoint-wiseに与える。すなわち、上記のGauss分布において
損失関数にはKL divergence Lossを用いる。Delta関数(=one-hot表現)をラベルとした場合、KL divergence Lossは以下のようにL2 Lossに比例する項と
なお、上記の損失関数は
Variance Votingのアルゴリズムについて
次に、回帰予測のuncertainty (
基本的なコンセプトはuncertaintyの度合いに基づいてMCB周辺のboxの座標を補正するというものである[6]。
具体的には以下の式によりboxの座標を補正する。
上式における
Variance Votingの効果について
表2は異なるIoU thresholdのAPスコアに対して提案手法の効果を既存手法(NMS, Soft-NMS)と比較したものである。この表によれば、GTとの高い精度の回帰しか許容しないメトリクス(つまり
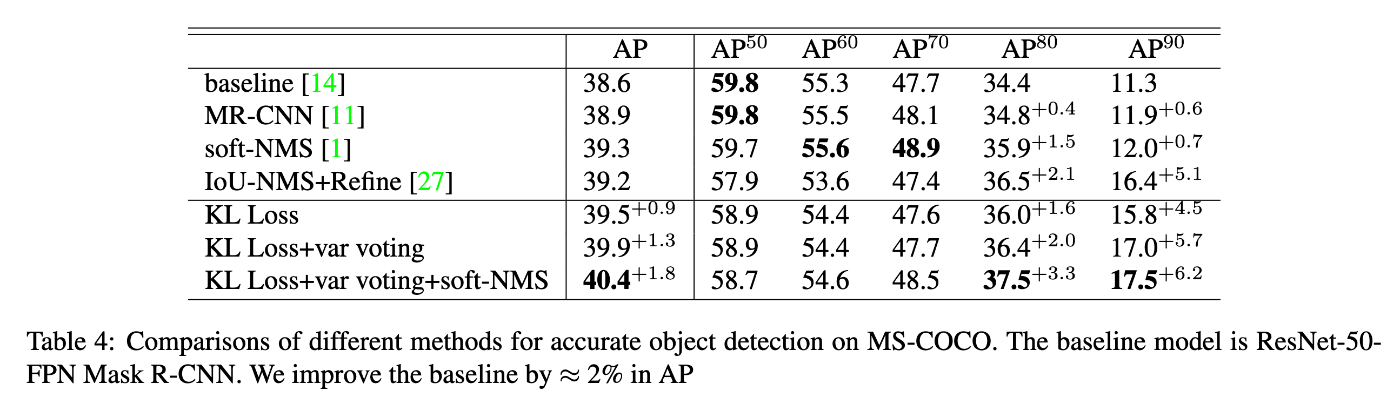
表2.IoU thresholdごとの提案手法の効果について ([2]より転載)
この結果によると、提案手法は高精度な回帰を実現するタスクに対してより効果的であることがわかる。
このような結果となった理由は個人的に以下のように考察している。
- 提案手法はone-hot表現によるラベルを与えているため、uncertaintyが高いサンプルに対してはよりシャープな予測が可能であるため、L2損失などと比べて高精度の予測ができる。
- 1の一方で、uncertaintyが低いサンプルに対してはよりぼやけた予測となり、lossへの寄与が小さくなるため、このようなサンプルによるnoiseの影響を抑えらえる。
- Variance Votingは、Boxの座標の回帰結果を周辺のboxのuncertaintyに応じて補正することができる。これは、一部の座標(例: top, left, etc.)のみ回帰精度は良いが、他の座標の回帰精度が悪いboxの回帰結果を平均することにより、すべての座標について精度の高いboxを生成しやすいためだと考えられる。
- また、提案手法はclassの予測精度とlocalityの予測精度を組み合わせた手法であるから、classの予測精度は高いがlocalityの予測精度は低いboxを過大に評価することを抑制する効果があり、結果としてclass予測精度とlocalityの予測精度が共に高いboxを残してそれ以外のboxを間引くことに成功しているためだと考えられる。
まとめ
本記事では、ODタスクにおけるpost-processing手法として、以下の3つの手法を紹介した。
- PDタスクにおいて、GT boxが混み合った領域で適切にFPを間引くために、GT boxの混雑度(density)をNNモデルにより回帰し、それに基づいて(Soft-)NMSにおけるIoU thresholdを動的に決定する手法[1]。
- モデルの予測boxの"まとまり"をよくするために、GT周辺の予測boxの座標の平均値をGTの座標に近づけるような補助的な損失関数を導入する手法[5]。
- Boxのラベルの座標が一貫しないサンプルの悪影響を緩和するために、box座標を確率的な表現でモデル化し、得られたbox座標予測のuncertaintyを利用してNMSにおいてclass予測の精度とbox回帰の精度をともに加味して間引く手法。また、Soft-NMSにおいてconfidenceの補正に加え、MCB周辺の提案boxの回帰結果を平均してすべての座標の回帰予測精度とクラス予測の回帰予測精度が共に高精度な予測boxを生成する手法[2]。
Reference
- [1] Adaptive NMS: Refining Pedestrian Detection in a Crowd, 2019
- [2] Bounding Box Regression with Uncertainty for Accurate Object Detection, 2019
- [4] Soft-NMS -- Improving Object Detection With One Line of Code, 2017
- [5] Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd, 2018
- [6] Fast R-CNN, 2015
-
この定義では2つのGT boxの重なりしか考慮していないが、3つ以上のGT boxからなる密度を反映するために、最大値でなくIoUの和で表現する定義も考えられる。 ↩︎
-
「予測boxをコンパクトにする」ことが目標なので、個人的には回帰boxの平均をGTと近づけるよりも、GT boxと重なりのある回帰boxの集合の座標の分散を0に近づける方が個人的には直感に合うと感じた。 ↩︎
-
なお、このような数学的な表現は主に解析目的のために導入されるものなので、実際にはGTの座標を表す点に確率1が割り当てられていることに注意。 ↩︎
-
直感的には指数関数のアクティベーション
e^x x -
推論時には
\sigma=e^{\alpha/2} -
周囲のboxのconfidenceを下げるだけでなく、周辺boxの座標を集約することでboxの座標も補正してしまおう、というのはWBF(Weighted Box Fusion)と似たような考え方である。 ↩︎
Discussion